CVPR 2022 Open Access Repository
Signing at Scale: Learning to Co-Articulate Signs for Large-Scale Photo-Realistic Sign Language Production Ben Saunders, Necati Cihan Camgoz, Richard Bowden; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp
openaccess.thecvf.com
본 논문은 Sign Language Production task 에 관한 논문이다.
이 논문을 리뷰하기 전에 간단하게 단어에 대한 개념에 대한 정리를 하고 넘어가자.
## 용어 개념 정리
- Sign Language Production(SLP): Sign Language Production (SLP) is the automatically translation from spoken language sentences into sign language sequences. 즉, 구어(spoken language)가 있으면 이를 수화(sign language)로 바꿔주는 task이다.
- Gloss : Glosses are a written representation of sign that follow sign language ordering and grammar, defined as minimal lexical items. 즉, 수화 순서(문법)을 따르는 최소한의 단어들

## Introduction

수화는 시각적인 언어로 풍부한 단어와 동적인 움직임(손과 몸)과 정적인 움직임(표정)으로 이루어진다. 따라서 SLP는 이러한 feature들을 표현하기 위해 연속적인 photo-realistic 하게 표현해야하고 이는 청각장애인들과 소통하기 위해 많은 도메인을 포함할 수 있어야된다.
그러나 이전의 SLP 모델들은 수화 간의 자연스러운 co-articulation을 무시하거나 관절의 연속적인 순서를 무시하는 경향이 있었고, PHOENIX-Weather 2014 T dataset을 사용하여 학습을 하기 때문에 domain에 대한 한계가 존재하였다.
※ co-articulation : 동시 조음
한국어 구어의 동시조음 예시) "가방" 이라는 단어를 발음할 때, 자음-모음 순차적으로 "ㄱ" -> "ㅏ" -> "ㅂ" 이라고 입모양이 움직이는 것이 아니라 "ㄱ"을 발음하려고 입을 움직일 때, 동시에 입모양은 "ㅏ"나 "ㅂ"를 발음할 준비를 한다.
※ articulation : 조음 - 말소리를 뱉어내는데 사용되는 혀, 입천장, 이, 입술 등의 움직임
이러한 동시 조음 현상은 구어체 뿐만 아니라 수화에서도 관절의 움직임을 통해서 일어난다.
참고 문헌 : https://terms.naver.com/entry.naver?docId=271957&cid=41990&categoryId=41990
동시 조음
여러 개의 말소리 단위(예 : 음소)가 잇따라 조음되어 조음이 중첩되는 것. 실제로 ‘가방’ 이라고 말할 때 처음에 ‘ㄱ’ 을, 그다음 ‘ㅏ’ 를, 마지막으로 ‘ㅂ’ 을 조음하는 식으로 발음하
terms.naver.com
https://www.lifeprint.com/asl101/topics/coarticulation.htm
"coarticulation" American Sign Language (ASL)
Coarticulation Coarticulation has traditionally been spelled using a hyphen. For example, "co-articulation." It is common however for hyphenated words to lose their hyphen over time and with usage. For example "electronic mail" became E-mail, then e-mail
www.lifeprint.com
따라서 본 논문에서는 도메인이 제약되지 않은 구어에서 현실적인 수화 비디오를 생성하는 SLP 방법을 제안한다.
1. 구어를 gloss로 변환한다.
2. 수화의 시간적 흐름을 모델링하면서 gloss 기반 수화 사전 사이의 시간적 co-articulation을 학습한다.
본 논문에선 2번을 수행하기 위해 연속적인 수화의 순서를 잘 나타내는 최적의 frame을 학습하는 Frame Selection Network(FS-Net)을 제안하고, 이는 시간 순서 정보를 예측하기 위해 cross-attention이 있는 Trasnformer Encoder로 구축한다.
그리고 skeleton pose 순서들을 condition으로 주어 사실적인 비디오를 만들기 위한 SIGNGAN을 제안한다. SIGNGAN은 수화에서 빠르게 손이 움직여서 손 부분에 motion-blur가 생기는데 이를 회피하기 위해 keypoint 기반의 loss를 주어 손 이미지의 생성을 원활하게 한다.
본 논문에선 mDGS의 번역 프로토콜에 대해 청각 장애인들의 사용자 평가를 수행하여 기존 SLP 방법보다 좋다는 것을 증명하였고, RWTH-PHOENIX-Weather 2014 T 에서 SOTA 모델로 역번역(생성한 비디오를 text로 번역)하여 성능이 좋다는 것을 증명하였다. 그리고 생성한 수화 video에 대해 사용자 평가 및 정량적 평가를 수행하였다.
따라서 본 논문의 contribution은 다음과 같다.
