
갑자기 심심해서 즉흥적으로 한 프로젝트 입니다..ㅎㅎ
인생한방 복권당첨을 노리며 복권분석을 해보겠습니다!
사실 복권분석은 난수이고 독립시행이기 때문에 분석이 의미가 없지만 인생은 확률 게임이라는 마음가짐을 갖고 해보겠습니다!
일단 복권 데이터를 불러와야죠. 복권 데이터는 쉽게 https://dhlottery.co.kr/gameResult.do method=byWin&wiselog=H_C_1_1
로또6/45 - 회차별 당첨번호
905회 당첨결과 (2020년 04월 04일 추첨) 당첨번호 3 4 16 27 38 40 905회 순위별 등위별 총 당첨금액, 당첨게임 수, 1게임당 당첨금액, 당첨기준, 비고 안내 순위 등위별 총 당첨금액 당첨게임 수 1게임당 당첨금액 당첨기준 비고 1등 21,125,037,752원 7 3,017,862,536원 당첨번호 6개 숫자일치 1등 자동4 수동3 2등 3,520,839,630원 77 45,725,190원 당첨번호 5개 숫자일치+보너스 숫자일치
dhlottery.co.kr
주소에서 얻을 수 있습니다!
위 링크에 대해서 데이터를 얻으려면 우선 웹 크롤링이라는 기술을 사용해야됩니다.
python에서 이를 위해 구현된 패키지가 있습니다.
import bs4
from urlib.request import urlopen이는 웹크롤링을 효과적으로 하기 위한 패키지입니다.
다음으로 웹페이지를 불러옵니다! 불러오기 전에 어떠한 규칙이 있는지 한번 살펴봅시다.
https://dhlottery.co.kr/gameResult.do?method=byWin&drwNo=1 이는 1회차 당첨번호의 주소 입니다!
https://dhlottery.co.kr/gameResult.do?method=byWin&drwNo=2 이는 2회차 당첨번호의 주소 입니다!
눈치 빠르신 분들은 예상했겠지만 맨 뒤에 No의 숫자만 바꾸면 1회차 사이트 2회차 사이트의 데이터 값을 불러올 수 있습니다.
page_n = 1 # 변수로 저장하여 변화하기 쉽게 설정한다.
idx = 'https://dhlottery.co.kr/gameResult.do?method=byWin&drwNo='+str(page_n) # 1회차 페이지 주소
이를 바로 urlopen(idx).read() 를 한번 실행시켜 봐볼까요?
urlopen(idx).read()
OMG...진짜 뭔소린지 하나도 모르겠습니다! 물론 웹페이지 제작에 경험이 있는 사람한테는 보일 수 있는
<!DOCTYPE html>이나 여러가지가 보입니다. 엔터처리 키인 \r가 너무 많아서 보기 힘듭니다..이걸 어떻게 이쁘게 처리 할 수 있을까요? 그래서 설치한 패키지가 bs4 입니다! bs4에 있는 이뻐져라 함수가 있는데 그걸 한번 사용해서 주소를 읽어보겠습니다.
source = urlopen(idx).read()
source= bs4.BeautifulSoup(source,'html.parser') # 'lxml.parser'도 가능
print(source.prettify())bs4.BeautifulSoup(source,'lxml.parser') 도 가능한데 추가 설치가 필요하므로 저는 'html.parser'를 이용하겠습니다. lxml.parser는 속도가 빠른 반면 추가 설치의 단점이 있습니다. 빠른 성능을 하시려면 lxml를 따로 설치하시고 하면 됩니다!

아까 urlopen을 사용했을 때 보다 훨~~~씬 깔끔한 결과화면을 볼 수 있습니다!
여기서 저희가 원하는 데이터는 당첨번호가 가장 중요한 것이죠! 당첨번호는 <meta>쪽에 'content'로 써져 있습니다.
