Image Generation 정리 (2)
2022.06.19 - [논문 정리] - Image Generation 정리(1)
Image Generation 정리(1)
## GAN [NIPS 2015] https://bigdata-analyst.tistory.com/264?category=883085 Generative Adversarial Nets(GAN) 원 논문 arxiv.org/pdf/1406.2661.pdf 참고 자료 www.youtube.com/watch?v=AVvlDmhHgC4 나동빈님..
bigdata-analyst.tistory.com
## Least Squares Generative Adversarial Networks [ICCV 2017]
GAN의 loss function은 discriminator에서 sigmoid cross-entropy loss function 형태가 된다. 그러나 이는 gradient vanishing 문제를 야기한다. 따라서 이를 극복하기 위해 discriminator를 위한 least square loss function을 제안한다. LSGAN의 목적함수를 최소화하는 것이 Perason \( \chi^{2} \) divergence를 최소화하는 것이다. 따라서 LSGAN은 기존 GAN보다 더욱 좋은 성능을 낼 수 있고 안정적으로 학습한다.

위 식에서 notation은 다음과 같다. a와 b는 각각 fake data와 real data 의 label이다. c는 Generator가 D를 속이기 위한 값으로 정의한다. 여기서 a,b,c를 정의하기 위한 하나의 방법은 b-c = 1, b-a=2의 조건을 만족시키는 것이다. ( 이러한 조건을 따르는 이유는 논문 참고) 예를 들어 a = -1, b=1, c=0으로 셋팅을 한다면 다음과 같은 목적함수를 얻을 수 있다.

또 다른 방법은 b = c로 셋팅하여 생성하는 샘플들을 최대한 실제로 만드는 방법이다. binary로 하여 b=c = 1, a = 0로 설정한 식이다.


model의 architecture로 a는 generator이고 b는 discriminator이다. deconvolution layer를 통해 이미지를 생성하고 least squares loss를 통해 discriminator로 분류한다.
## Energy based Generative Adversarial Networks (EBGAN) [ICLR 2017]
https://arxiv.org/abs/1609.03126
Discriminator를 일종의 Energy function 관점으로 보는 논문이다. Energy function은 데이터를 받았을 때 해당 data manifold에 가까우면 낮은 값을 내놓고 data manifold에서 멀다면 높은 값을 내놓는 함수이다. 여기서 내놓는 값을 Energy라고 한다. 이러한 Energy function 역할을 하는 Discriminator를 구성하기 위해 MSE loss를 가지는 Auto Encoder 구조를 제안한다. ( real data에 가까우면 낮은 MSE를 내놓는 구조 )

Hinge Loss와 같은 모양인 Margin Loss를 사용한다. Generator의 Loss \( L_{G} (z) \)와 Discriminator의 loss \( L_{D} (x,z) \)는 위와 정의 되고 m은 양수인 Margin이다. 위 식에서 \( [\cdot]^{+} = max(0, \cdot) \) 이다. 위 loss는 각각 최소화해야되는 것이 목적인데 Discriminator는 Real sample에 최대한 낮은 에너지를 주어야하며 Generator가 만든 Fake sample에는 높은 에너지를 주어야한다. Generator는 자신이 만든 Fake sample이 낮은 Energy를 갖도록 훈련하게 된다.
EBGAN의 discriminator는 AutoEncoder 구조로 다음과 같은 Architecture를 가진다.

Discriminator function D(x)는 입력을 인코딩하고 디코딩하는 과정을 거쳐서 복원한 결과와 입력과의 Reconstruction Loss를 사용한다. 수식적으로는 \( D(x) = || Dec(Enc(x)) - x || \)로 나타내진다. AE 구조는 Energy-based 모델을 표현하기 위한 대표적인 방법으로 Reglarization term을 추가해서 훈련하면 supervised learning과 negative sample 없이도 에너지의 manifold를 구할 수 있다.
AE로 구조를 함으로써 real/fake를 구별하는 하나의 scalar 값을 내는 것 보다 더 많은 정보를 통해 판별할 수 있게된다. 이를 위해 복원 오차 기반의 방법은 discriminator에게 더 다양한 target을 제공할 수 있게 된다.

