GMA는 Supervised Learning에서 Sintel 데이터셋(Sintel-final, Sintel-clean) 모두에서 SOTA를 달성한 논문이다.

논문 링크 : https://arxiv.org/pdf/2104.02409v3.pdf
## Abstract
Occlusion(영상처리에서 겹침의 의미)은 Optical Flow 추정에서 중요한 문제이다. 따라서 GMA는 Occlusion point를 효율적으로 추정하는 방법에 대해 말한다.
본 논문에선, occlusion 문제를 해결하기 위해 이미지 자기 유사도 방법을 제시한다. 이는 transformer 기반의 모듈로 픽셀과 첫 프레임 간의 의존도를 찾고 대응되는 모션 feature 에 대해 global aggregation를 수행한다.
그래서 본 논문의 저자는 Sintel dataset에 대해 SOTA 달성했다고 한다.
## Introduction
본 논문의 저자는 occlusion 문제에 대해 집중하였다. 특히, 다음 프레임에서 보이지 않는 부분에 대해 추정하는 것이 많이 어려웠다고 한다. hidden motion에 대한 예시는 다음 그림의 오른쪽과 같고, 이에 대해 RAFT 모델과 GMA의 모델의 차이점을 보여준다.

만약 매칭 정보가 없을 때, 모션 정보는 다른 픽셀에서 전파되어야한다. 만약에 convolution을 사용한다면 local 작업이기 때문에 범위가 제한된다는 문제가 발생한다. 따라서 본 논문에선 비 로컬(non-local) 접근 방식으로 모션 기능을 통합할 것을 제안한다.
본 논문의 아키텍쳐 설계는 단일 객체의 움직임이 종종 동질적이라는 것을 가정하면서 만든 것이다. 각 픽셀에 대해 다른 픽셀과의 연관성 이해는 Optical Flow를 추정하기 위한 중요한 점이다.
occlusion 부분이 아닌 정보에서의 자기 유사도를 occlusion 포인트로 전파시켜서 예측을 수행한다. 이는 Transformer에서 영감을 얻었다고 한다.
GMA의 구조는 Tranformer에 기반하여 기준 프레임에서 자기 유사성에 기반한 Attention matrix를 계산하고, 다음 attention matrix를 사용하여 모션 기능을 합친다.
## Contribution
트랜스포머 메커니즘을 사용한 장거리 연결의 Optical Flow 추정을 하였고, 이는 특히 Local 정보가 부족한 occlusion pixel의 움직임을 해결하는데 큰 contribution이 있다. 또한, 참조 프레임의 자기 유사성이 장거리 연결을 선택하는데 중요한 단서를 제공한다는 점을 알아내었다.
## Proposed Architecture
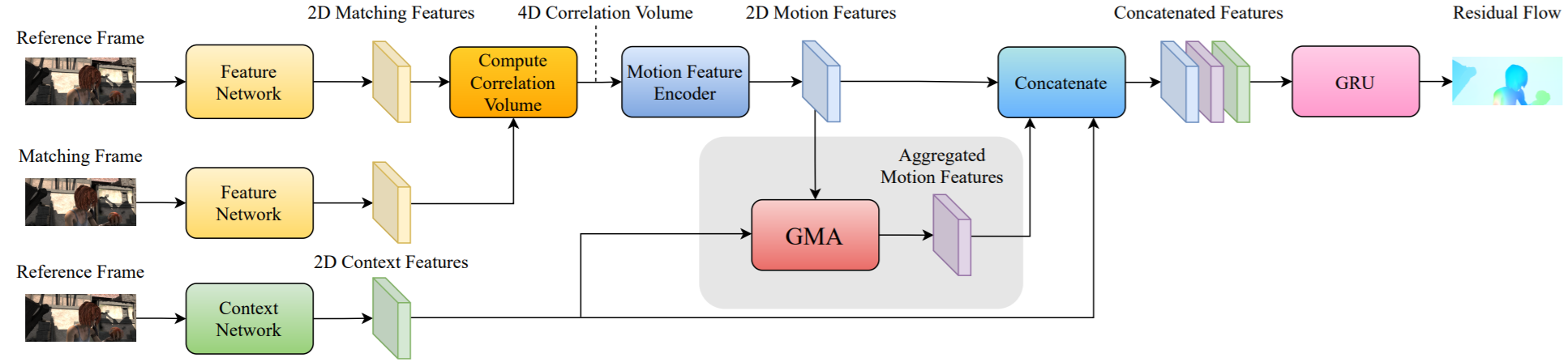
전체적으로 RAFT의 아키텍쳐 구조를 기반으로 한다.
RAFT에 대한 설명은
2021.07.23 - [논문 정리] - RAFT - Recurrent All-Pairs Field Transforms for Optical Flow
RAFT - Recurrent All-Pairs Field Transforms for Optical Flow