- 여러 도메인(본 논문에선 unconstrained domain 이라고 표기)에서 실제 청각장애 수화자가 이해할 수 있을 정도의 대규모 수화 비디오(sequence)를 생성하는 최초의 SLP 모델 구축
- FS-NET을 이용하여 수화의 co-articulation 학습을 가능하게 함
- hand image 생성 능력을 향상시키는 hand keypoint loss를 도입한 SIGNGAN 제안
- 실제 유저들의 평가를 통해 제안된 방법에 대한 유저의 선호를 보여줌
## Related Work
- Sign Language Production
초기엔 수화 인식 (SLR)에 대해 초점을 맞춰서 연구가 되었고, 더욱 최근에는 수화 번역(SLT)에 관한 연구가 중점이 되고 있다. 수화 생성(SLP)은 기존엔 규칙 기반의 co-articulation을 가진 애니메이션 아바타를 이용하여 연구가 되었다. (딥러닝 사용 X) 반면 딥러닝을 사용하여 SLP를 이뤄낸 초기 모델들은 co-articulation을 고려하지 않고 각각의 독립된 articulation을 연결하는 것에 그쳤다. 또한, 최근 연속적인 SLP 방법은 여러 수화에 대한 회귀 sequence를 가지고 있지만 평균에 대한 회귀로 인해 articulation이 부족한 sign language motion 문제가 있다.
게다가 기존 연구는 skeleton pose sequence로만 표현을 하여서 실제 communication하는데에 문제가 있었고, photo-realistic하려 해도 low-resolution이라는 문제가 있었다.
- Pose-Conditional Human Synthesis
GAN을 통해 이미지를 생성하는 것과 최근엔 video-gan task가 생겼다. 그리고 pose를 condition으로 주어 전신과 얼굴 및 손 이미지 생성에 초점을 맞춘 연구가 있다.
그러나 full body가 있고 이에 따른 정확한 손 이미지 생성을 위한 것은 없고, 있어도 high-quality를 내지 못했다. 손은 fidelity(충실도..?)가 높은 물체이기 때문에 모델 최적화에서 간과된다. FaceGAN처럼 얼굴을 중심으로한 high-quality face generation 모델은 있지만, 수화에 중요한 손과 손이 interaction 하는 모델은 더 이상 연구되지 않았다. 그래서 본 연구에선 이러한 hand synthesis 를 높이는 방법을 제안한다.
Pose 자체로 손을 생성하는 것 뿐만 아니라 pose의 움직임을 생성하는 작업도 매우 SLP에서 중요한데 text 문장이 주어졌을 때 이러한 작업을 하는 연구는 거의 이뤄지지 않았다. 추가적으로 few-shot 방식으로 보이지 않은 것들을 생성하려는 연구가 있었지만 이는 단일 스타일만 계속 생성하는 문제점이 있었다.
- Sign Language Co-Articulation
먼저 수화에서의 co-articulation을 정의한다. co-articulation 이란 "the articulatory influence of one phonetic element on another across more than one intervening element" 으로 위에 설명한 것과 동일하게 하나의 음성적 요소(알파벳)가 두 개 이상의 중간 요소에 걸쳐서 다른 음성적 요소에 영향을 미치는 것이다.
sign language의 co-articulation은 수화의 움직임과 수화를 지속하는 시간에 영향을 미치는데 여기서 특히 수화 움직임 전환에 가장 큰 영향을 미친다. 수화를 구분하는 경계도 문맥에 따라 수정이 되며 연속적인 수화같은 경우 일반적으로 독립된 수화의 경계보다 더 빠르게 연장된다. 따라서 본 논문에선 isolated한 수화와 continuous한 수화의 sequence 간의 최적의 allignment를 학습하여 문맥에서 각 수화의 기간 및 경계 및 전환을 예측하여 시간적 co-articulation 모델을 구축한다.
2번째 문단 말은 어렵게 했지만 결국 연속적인 수화(co-articulation과 같은)와 isolated 수화(각각의 articulation이 있는)의 끝나는 지점이 다르기 때문에 이러한 관계를 잘 학습하여서 더욱 자연스러운 수화 생성을 하겠다라는 것.