Regularizer 방법을 제안하여 mode collapse를 방지한다.
## BEGAN: Boundary Equilibrium Generative Adversarial Networks [2017]
https://arxiv.org/abs/1703.10717
BEGAN은 단순하지만 강력한 구조와 빠르고 안정적인 학습과 수렴이 가능한 GAN으로써 Discriminator와 Generator 사이의 균형을 조정해주는 equilibrium concept 정립. 이미지의 다양성과 퀄리티 사이의 trade-off를 조정하는 것이 가능한 새로운 방법을 정립한다. 또한, 수렴에 대한 approximate measure를 제안한다.
BEGAN은 EBGAN과 마찬가지로 Auto-Encoder 를 사용한다. 이러한 auto-encoder의 역할은 loss distribution을 맞추기 위한 의도이다. WGAN의 loss와 per-pixel euclidean distance도 사용한다.
BEGAN 은 loss distribution에 집중한다. pixel-wise loss 들이 서로 independent 하고 indentically distributed 라고 할 때, 중심극한정리에 따라 image-wise loss는 정규분포를 따른다고 근사할 수 있다.

BEGAN에선 \( \eta \)를 1로 L1 norm을 사용하여 AE로 복원된 이미지 사이의 loss를 계산하였다.
Wasserstein distance는 다음과 같이 표현이 된다.

여기서 Jenson 부등식을 사용하여 \( W_{1}(\mu_{1}, \mu_{2})\)에 대한 하한을 도출할 수 있다.

따라서 이를 통해 |m_{1} - m_{2}|만 optimize 해도 W를 optimize 하는데 충분하다.
BEGAN의 Objective function은 다음과 같다.