본 글은 https://www.youtube.com/watch?v=OnZIDatotZ4 이 동영상을 참고하여 작성하였습니다. RAFT는 ECCV2020에서 베스트 논문상을 받은 논문이다. Optical Flow와 Transformer를 결합하면서 SOTA를 달성한 논문..
bigdata-analyst.tistory.com
참고하면 된다.
본 논문의 저자는 RAFT의 장점을 다 갖고 왔다고 설명하면서 모든 쌍의 픽셀의 상관관계를 구할 수 있는 점과 큰 모션에 대한 상관관계를 구할 수 있는 점 때문에 차용했다고 말한다. 하지만 GRU Decoder 부분은 작은 occlusion을 다루는 것을 배울 수 있는 장점이 있지만 local evidence가 불충분할 때 실패하는 경향이 있다면서 RAFT의 단점을 언급하였다.
따라서 본 논문의 저자는 GMA를 도입하면서 이러한 문제를 해결할 수 있는 방법을 제안하였다.
기본 가정 : 네트워크가 참조 프레임에서 비슷한 모양의 포인트를 찾아 유사한 모션의 포인트를 찾을 수 있다.
이러한 가정은 단일 객체에 대한 점의 움직임이 종종 균일하다는 관찰에 의해 만들어졌다. 사람이 오른쪽으로 달리는 사람의 motion vector는 오른쪽으로 치우쳐져 있어서 가려지는 일치하는 프레임의 큰 부분이 보이지 않더라도 고정이 된다는 것에 기반한다.
따라서 본 논문의 저자는 통계적 경향을 기반으로 안가려진 픽셀에서 가려진 픽셀로 전파시킬 수 있다고 말한다.
이러한 아이디어로 transformer에 아이디어를 얻어 장거리 의존성 모델링을 할 수 있게 만들었다. 본 논문에선 self-attention 과 달리 일반화된 attention 모듈을 사용한다.

Query Projector 와 key projector는 프레임 1의 자체 유사성을 모델링 하기 위해 사용되는 context feature map의 투영이다. 그리고 value projector는 모션 feature의 투영으로 4D correlation volume의 encoding이다.
쿼리와 key feature를 내적하고 softmax 층을 거친 후 attnetion matrix로 모션의 숨겨진 값을 집계하는데 사용한다.
그리고 집계된 motion feature는 GRU에 의해 decoding 되는 context feature와 local motion feature와도 연결이 된다.
'논문 정리' 카테고리의 다른 글
| 저자가 직접 리뷰하는 YOLOv5 + Optical Flow 보행자 위험 예측 (0) | 2021.08.15 |
|---|---|
| Better Sign Language Translation with STMC-Transformer (0) | 2021.08.11 |
| RAFT - Recurrent All-Pairs Field Transforms for Optical Flow (0) | 2021.07.23 |
| MaskFlowNet : Asymmetric Feature Matching with Learnable Occlusion Mask (0) | 2021.07.23 |
| FlowNet : Learning Optical Flow with Convolutional Networks(Optical Flow~FlowNet2.0) (0) | 2021.07.21 |




댓글