2019년에 레포트로 제출했던 매우매우 간단한 주가 분석을 소개하겠습니다..!
KOSPI200 과 K10의 회귀식을 도출하는 프로젝트를 진행해보겠습니다.
'''
1. 서론
- 연구의 목적 및 필요성
핀테크(FINTECH) 기술이 발전하면서 투자에 대한 수요가 빠르게 급증하고 있다. 또한 바이오 산업이 급성장하면서 많은 사람들이 너도 나도 할 것 없이 주식 투자에 많은 관심을 갖고 있다. 그래서 다양한 주식 투자 분석을 행하는 사람이 늘고 있는 추세이다. 하지만 주식 분석이란 매우 변수가 많고 다양해 쉽게 주가를 예측 할 수 없는 한계점이 있다. 따라서 필자는 대표적인 대한민국의 주식 KOSPI200(상위 종목 200개)와 상위 종목 10개 주식인 K10의 영향도를 분석하여 주식 시장의 흐름을 간단하게 알아보고자 한다.
이러한 분석을 하기 위해 KDD 분석 절차(Knowledge Discovery in Database)를 따라서 분석 하고자 한다. KDD분석 방법론은 기술과 데이터베이스를 중심으로 한 Insight를 발견하기 위한 분석 방법론이다. 이 분석 방법은 데이터 선택, 데이터 전처리, 데이터 변환, 데이터 마이닝, 데이터 평가 순으로 5가지 절차로 이뤄져 있다.
이 때 데이터 수집은 Ipython의 Jupyter NoteBook을 이용해 BeautifulSoup 패키지를 사용하여 웹 크롤링을 하여 데이터를 수집하고 R을 이용하여 선형회귀분석 모델을 통해 얼마나 큰 영향을 미치는지 수치로써 나타내고, 회귀식의 가정에 대해 만족하는지 알아볼 것이다.
'''
제가 적은 레포트의 서론 입니다. 이 프로젝트의 전반적인 진행 절차에 대해서 잘 표현한 것 같아서 가져왔습니다. 그리고 가장 중요한 참고 문헌은 김용환 퀀트님의 "파이썬을 활용한 금융공학 레시피: 문과생의 코딩 울렁증과 이과생의 금융 울렁증을 한 방에 씻어줄 금융공학 사이다" 입니다! 제가 경제학과이기 때문에 관심 있어서 샀는데 정말 설명을 잘해주시고 제가 크롤링을 배운 것도 이 책 덕분이라고 할 수 있습니다.
파이썬을 활용한 금융공학 레시피
저자_ 김용환 SK C&C에서 프로그래머로 사회생활을 시작했으나 금융권에 있는 친구들이 더 우아하게 살면서도 높은 연봉을 받는다는 사실에 분개해 한국거래소로 이직, 지금까지 15년 이상 금융��
books.google.co.kr
협찬 아니고 정말 추천 드립니다!(협찬 좀 받았으면 좋겠습니다..) 설명도 자세하고 코드를 깃허브로 제공하기 때문에 오류가 있으면 바로바로 수정 가능 합니다!
지금부터 프로젝트(?)를 시작하겠습니다.
주가 데이터는 실시간으로 변하기 때문에 실시간에 따른 데이터 수집이 필요합니다. 따라서 한국은행 통계사이트에 나와있는 주가 데이터를 사용하지 않고 웹 크롤링을 통해 수집해야 됩니다.(물론 실시간은 아니고 그 전날까지의 종가 데이터를 수집합니다.) 네이버 금융 홈페이지에 있는 KOSPI200 지수를 불러오려 합니다. 이를 위해선 전 프로젝트 복권 분석에서 사용한 BeautifulSoup와 urllib 패키지를 사용합니다.