AE의 loss 사이의 식을 최대화 하기 위해 discriminator를 설계한다. x가 실제 샘플 \( \mu_{1} \)이 loss L(x)의 분포가 된다고 하자. 그리고 \( \mu_{2} \)는 L(G(z))의 분포가 된다고 하자.\( m_{1}, m_{2} \in \mathbb{R} \) 에서 \( | m_{1} - m_{2} | \)를 최대화하기 위한 방법은 두가지 밖에 없다.
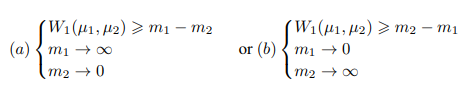
본 논문에선 m1을 최소화하는 방법을 선택하여 실제 이미지를 autoencoding 한다. discriminator와 generator의 파라미터 \( \theta_{D}, \theta_{G} \)가 주어졌을 때 loss \(L_{D} \)와 loss \(L_{G} \)를 최소화 하는 것에 각각 업데이트 되고 GAN의 목적함수로써 문제를 표현한다.
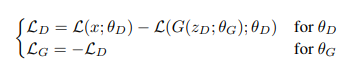
이 식은 WGAN과 비슷하지만 샘플들 사이가 아니라 loss 사이의 분포를 매치한다는 점과 Kantorovich와 Rubinstein duality 이론을 사용하지 않기 때문에 discriminator가 명백하게 K-Lipschitz가 되어야 함을 요구하지 않는다는 점이 다르다.
generator와 discriminator loss 사이의 균형을 유지하기 위해 equilibrium 개념을 도입하고 새로운 하이퍼파라미터 \( \gamma \in [0,1] \)를 통해 나타낸다.
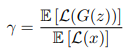
따라서 이 모든 것을 고려한 EBGAN의 objectvie function은 다음과 같다.
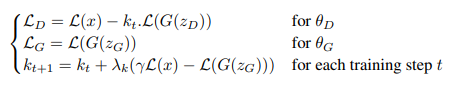
\( \mathbb{E}[L(G(z))] = \gamma \mathbb{E}[L(x)]\)의 평형을 유지하기 위해 Proportional control Theory를 사용한다. 이는 gradient descent를 하는 동안 \( L(g(z_{D})) \)를 강조하는지를 조절하는 변수 \( k_{t} \in [0,1]\)를 사용하여 구현된다.
BEGAN은 Convergence measure를 새롭게 정의한다. GAN의 수렴을 결정하는 것은 원래의 공식이 zero-sum 게임으로 정의되었기 때문에 일반적으로 어려운 일이다. 따라서, 하나의 loss는 올라가고 하나의 loss는 내려간다. epoch의 수와 visual insepction은 어떻게 학습이 진행되는지에 대한 개념을 얻기 위한 실용적인 방법이다. 따라서 본 논문에선 평형개념을 사용하여 수렴의 global measure를 유도한다. 따라서 propotion control 알고리즘 \( \gamma L(x) - L(G(z_{G}))| \)를 위한 동시에 일어나는 과정 에러의 가장 낮은 절대값과 가장 가까운 reconstruction L(x)를 찾음으로써 수렴과정을 볼 수 있다.
$$ M_{global} = L(x) + |\gamma{L(x)} - L(G(z_{G})) | $$
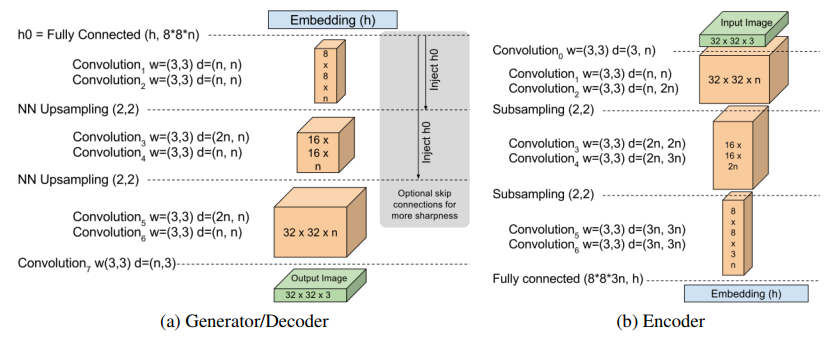
## Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks(CycleGAN) [ICCV 2017]
https://arxiv.org/abs/1703.10593
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks(CycleGAN)
원 논문 : arxiv.org/abs/1703.10593 Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks Image-to-image translation is a class of vision and graphics problems where the goa..
bigdata-analyst.tistory.com
Image to Image Translation 방법으로 Pix2pix 이후에 나온 논문이다. pix2pix와 다른 점은 train할 때 pixel마다 annoation이 없어도 된다는 점이다. 또한, pix2pix는 paried domain이 되어야하는데 cyclegan은 X domain과 Y domain이 unparied 해도 mapping하는 함수를 학습함으로써 unpaired image translation이 가능하다.