## Large-Scale Photo-Realistic SLP
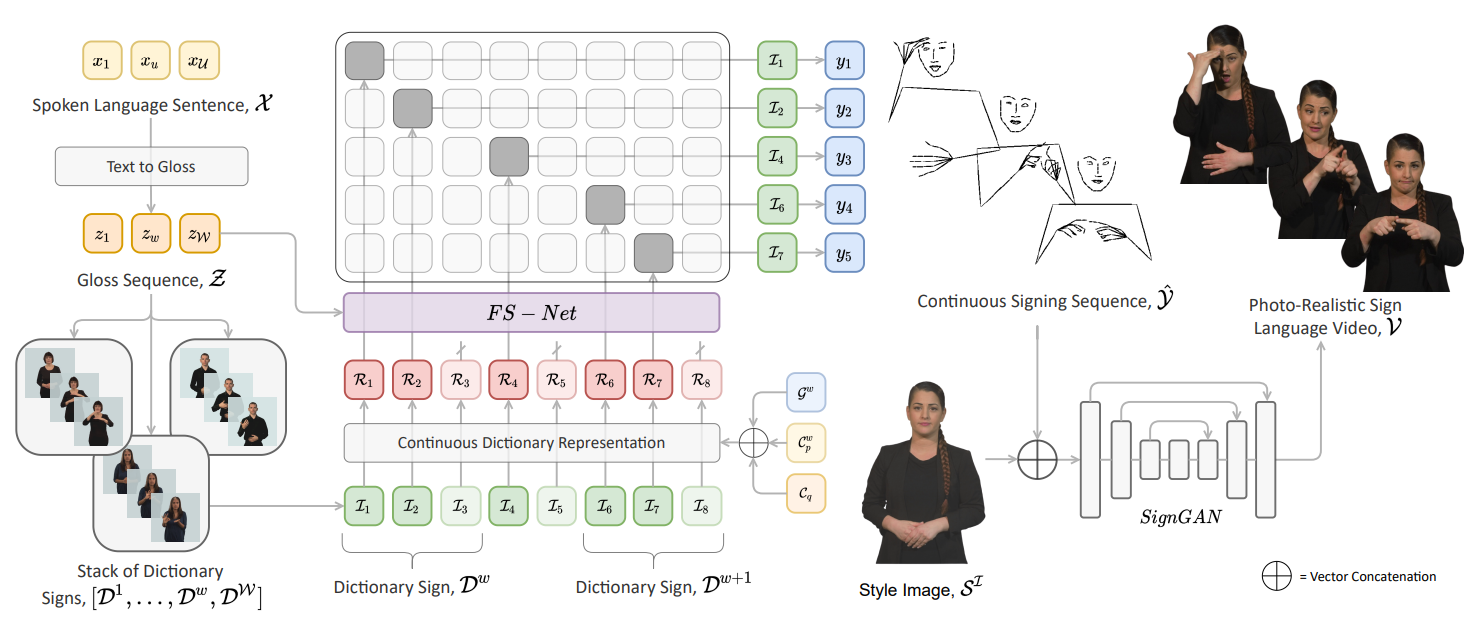
SLP의 중요한 목적은 구어의 순서를 제한되지 않은 도메인에서 단어들을 Sign Language Video로 만드는 것이다.
여기서 수학적인 notation을 보면 \( \mathcal{X} = (x_1, \cdots , x_{\mathcal{U}}) \)는 단어들의 집합을 의미한다. \( \mathcal{U}\)는 단어를 의미한다. 그리고 \( \mathcal{V}^{\mathcal{S}} = (v_1 , \cdots , v_T )\) 는 sign langauge video set을 의미하고 T는 비디오 프레임을 의미한다.
즉, SLP는 제한되지 않은 도메인의 단어 \( \mathcal{X} \) 를 수화 비디오 \( \mathcal{V}^{\mathcal{S}} \)를 만드는 것이다.
하지만 이는 수화의 어휘가 많고 복잡한 공간적 특성으로 인해 어려운 문제를 갖는다.
따라서 본 논문에서는 2 stage로 접근을 하여 첫번째 stage는 text를 gloss로 번역하여 gloss sequence \( \mathcal{Z} = (z_1, \cdots , z_{\mathcal W}) \)를 얻는다. 그 이후 두번째 stage는 FS-Net을 사용하여 완전한 연속적인 수화 sequence \( \mathcal{Y} = (y_1 , \cdots , y_T) \)를 생성하기 위해 gloss 기반 사전 수화 간을 연결한다. 그리고 이렇게 생성된 \( \mathcal{Y} \)인 sign sequence와 style image \( \mathcal{S}^{\mathcal{I}} \)를 이용하여 수화 비디오 \( \mathcal{Z}^{\mathcal{S}} \)를 생성한다.
### Text to Gloss
구어 \( \mathcal{X} \)가 주어졌을 때 수화 문법의 순서대로 만드는 gloss sequence \( \mathcal{Z} \)로 먼저 번역을 하는 과정을 거친다. 본 논문에선 이를 위해 transformer encoder-decdoer 모델을 사용하여 NMT task 처럼 번역을 진행한다.
### Gloss to Pose
본 논문에선 sign 과 gloss 간의 monotonic(단조로운) 관계에 아이디어를 얻어, 번역된 gloss sequence \( \mathcal{Z} \)에서 T 프레임을 가지는 연속적인 수화 sequence \( \mathcal{Y} \)를 생성한다.
본 논문에선 이를 위해 우선적으로 gloss sequence를 transformer encoder의 self-attention을 통해 encoding 한다. 이는 \( h_w = E_{G2S} (z_w | z_{1: \mathcal{W}} ) \)로 나타내진다. 여기서, \( h_w \)는 w 단계의 encoding된 gloss token 이다. 그 이후 gloss 단어에 해당하는 수화 dictionary sample \( \mathcal{D}^{\mathcal{W}} \)을 수집하여 dictionary sign 을 구성한다.
- Interpolated Dictionary Representation
번역된 gloss sequence가 주어졌을 때, dictionary sign \( [\mathcal{D}^1 , \cdots , \mathcal{D}^{w}, \mathcal{D}^\mathcal{W} ] \)을 순서대로 쌓아서 만든다.
기존 연구와 같이 프레임 마다 각각의 skeleton pose sequence \(\mathcal{D}^{w}= (s_{1}^{w}, \cdots, s_{\mathcal{P}^w}^{w} ) \) 로 dictionary를 표현한다. 그래서 본 논문에선 기존 방식을 사용하고 추가적으로 사전 정의된 고정 프레임 길이(\( N_{L_I} \))에 대해 인접한 수화 사이를 linear interpolation하여 stack한 dictionary sign 을 연속 sequence로 변환한다. 그리고 \( \mathcal{Q} \) 프레임을 가진 최종적인 interpolation sequence \( \mathcal{I} \)는 skeleton pose와 각각의 linear interpolation한 것의 결합이 된다.
