import pandas as pd 로 시작하고 dataframe에 대해서 알아보겠다.
## DataFrame 생성
- 2차원 배열과 유사한 자료형
- 다차원 리스트, 딕셔너리 자료형으로 데이터 구성 가능
- 관계형 데이터베이스의 테이블 구조, excel/csv 데이터 구조와 유사
- 하나의 컬럼은 하나의 Series로서 Dataframe은 여러 개의 Series 묶음으로 구성됨
- index 특징
- row index(행 인덱스): 기본 숫자형 인덱스가 아닌 새롭게 지정한 로우명 (라벨) 인덱스를 사용해도 기본 숫자형 인덱스를 함께 사용할 수 있음
- column index(열 인덱스): 새롭게 컬럼명(라벨) 인덱스를 사용하면 기본 숫자형 인덱스는 사용할 수 없음
DataFrame을 생성해보겠다. DataFrame은 리스트 형식과 딕셔너리 형식 두가지 방법으로 생성할 수 있다.
data2=[[1,2,3,4,5,6],
[0.1,0.2,0.3],
['a','b','c','d']]
df2 = pd.DataFrame(data2)

df2에 대해서 알 수 있을 때 row 별 개수가 다름에도 불구하고 생성이 되고 개수가 맞지 않은 곳은 결측치로 값이 생성된다. 이는 리스트 타입으로 데이터 프레임을 생성했을 때만 가능하다. 하지만 딕셔너리 타입으로 생성했을 때에는 value의 길이가 같아야 된다.
dic1= {'a':[1,2,3],
'b':[10,20,30],
'c':[100,200,300]}
df3 = pd.DataFrame(dic1)
dic1 의 key값이 컬럼명으로 들어가서 dataframe이 생성이 된다.
index를 지정하기 위해선 DataFrame의 파라미터인 index 를 사용하고 column을 지정하기 위해선 column 파라미터를 이용하면 된다.
# 인덱스를 지정하여 객체 생성:
# 행 인덱스 : index 파라미터 => r1,r2,r3
# 열 인덱스 : columns 파라미터 => c1,c2,c3,c4
df5=pd.DataFrame(data1,index=['r1','r2','r3'],columns=['c1','c2','c3','c4'])
### DataFrame 속성
- 속성은 소괄호를 붙이지 않음
- index: df객체의 행 인덱스 배열을 반환
- columns: df객체의 열 인덱스 배열을 반환
- values: df객체의 데이터(값)를 아이템으로 가지는 2차원 배열을 반환
- dtypes: df객체의 데이터 타입을 열 기준으로 반환
- size: df 객체의 데이터 개수(길이)를 반환
- shape: df 객체의 구조(행,열)을 반환
- T : 행과 열을 전치시킴
DataFrame의 속성을 알아보기 위해 data를 생성하겠다.
# 딕셔너리 타입 데이터로 데이터프레임 생성
# 지역(서울 경기 충청 경상)별 2016,2017,2018년 유입 인구
data={'서울':[100,110,120],
'경기':[130,150,170],
'충청':[80,40,10],
'경상':[10,20,10]}
sample = pd.DataFrame(data)sample의 현재 인덱스는 0 1 2로 설정이 되어있다. 이 인덱스를 연도로 바꾸겠다.
sample.index=[2016,2017,2018]
sample
이 인덱스의 이름과 컬럼의 이름을 생성해보겠다.
sample.index.name='year'
sample.columns.name = 'city'
이제 샘플 데이터의 인덱스와 컬럼명을 수정하겠다.
# 행 인덱스 수정
sample.rename({2016:2015},inplace=True)
#열 이름 수정
sample.rename({'충청':'강원'},axis=1,inplace=True)
수정할 때 딕셔너리 순서는 {old:new} 순서로 한다. inplace=True 는 원래의 데이터에 적용을 한다는 것이고 만약 inplace=False로 하면 한 셀에서만 적용이 되고 원 데이터 sample은 훼손되지 않는다. 그리고 인덱스는 axis=0 즉 행, axis=1은 열을 가르키며 default 값은 axis=0 이어서 인덱스를 수정할 때는 axis설정을 따로 하지 않아도 된다.
# 기존 인덱스 삭제하기/리셋
# df.reset_index(): 기존 인덱스가 없어지고 RangeIndex가 생성
sample.reset_index()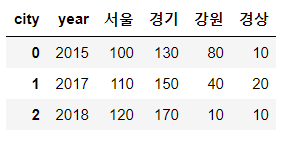
reset_index를 통해 인덱스가 새롭게 생성이 되고 기존의 인덱스인 year는 컬럼으로 들어가게 된다.
기존의 인덱스인 year를 없애려면 어떻게 할까? 방법은 drop=True 설정이다.
sample.reset_index(drop=True)
#dataframe 의 values
sample.values
#out
array([[100, 130, 80, 10],
[110, 150, 40, 20],
[120, 170, 10, 10]], dtype=int64)
# data type
sample.dtypes
#out
city
서울 int64
경기 int64
강원 int64
경상 int64
dtype: object
# 전체 튜플(셀) 개수: 행*열
sample.size
#out
12
# 행 개수
len(sample)
#out
3
#데이터 구조(행,열)
sample.shape
#out
(3,4)
# 행과 열을 전환
sample.T

하지만 원본은 유지 된다는 것을 꼭 알고 있어야 된다. 예를 들어 전치한 데이터를 계속 쓰고 싶다면 따로 변수를 설정해 저장하여야한다.