## StarGAN : Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation [CVPR 2018]
https://arxiv.org/abs/1711.09020
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for eve
arxiv.org
Stargan은 다중 도메인(이미지가 여러개인 상황)에서 효율적인 image-to-image translation 네트워크이다. 기존의 방법은 다중 도메인을 하기 위해선 여러 개의 network가 필요하였지만 Stargan은 오직 하나의 네트워크만 이용해서 다른 도메인으로 변환이 가능한 모델이다.
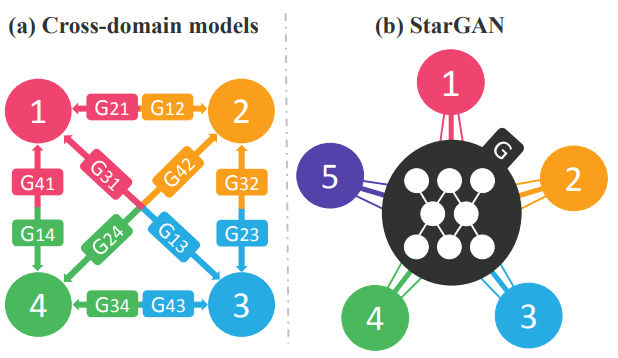
Stargan의 동작원리는 다음의 그림과 같다.
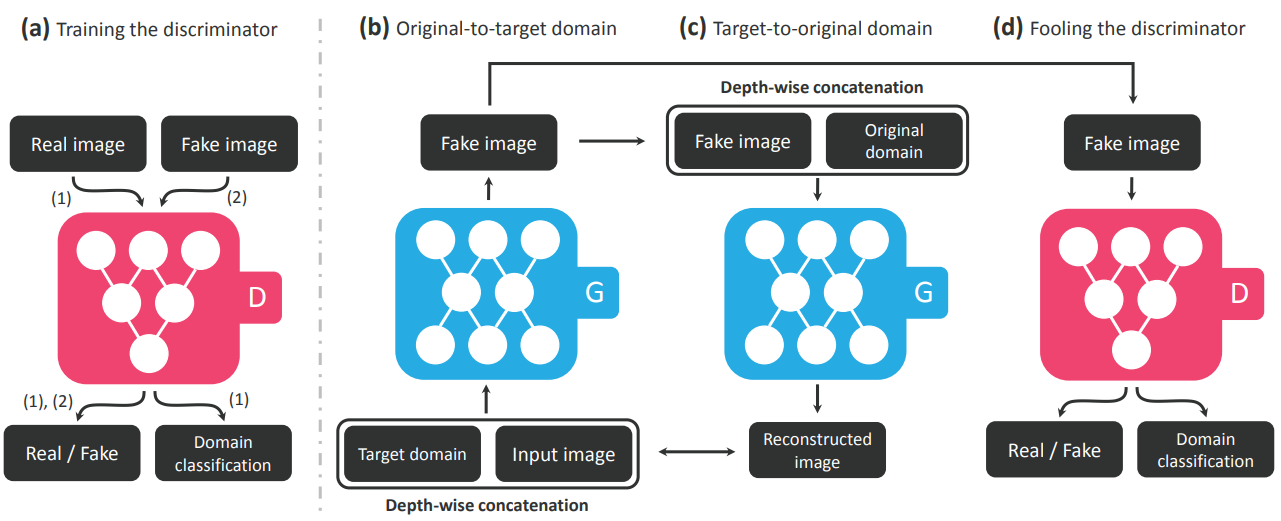
여기서 (a) disciminator 같은 경우는 cgan discriminator이다. 여기서 real image가 들어왔을 때 Real./ Fake 구분할 뿐만 아니라 domain 자체를 classification 하도록 구성한다. Generator (b)같은 경우 target domain의 vector값과 input image을 받아서 fake image를 생성한다. 여기서 생성한 fake image는 original domain과 함께 generator로 들어가서 reconstruced image를 생성한다. 이런 식으로 cycle loss로 만들어서 input image의 content는 유지한채 도메인 관련한 정보만 잘 반영하도록 만든다. (b)에서 생성한 fake image를 가지고 discriminator에 넣어서 real/fake와 domain classification을 이뤄낸다. 이를 통해 더욱 진짜같은 이미지를 만들 수 있게 한다.
따라서 Stargan은 loss를 3가지(Adversarial loss , domain classification loss, reconstruction loss)를 합쳐서 구성한다.
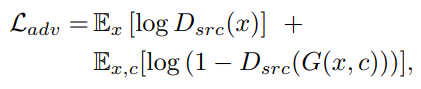
adversarial loss는 GAN의 loss와 비슷하게 구성이 되어있다. G는 real image로 분류될 수 있도록 학습하고 D는 fake image로 분류할 수 있게 학습을 진행한다.
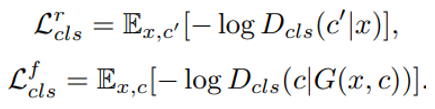
domain loss에서 c는 domain label 이라고 생각하면 된다. 여기서 fake image loss ( \( L^{f} \) )는 Generator를 위해 사용되는 것이고, image transfer가 된 이미지가 target class로 분류될 수 있는 형태로 학습을 진행한다. real image loss ( \( L^{r} \) )는 real image가 들어왔을 때 real image의 정상적인 domain class로 분류할 수 있은 형태로 학습을 진행한다.
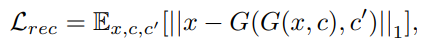
reonstruction loss는 L1 loss와 비슷한 형태로 generator가 만든 이미지가 원본 이미지와 얼마나 같은지에 대해 학습한다. 즉, reconstruction한 이미지와 실제 이미지와의 차이를 보는 것이다. 여기서 Generator 부분은 cyclegan의 cycle loss를 활용한다.
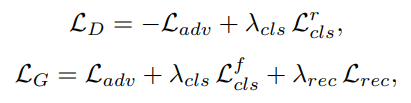
따라서 위 3가지 loss를 합친 최종적인 objective function을 구축한다. 여기서 \( L_{adv} \)는 추가로 wgan-gp에서 나왔던 gradient penalty를 이용하여 loss 값을 구성한다.
Stargan은 추가적으로 다양한 데이터셋에서부터 학습을 진행할 수 있다. 이를 위해 mask vector를 구성하여 mask 값을 입혀 어떠한 데이터셋을 사용할 것인지 명시한다.
## Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network(SRGAN) [CVPR 2017]
## Semantic Image Synthesis with Spatially-Adaptive Normalization (SPADE, GauGAN) [CVPR 2019]
https://arxiv.org/abs/1903.07291
## Spectral Normalization for Generative Adversarial Networks(SNGAN) [ICLR 2018]
https://arxiv.org/abs/1802.05957