그래서 이렇게 구축한 continuous dictionary sequence를 FS-NET에 input으로 넣어준다. FS-Net은 pose 정보를 담고 있는 \( \mathcal{I}\) 와 함께, 모든 interpolation frame인 \( \mathcal{G}^{LI}\)에 대해 별도의 공유 embedding을 사용하여 해당 단어에 대한 gloss에 해당하는 unique한 gloss를 embedding 한 값 \(\mathcal{G}^w \) 를 학습한다.
또한, 각 dictionary sign의 진행과 관련된 specific Counter \( \mathcal{G}_{p}^{w} \)와 전체 sequence \( \mathcal{I}\)와 관련된 global Counter \( C_q \)로 늘린 Counter Embedding을 사용한다.
※ counter embedding 이란? [0,1]의 범위를 가지고 현재 위치를 나타내주는 embedding.
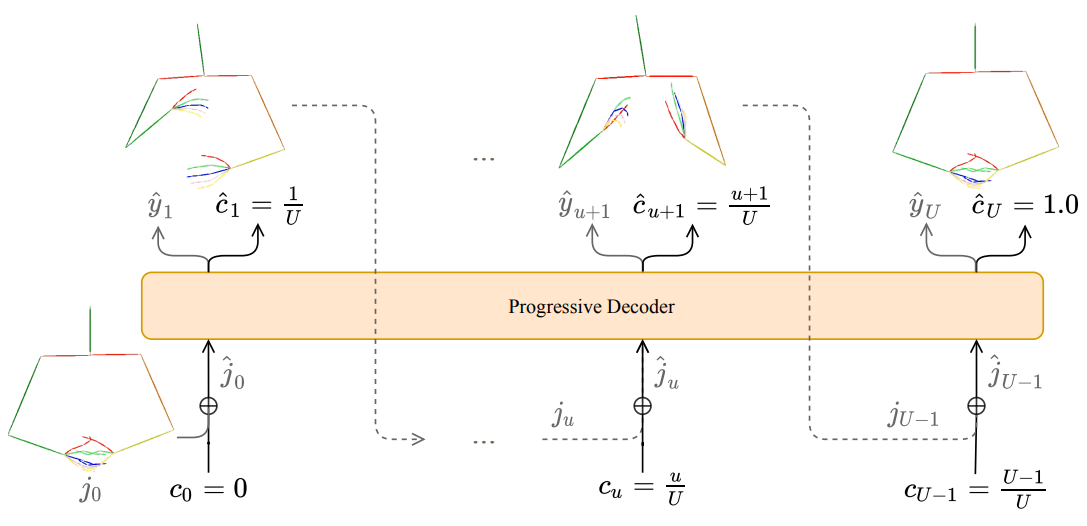
Ben Saunders, Necati Cihan Camgoz, and Richard Bow- ¨ den. Progressive Transformers for End-to-End Sign Language Production. In Proceedings of the European Conference on Computer Vision (ECCV), 2020.
따라서 최종적인 continuous dictionary의 표현은 Q frame을 가지는 \( \mathcal{R} = (\mathcal{R}_1 , \cdots , \mathcal{R}_{\mathcal{Q}}) \)로 표현이 되고 이는 skeleton + gloss + Counter Embedding(specific counter+global counter)가 된다. 여기서 +는 concat이다. 이를 식으로 정리하면
$$ \mathcal{R}_q = [ s_{p}^{w} , \mathcal{G}^{w}, \mathcal{C}_{p}^{w}, \mathcal{C}_q] $$
가 된다. 여기서 q는 gloss w로의 time step p frame을 말한다.
※ 정리
최종적으로 이 파트를 정리하자면 continuous dictionary \( \mathcal{R}\)를 표현하고자 하는 것이 목적이다. 이를 표현하기 위해 여러가지 정보를 합치는데 notation을 보면서 정리해보자.
- \( \mathcal{D} \): gloss별 수화 frame을 가진 Dictionary 집합 (gloss의 개수 \( \mathcal{W} \) 만큼의 길이를 가짐)
- \( \mathcal{D}^w \) : w라는 gloss 단어 하나에 대한 pose 정보를 가진 프레임의 집합 ( gloss에 해당하는 수화 frame의 길이 \( \mathcal{P}^w \)의 길이를 가짐)
- \( s_{\mathcal{P}^w}^{w} \) : \( \mathcal{D}^w \)에 포함되는 것으로 w라는 gloss 단어 하나에 대한 pose 정보를 가진 프레임 중 하나
- \( \mathcal{N}_{LI} \) : 미리 정의된 interpolation할 프레임의 길이 (transformer에 들어갈 때 단어별로 다 길이를 맞춰줘야하기 때문)
- \( \mathcal{I} \) : interpolated한 dictionary sequence (set) .