그 부분을 한 번 불러오겠습니다.
sentence = source.find("meta", {"name":"description"}).get('content')
# source.head.find("meta", {"name":"description"}).get('content') 도 가능(더 정확)수 많은 <meta> 가 있는데 그 중 name이 description인 데이터를 찾아 content를 불러오는 것 입니다.
주석 표시로 source.head도 가능하다고 했는데 이는 <head>쪽에 메타 블록이 있기 때문에 더 정확한 표시를 하기 위해서 한 것 입니다!
sentence의 결과는 '동행복권 1회 당첨번호 10,23,29,33,37,40+16. 1등 총 0명, 1인당 당첨금액 0원.' 라고 문자열이 추출되었습니다! 위 문장에서 저희가 얻고 싶은 것은 숫자입니다. 숫자를 추출 한번 해보겠습니다.
tmp = sentence.split('당첨번호')[1].split('.')[0].lstrip().split(',')
# ['10', '23', '29', '33', '37', '40+16']
last = tmp[-1].split('+') # '40+16'에서 +로 나눈 다음에 저장
# ['40','16']이제 tmp와 last를 합쳐보겠습니다.
tmp.remove(tmp[-1])
tmp.append(last[0])
tmp.append(last[1])
tmp
# ['10', '23', '29', '33', '37', '40', '16']이제 원하는 번호를 다 추출했습니다!
이제 모든 데이터를 다 불러오기 위해 마지막 날짜 추출하는 법을 알아보겠습니다!
사실 홈페이지 데이터는 볼 수 있는 방법이 있습니다. 바로 오른쪽 마우스를 누르고 페이지 소스 검사를 누르면 됩니다!
그러면 view-source:https://dhlottery.co.kr/gameResult.do?method=byWin&drwNo=2
로또6/45 - 회차별 당첨번호
2회 당첨결과 (2002년 12월 14일 추첨) 당첨번호 9 13 21 25 32 42 2회 순위별 등위별 총 당첨금액, 당첨게임 수, 1게임당 당첨금액, 당첨기준, 비고 안내 순위 등위별 총 당첨금액 당첨게임 수 1게임당 당첨금액 당첨기준 비고 1등 2,002,006,800원 1 2,002,006,800원 당첨번호 6개 숫자일치 2등 189,733,600원 2 94,866,800원 당첨번호 5개 숫자일치+보너스 숫자일치 3등 189,726,000원 10
dhlottery.co.kr

위와 같이 나옵니다. 이 페이지 소스를 설명한 이유는 여기서 기본적으로 찾은 뒤 코딩을 하면 훨씬 편합니다!
ctrl+f를 누른 후 '회차 바로가기' 를 찾으면
위와 같은 숫자가 쭉 나옵니다! 우리는 가장 최근의 회차를 불러오면 됩니다. 항상 사이트 측에서 회차를 업데이트 해주니까 가장 위에 있는 회차만 불러오면 우리는 업데이트된 데이터를 가져다 쓸 수 있는거죠!
한 번 코드로 구현해보겠습니다.
# 마지막 날짜 추출
# <select id="dwrNoList" title="회차 선택">
x=str(source.find('select',{'id':'dwrNoList'}).find('option'))
# '<option>905</option>'
x= x.split('>')[1].split('<')[0]
x= int(x)
x
# 905우리는 id가 dwrNoList인 것을 불러왔습니다! 처음 불러왔을 때 option까지 딸려와서 split 하는 작업이 필요하였습니다. 더 좋은 코드를 알고 계시는 분은 댓글로 남겨주시면 감사하겠습니다ㅠㅠ
우리는 이제 최근 숫자 업데이트까지 완성을 했습니다! 이제 하나부터 끝까지 긁는 작업을 해야됩니다. for문이나 재귀함수 호출로 돌리는 방법이 있습니다. 재귀함수가 성능이 더 좋아서 재귀함수로 하려 했지만 사실...너무 귀찮아서...for문 돌렸습니다...함수 만드는건 약간 제 체질이 아닌가봐요.. 중간에 헷갈리더라구요..ㅎㅎ 암튼 그래서 for문으로 돌렸습니다!