## 컬럼, 로우 추가
- 컬럼 추가/ 변경
- 컬럼 인덱싱 = 스칼라 값
- 컬럼 인덱싱= 배열, 리스트(로우 개수와 아이템 개수 일치)
- 컬럼 인덱싱 = 컬럼간의 연산
- 컬럼 인덱싱 = series
- 로우 추가
- 로우 인덱싱 = 스칼라 값
- 로우 인덱싱 = 로우 간의 연산
- 데이터 분석에서 컬럼과 로우의 의미
- 컬럼: 변수(특성)
- 로우: 개별 데이터(레코드)
- 전체 데이터를 구성하는 변수를 추가/삭제하는 일은 빈번하게 발생하지만 특정 인덱스를 기준으로 전체 로우 데이터를 추가/삭제하는 일은 자주 발생하지 않으며 데이터 처리를 하는 과정에서 권장하지 않는 작업
전라 [5,6,7]을 추가한 데이터 프레임 sample에서 작업을 해보겠다.
# 컬럼 추가 1 : 모든 로우에 대해서 동일한 값을 가지는 컬럼
# 전달하는 값 : 단일값(스칼라/scalar)
# 추가하려는 컬럼 : 제주
sample['제주']=1
sample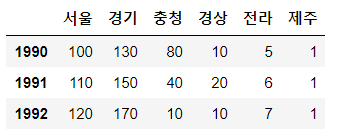
스칼라 값으로 추가를 하면 데이터 프레임에 스칼라값이 모두 추가가 된다.
# 컬럼 추가 2 : 행 값이 서로 다른 데이터를 가지는 컬럼 추가
# 사용할 수 있는 데이터 타입: 배열, 리스트
# 조건: 추가하려는 데이터프렘임의 행 길이와 일치
# 값: 1,2,3
# 컬럼: 부산
sample['부산']=[1,2,3]
sample
# 컬럼추가 3 : 컬럼 간의 연산
# 파생변수(유도변수)
# 수도권 컬럼: 서울 + 경기
sample['수도권']=sample['서울']+sample['경기']
sample
유도변수 생성은 가장 많이 쓰는 방법이므로 잘 알아두는 것이 좋다.
# 라벨 인덱스 : 1990,1992
# 값:-9,-99
s1=pd.Series([-9,-99],index=[1990,1992])
#out
1990 -9
1992 -99
dtype: int64
s2=pd.Series([100,100,100])
s2
sample['s1'] = s1
sample['s2'] = s2
시리즈의 컬럼 추가에는 value의 길이가 굳이 안맞아도 되고 인덱스가 일치해야지 (index,value)의 위치에 들어갈 수 있다는 것을 알 수 있다.
- 로우 추가
- 로우 인덱싱 = 스칼라 값
- 로우 인덱싱 = 로우 간의 연산
- 로우 인덱싱 = 자료형(배열,리스트/컬럼 개수와 아이템 개수 일치)
# 로우 추가 : 모든 컬럼에 대해서 동일한 값을 가지는 로우 추가
# 로우 인덱싱 = 스칼라값
sample.loc[1993]=0
# 배열, 리스트
# 컬럼 개수와 배열,리스트의 아이템 개수 일치
sample.loc[1995]=np.arange(10)
# 딕셔너리 : 컬럼마다 값을 지정해서 전달하는 경우
sample2=sample.loc[:,'서울':'충청'].copy()
sample2.loc[1994]={'서울':10,'경기':20,'충청':30}
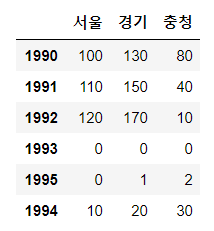
# 로우 간의 연산
# 라벨 'test'
# 더하려는 로우 : 1990+1991
sample2.loc['test']=sample2.loc[1990]+sample2.loc[1991]
## 로우 ,컬럼 삭제
- 컬럼 삭제
- del 키워드 + 컬럼 인덱싱
- df.drop(col,axis=1)
- df.drop(columns=col)
- 로우 삭제
- df.drop(idx): axis=0(기본값)
# 컬럼 삭제 1: del + 컬럼인덱싱
# 결과 원본에 그대로 반영
del sample['s2']
# 컬럼 삭제 2 df.drop(label,axis=1)
# 결과: 원본 반영 안됨
# inplace=True 원본 반영이 됨
# default 값은 inplace=False
sample.drop('s1',axis=1)# 로우 삭제
# df.drop(idx) : 기본 axis=0=> 행 인덱스를 참조
sample.drop(1995,inplace=True)# 두 개 이상의 로우/컬럼 삭제: 라벨 인덱스를 리스트로 묶어서 전달
sample.drop(['수도권','부산'],axis=1) # 컬럼 삭제
'Python > python 기초' 카테고리의 다른 글
| Pandas를 이용한 NC 다이노스 선수 분석 (0) | 2020.03.05 |
|---|---|
| Pandas - 3 (0) | 2020.02.23 |
| Pandas - 1 (0) | 2020.01.31 |
| Numpy - 6 (2) | 2020.01.22 |
| Numpy - 5 (0) | 2020.01.22 |
댓글