- \( \mathcal{Q} \) : 최종적인 dictionary의 길이= \( \mathcal{Q} = \mathcal{P}^{w} + \mathcal{N}_{LI} \), 하나의 gloss에 대한 interpolation 작업을 거친 수화 frame의 길이
- \( \mathcal{G}^{w} \) : w 라는 gloss 단어의 embedding 값. interpolation한 frame도 포함하여 embedding
- p : time step = gloss가 sign video frame으로 매핑되었을 때 나오는 frame의 개수
- q : gloss가 sign video frame으로 매핑되었을 때 나오는 frame의 마지막 번호, 전체 프레임에서 현재 위치
- example : I love you 라는 gloss 가 존재한다고 하자. 그리고 1~3 frame 까지는 I, 4~10 frame 까지는 love, 11~15 frame 까지는 you 라고 수화가 표현된다고 하자.
- 그럼 여기서 I 라는 gloss의 p = 3-1+1=3, q = 3 이 되고, love는 p = 10-4+1=7, q = 10, you는 p=15-11+1=5, q=15 가 됨
- \(\mathcal{C}_{p}^{w} \) : gloss w에 대한 time step p를 이용한 counter embedding, gloss에 해당하는 프레임 길이 기준의 counter == specific counter
- \( \mathcal{C}_q \) : q 번째 frame에 대한 counter embedding 값, 전체 frame 길이를 반영하는 counter == Global Counter
- \( \mathcal{R} \) : \( \mathcal{Q} \) frame의 길이를 가지는 최종적인 continuous dictionary 집합 = skeleton pose + gloss + specific counter + global counter
따라서 최종적인 continuous dictionary 는 다음 식과 같이 이뤄지고
$$ \mathcal{R}_q = [ s_{p}^{w} , \mathcal{G}^{w}, \mathcal{C}_{p}^{w}, \mathcal{C}_q] $$
이 식을 해석하면 q 번째 프레임의 dictionary는 w라는 gloss의 time-step p번째 pose값과 w라는 gloss 자체의 embedding 값과 gloss 단위의 counter embedding 값과 비디오 전체 길이의 counter embedding 값을 모두 concat 한 것이다.
- Frame Selection Network
dictionary sign 간 co-articulate를 위해서 T frame을 가지는 sign sequence에 대한 temporal alignment를 예측한다. 본 논문에선 이를 위해 Frame Selection Network(FS-Net)을 제안한다.
이는 앞서 표현한 continuous dictionary와 수화의 순서 자체는 일치하지만(gloss 기반으로 dictionary를 구성했기 때문에 당연) 생성할 프레임의 수와 dictionary의 길이가 달라서 단조로운 seq2seq 문제로 풀 수 있다. 즉, \( \mathcal{Q} \neq \mathcal{T} \) 라는 것이다.
FS-Net은 discrete sparse monotonic temporal alignment path를 예측한다. 이는 \( \mathcal{Q} \times \mathcal{Q} \)의 크기를 가지며 \( \hat{\mathcal{A}} \)라고 notation 한다.
$$ \hat{\mathcal{A}} = FS-Net(\mathcal{R}, h_{1:\mathcal{W}} ) $$
사실 이는 간단하게 \( \hat{\mathcal{A}} \)은 frame을 선택할건지 아님 그냥 넘길것인지의 binary한 결정을 하는 것이다.
예시 그림을 보면
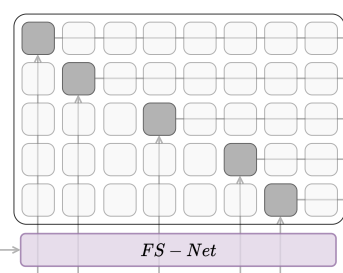
column이 frame의 수임을 알고 보면 3,5,8 frame은 skip을 하게 된다. 이는 즉, smooth한 co-articulation sequence를 frame skip을 하는 것이다.
FS-Net은 Transformer encoder 기반이고 여기에 추가적으로 cross-attention을 encoding된 gloss sequnence 에 적용시킨다. cross attention은 matrix multiplication으로 이뤄지며 다음의 식을 따른다.
$$ \hat{\mathcal{Y}} = \mathcal{I} \times \hat{\mathcal{A}} $$
여기서 \( \hat{\mathcal{Y}} \)는 co-articulated한 연속적인 sign pose sequence를 말한다.
이러한 frame selection을 통해 다양한 길이를 가진 sequence와 mapping이 가능하게 된다.
- Dynamic Time Warping Supervision
바로 FS-Net을 활용하여 \( \hat{\mathcal{A}} \)을 예측하게 되면 alignment의 희소성 때문에 gradient 가 약하게 전달이 된다. 따라서 본 논문에선 temporal alignment를 최적으로 학습하도록 설계한 DTW를 사용하여 FS-Net을 훈련시킨다.
interpolated dictionary sequence \( \mathcal{I} \)와 target continuous sequence \( \mathcal{y} \) 간의 최적의 DTW path \( \mathcal{A}^{*} = DTW(\mathcal{Q},\mathcal{T}) \)를 미리 계산해놓는다. 이 때, 2d alignment path는 예측을 하기가 어렵기 때문에 훈련을 하면서 2d를 1d로 축소시킨다. 1차원으로 축소를 시키는 과정은 \( \hat{\mathcal{A}} \in \mathbb{R}^{\mathcal{Q}} = argmax_{q} (\hat{\mathcal{A}}) \)로 한다. 이 식은 gloss 단위로 나눈 frame 중 frame 번호가 큰 값만 남겨 1차원으로 축소하는 것이다. 따라서 이러한 과정을 통해 dictionary sequence에 대한 temporal한 mask를 예측 가능하게 하고, continuous한 sequence를 생성하기 위해 interpolated 된 dictionary sequence를 차례로 선택한다.