그 동안 했던 코드들을 합치겠습니다. 그리고 우리는 보너스 숫자까지 합친 7개의 숫자를 각각 저장하고 list형식의 모음을 컬럼을 따로 해서 저장하겠습니다!
adress = 'https://dhlottery.co.kr/gameResult.do?method=byWin&drwNo='+str(1)
# 업데이트 되기 때문에 어느 숫자든 상관없다.
source = urlopen(adress).read()
source= bs4.BeautifulSoup(source,'html.parser')
last_page=str(source.find('select',{'id':'dwrNoList'}).find('option'))
last_page= last_page.split('>')[1].split('<')[0]
last_page= int(last_page)
lotto=pd.DataFrame() # 각각의 value 저장
dic={} # list를 저장하기 위한 임시 변수
for page_n in range(1,last_page+1):
adress = 'https://dhlottery.co.kr/gameResult.do?method=byWin&drwNo='+str(page_n)
source = urlopen(adress).read()
source= bs4.BeautifulSoup(source,'html.parser')
sentense = source.head.find("meta", {"name":"description"}).get('content')
number = sentense.split('당첨번호')[1].split('.')[0].lstrip().split(',')
last = number[-1].split('+')
number.remove(number[-1])
number.append(last[0])
number.append(last[1])
lotto['{}회'.format(page_n)]=number
dic['{}회'.format(page_n)] = number
lotto=lotto.T
x= pd.DataFrame(pd.Series(dic,index=dic.keys()))
x.rename(columns = {0 : 'list'}, inplace = True)
lotto = pd.concat([lotto,x],axis=1,join='outer')
lotto.head()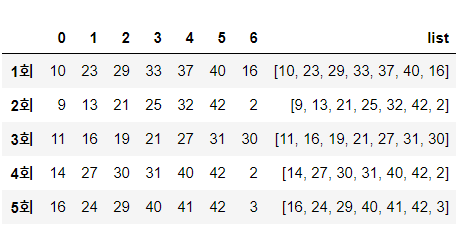
데이터는 다 적재되었습니다. 그런데 제가 깜빡하고 문자열로 넣었네요..바로 수정해보겠습니다.
for i in lotto.columns.difference(['list']):
lotto[i] = lotto[i].astype(int)lotto['list'] = lotto['list'].apply(lambda x: list(map(int,x)))이제 분석하기 편하게 dataset이 설정되었습니다. 분석 방법은 아주 간단합니다. 모델을 쓰지 않고 그 숫자의 확률이 얼마나 나왔는질 알아보겠습니다.
from collections import Counter
tmp=[]
for i in range(7):
for j in range(lotto.shape[0]):
tmp.append(lotto[i][j])
count = Counter(tmp)
tmp 리스트에 lotto의 각 번호를 저장한 다음 그 리스트의 각 값들을 Counter 함수를 통하여 세는 것입니다. 결과값은 dictionary형태로 나오게 됩니다.

이를 df 라는 새로운 dataframe을 생성하여 개수와 총 확률을 구해보겠습니다.
df = pd.DataFrame(pd.Series(count,index=count.keys())).sort_values(by=0,ascending=False)
df['count'] = df[0]/lotto.shape[0]*100
df = df.reset_index()dataframe에 index를 count의 key값 즉 각 번호로 설정하고 번호가 많이 나온 순서대로 정렬을 하였습니다. 또한, df에 각 로또 번호의 확률을 계산하여 'count' 컬럼에 넣었습니다. 글구 reset_index()를 통해 번호를 컬럼으로 삽입하였습니다.