※ DTW 참고 자료 : https://hamait.tistory.com/862
파이썬 코딩으로 말하는 데이터 분석 - 10. DTW (Dynamic time wrapping)
데이터 분석에 대한 기본적인 감과 덤으로 파이썬 코딩에 대한 감을 익히기 위한 강좌입니다. 개발자는 코드로 이해하는게 가장 빠른 길이며, 오래 기억하는 길이라 믿습니다. 순서 1. 통계 - 카
hamait.tistory.com
대부분의 경우 수화가 더 빠르기 때문에(\( \mathcal{Q} >> \mathcal{T} \) ) 시간 정렬 중에 frame의 추가는 없다라고 가정한다. 따라서 오직 frame을 제거하는 작업만 한다.
FS-Net을 훈련시키기 위해 이미 계산한 1d temporal alignment (\( \hat{\mathcal{A}} \) )와 실제 DTW alignment 간의 cross entropy loss를 사용하여 훈련한다. 따라서 이러한 작업을 통해 최종적신 continuous 한 수화 pose sequence \( \hat{\mathcal{Y}} \)이 생성된다.
### Pose to Video
실제와 같은 수화 비디오(\( \mathcal{V}^{\mathcal{S}} \))를 생성하기 위해 pose sequence \( \hat{\mathcal{Y}} \)을 컨디션으로 준다. 본 논문에선 이를 SIGNGAN 이라고 칭한다. Generator G와 multi-scale Discriminator \( D = (D_1 , D_2 , D_3) \) 구조를 가진 GAN을 설정한다. 본 논문에선 "Everybody Dance Now" 의 GAN 구조를 사용한다.
Everybody Dance Now : Chan, Caroline, et al. "Everybody dance now." Proceedings of the IEEE/CVF international conference on computer vision. 2019.
Generator G의 목적은 사람의 포즈 \( y_t \)와 style image \( \mathcal{S}^{I} \)가 주어졌을 때, 수화 이미지를 생성하는 것이다. Image-to-Image Translation GAN에 소개된 것처럼 U-NET 구조를 가진 GAN에 skip connection을 주어서 feature를 전달하는 방식을 채택한다. 본 논문에서는 pose 정보를 skip connection으로 전파하여 세부화된 정보를 생성할 수 있게 한다. 이 모델에 대한 디테일은 downsampling layer \(i\)와 upsampling layer \(n-i\) 사이에 skip connection을 주는 것이다.
Contollable Video Generation
다양한 수화데이터셋을 학습하기 위해 ANONYSIGN 접근법을 사용한다. ANONYSIGN 은 다음과 같은 아키텍쳐를 따른다.
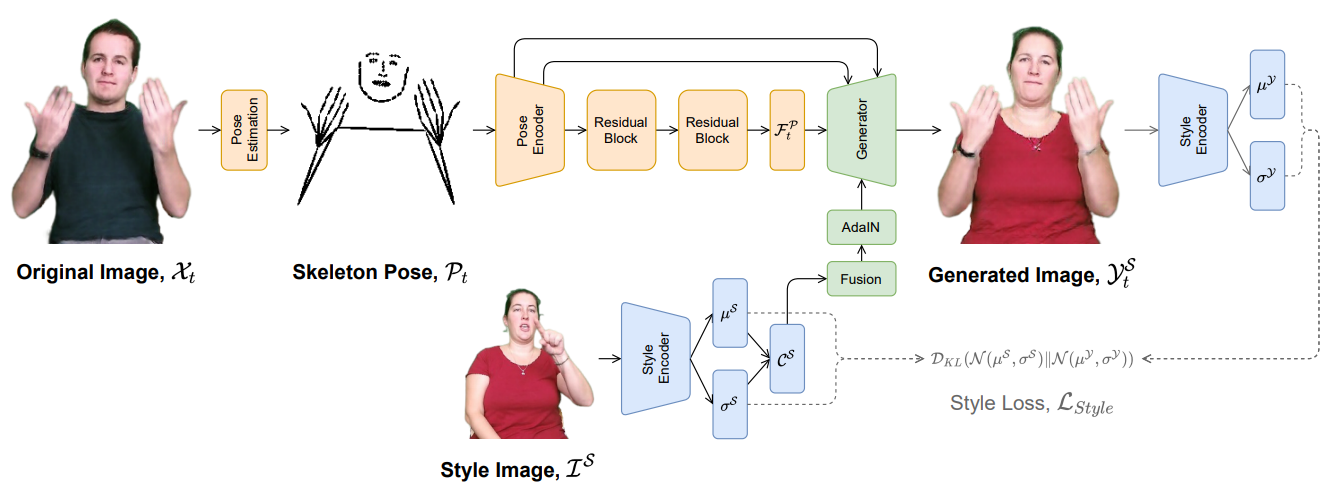
ANONYSIGN은 이미지가 input으로 들어가면 skeleton을 추출한 후 이를 Pose Encoder에 넣어 reconstruction한다. 이 때 동시에 style image 가 있으면 stylegan 처럼 style encoder에 넣어 style에 대한 distribution을 추출한다. 그리고 이러한 distribution을 Adain layer에 넣어서 Style Transfer를 한 수화 이미지를 생성한다. 그리고 이렇게 생성한 수화 이미지와 본래의 style image간의 KLD를 구해 style loss로 사용한다.
여튼, 이러한 방법을 사용하여 sign language video generation을 한다.
Hand Keypoint Loss이전의 Pose 를 condition으로 주어질 때, hand에 대한 이미지 생성은 잘하지 못했다. 본 논문에선 이러한 hand 생성을 하기 위해 keypoint 공간에서의 hand loss를 제안한다. pretrained 된 2d pose estimator를 이용하여 60x60 의 사이즈를 가지는 patch 이미지의 hand keypoint를 추출한다. 이 때, 이미지에서 motion blur가 된 이미지가 존재하기 때문에 이는 제거한다.이러한 hand keypoint loss는 discriminator에 넣어준다. Hand discriminator는 생성한 keypoint가 실제 keypoint인지 아닌지 구분할 수 있는 역할을 한다. 따라서 keypoint loss는 다음과 같은 식을 따른다.
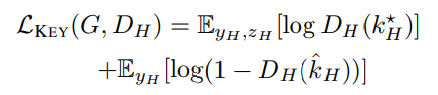
위 식의 notation을 보면 real hand keypoint는 \( k_{H}^{*} \)이고, 생성한 hand keypoint는 \( \hat{k}_H \)이다.
Full Objective
Vanilla GAN loss와 유사한 형태로 학습을 한다. 단, Style가 sign pose가 condition으로 들어가기 때문에 조건은 2개가 된다. 이에 대한 loss는 다음과 같다.

여기서 k=3 을 써서 3개의 discriminator를 사용한다는 것이다.
이렇게 GAN loss를 하고 추가적으로 discriminator의 feature matching 알고리즘 loss를 pix2pixHD 에 착안하여 쓰고, reconstruction loss는 Perceptual Reconstruction loss를 사용한다.
따라서 full objective function은 다음과 같다. 여기서 \( \mathcal{L}_{FM} \)은 feature matching을 의미하고, \( \mathcal{L}_{VGG}\)는 perceptual loss를 의미한다.

feature matching loss와 perceptual loss에 대해 간단히 설명을 덧붙이겠다.
feature matching loss는 각 layer 출력으로부터 계산하는 것으로 다음의 식과 같다.

여기서 s와 x는 각각 semantic label map과 natural image를 말한다. 그리고 \( D_{k}^{i} \)는 discriminator \( D_k \)의 i 번째 lyaer에서 출력한 feature를 의미한다. 그리고 T는 전체 layer의 수를 의미하고 \( N_i \)는 i 번째 layer에서 출력한 feature element 수를 의미한다.
이 식의 효과는 Discriminator의 출력을 maximize하는 것 대신에, generator가 실제 이미지의 통계값과 일치하는 이미지를 생성하도록 유도하는 것이다. 즉, generator가 discriminator의 각 layer에서 실제 이미지를 보고 출력하는 feature 들을 보고, 가짜 이미지도 discriminator의 각 layer에서 동일한 값을 출력할 수 있도록 학습하게 한다라는 것이다. 이로써 generator가 더욱 진짜 같은 이미지를 생성할 수 있게 된다.
Perceptual loss는 feature mathcing loss와 약간의 비슷한 개념을 갖는다고도 할 수 있다. VGG에 real 이미지를 input 값을 통과시킨 것과 생성한 값을 VGG에 통과 시켜 각 feature map 간의 L1 loss를 구하는 것이다.
## Experiments
### Experiments Setup
mDGS dataset으로 SLP를 위해 훈련을 시키고., 번역을 위한 corpus를 조정하기 위해 자유로운 담론 문장들을 gloss로 번역하여 수화 데이터셋을 구축하였다.
본 논문에선 mDGS gloss 들을 두가지로 나눴는데, 하나는 gloss 변형이 포함된 mDGS-V이고, 또 하나는 변형이 아니라 제거된 mDGS 이다.
추가적인 실험을 위해서 PHOENIX dataset을 사용하였다. 그리고 철저하게 dictionary의 sign 예시들을 수집하여 시작 수화와 끝나는 수화를 제거하였다. (자체 데이터셋 구축) 이 중, 얼굴의 표현력이 없는 샘플들의 경우에는 gloss에 있는 특징들을 삽입하여 구성하였다.
그리고 photo-realism을 위하여 C4A dataset을 사용하였다.
Text to Gloss를 위해선 Transformer Encoder를 2 layer에 4 head, hidden size 128로 하고, FS-Net은 2 layer 에 4 head, 64 hidden size로 한다. 그리고 interpolation frame은 5로 설정하고, learning rate 는 0.001로 설정하였다.