시각화를 하면
plt.figure(figsize=(20,12))
sns.barplot(data=df,x='index',y='count')
plt.title("Probability of All Number")
plt.xticks(fontsize=20,rotation=60)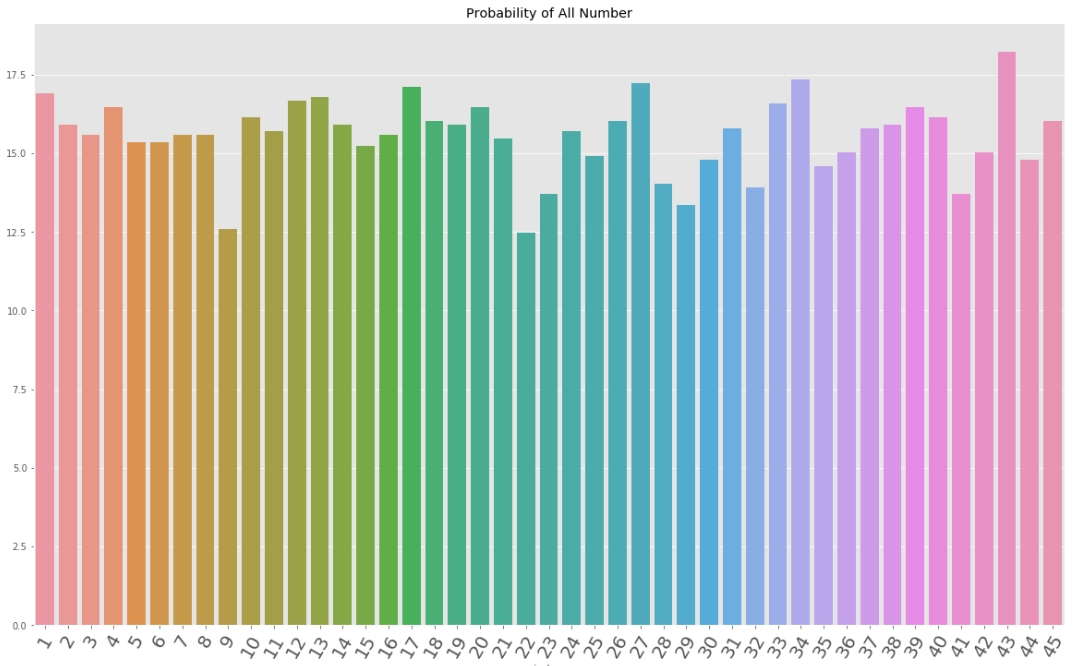
plt.figure(figsize=(12,8))
sns.barplot(x=df.head(10)['index'],y=df.head(10)['count'])
plt.title('Top 10')
지금 보니 barh로 하는게 뭔가 나을 것 같다는 생각이 드네요
그래서 즉흥적으로 한 번 해보겠습니다.
plt.figure(figsize=(20,12))
sns.barplot(data=df,y='index',x='count',orient='h')
plt.title("Probability of All Number")
plt.xticks(fontsize=20,rotation=60)
plt.yticks(fontsize=15)
처음의 barplot과 차이점은 orient='h' 의 옵션을 추가했다는 것입니다! 그리고 x축과 y축의 들어갈 값도 바꿔야 합니다.
이상으로 심심풀이 복권 분석을 마치겠습니다. 각 숫자별 확률은 계산하였지만 이는 단순히 확률일 뿐이고 나머지 숫자들과 큰 차이가 없으니 정말 심심풀이로 보시길 바랍니다. 처음에도 언급했듯이 난수이고 독립시행이기 때문에 의미 없는 분석임을 다시 한 번 강조드립니다. 이 결과를 맹신하지 마세요!(모델을 안돌리는 이유도 이에 있음)
자세한 코드는 https://github.com/winston1214 -> Star와 팔로우 해주시면 감사하겠습니다.
winston1214/baseline_ML
ML을 위한 기초 공부. Contribute to winston1214/baseline_ML development by creating an account on GitHub.
github.com
'심심풀이 project' 카테고리의 다른 글
| 회귀 알고리즘을 이용한 주가분석 -2 (0) | 2020.05.17 |
|---|---|
| 회귀 알고리즘을 이용한 주가분석-1 (0) | 2020.05.17 |


댓글