### Quantitative Evaluation
Text to Gloss
Text를 Gloss로 번역을 하는 과정이다. 평가지표는 NMT 평가지표인 BLEU로 한다.

Gloss to Pose - Back Translation
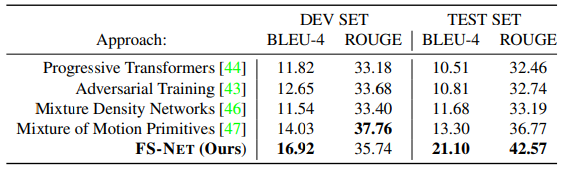
Back Translation은 기존에 제안된 SLP 평가 방법을 이용한다. 기존 방법은 Progressive Transformer 이다. 이는 기존에 잘 훈련된 SLT 모델을 이용해서 SLP로 생성된 skeleton을 역번역하는 방식이다.
따라서 이러한 평가방식으로 기존에 제안되었던 방법에 비해 우수함을 보여주었다.

여기서 interpolated dictionary sequence가 더 안좋은 결과가 초래되어서 FS-Net이 co-articulation을 잘 반영했음을 알 수 있다.
추가적으로 Gloss에서 Pose 까지가 아닌 Text에서 Pose로의 평가를 하여 실험해보았다.
Gloss to Pose - Sign User Evaluation
수화 비디오를 평가하기 위해서 실제 deaf people에게 평가를 하게 하였다. Gloss to Pose에 대해선 다른 모델을 쓰고, animating을 하는 것은 동일하게 SIGNGAN을 적용하였다.
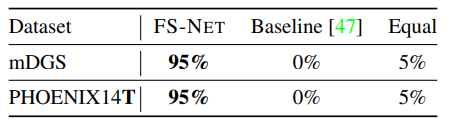
두 모델을 비교하여 어떤 것이 더 좋은 수화 비디오인지를 나타내는 과정으로 FS-Net과 Mixed SIGNALs와 둘 중 어떤 영상이 더 나은지를 비교하는 것이다.
다음으로 large-scale sign production이 분리된 상태에서 얼마나 이해할 수 있는지를 평가한다. 각 참가자에게 10개의 수화 목록과 함께 제작된 비디오를 보여주고 그 중 5개가 비디오에 수화가 있다고 생각되는 production을 고르라고 하였다. 이를 통해서 Co-articulation을 얼마나 잘 반영하고 있는지에 대한 평가를 할 수 있게 되었다.

Pose to Video
SIGNGAN에 대해 평가를 한다. 총 평가는 4가지로 SSIM , Hand SSIM, Hand Pose(L1 loss) , FID 이렇게 4가지를 평가한다.
Baseline Comparision
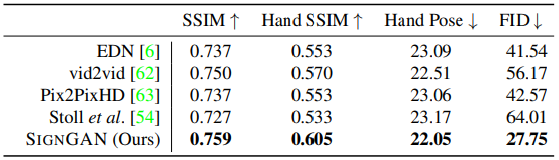
기존 SoTA 모델에 비해 모두 우수한 성능이 나타났음을 증명한다.
Ablation Study
기존 모델과 비교 뿐만 아니라 Hand 에 대한 처리를 하는 방법에 대한 비교를 한다.

여기서 Baseline은 Hand를 넣지 않았을 때이고, Discriminator는 Hand loss 추가가 아닌 Hand도 discriminator에 나오게 하여 하는 방법이고, 마지막으로 본 논문의 제안 방법인 Hand Keypoint loss는 Hand loss를 추가하는 방법이다.
이 결과 loss를 추가하는 것이 가장 좋은 방법으로 본 논문에서 선택한 방법이 가장 좋은 방법임을 입증하였다.
## Conclusion
Large-scale의 실제와 같은 SLP를 하는 것인 deaf community에 매우 중요한 것이다. 따라서 본 논문에선 large-scale과 photo realistic하게 수화 비디오를 생성하는 방법을 제안한다. 또한, FS-Net을 제안하여 co-articulation을 학습할 수 있게 되었다.
그리고 본 논문의 접근 방식은 제한되지 않은 도메인으로 확장하여 상당한 역번역 성능을 보여주었다. 추가적으로 실제 deaf signer들에게 평가를 맡겨서 기존의 baseline을 뛰어넘는 것을 보여주었다.
본 연구에선 현재 대규모 도메인에서 text to gloss 번역에 대한 한계가 있다. 사용 가능한 gloss annotation이 제한되어 있어서 수화 번역 작업이 resource가 부족하기 때문이다.
추후 연구에선 dictionary sign 사이의 공간적인 co-articulation에 대해 다룰 예정이다.
'논문 정리' 카테고리의 다른 글
| Denoising Diffusion Probabilistic Models(DDPM) (1) | 2022.11.08 |
|---|---|
| Zero-shot Learning (2) | 2022.09.05 |
| Taming Transformers for High Resolution Image Synthesis (VQGAN) (0) | 2022.07.28 |
| Attention is all you need (0) | 2022.07.12 |
| Image Generation 정리 (2) (0) | 2022.06.23 |




댓글