index_cd='KPI200'
page_n=1
naver_index='https://finance.naver.com/sise/sise_index_day.nhn?code='+index_cd+'&page='+str(page_n) #1장 주소
source = urlopen(naver_index).read() #url 열기
source = bs4.BeautifulSoup(source,'html.parser')
print(source.prettify()) # 보기 편하게 출력
불러온 후 우리가 원하는 데이터를 수집해야한다. 우리가 원하는 것은 그 종목의 해당 날짜이다. 이를 위해선
https://finance.naver.com/sise/sise_index.nhn?code=KPI200
코스피 : 네이버 금융
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
finance.naver.com
위 사이트에서 일별 시세 부분을 봐야한다. (우리는 종가만 본다.) 일별 시세 테이블 부분에 오른쪽 마우스를 누르고 검사를 누르면 오른쪽에 html로 작성된 무엇인가 쭉 뜬다. 그리고 다음 사진과 같은 방법으로 진행하면 된다.
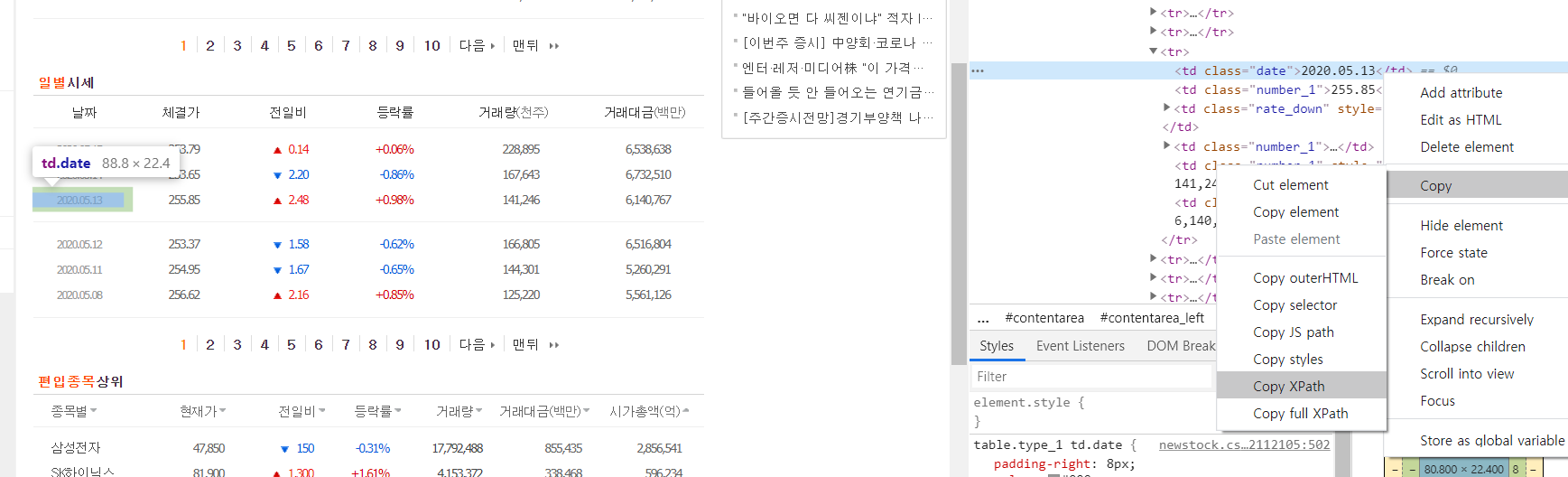
html의 XPath를 copy하고 붙여넣기 하면 /html/body/div/table[1]/tbody/tr[3]/td[1] 이런 식으로 나올 것이다. 우리는 source에서 이 부분을 찾아내서 날짜만 추출해야 된다. 이 때, XPath는 1부터 시작이므로 0부터 시작하는 python에 맞추려면 -1씩 해줘야한다.
# /html/body/div/table[1]/tbody/tr[3]/td[1]
source.find_all('table')[0].find_all('tr')[2].find_all('td')[0]
#out
# <td class="date">2020.05.15</td>이런 식으로 작성하면 된다! 나는 2020.05.15 만 추출하고 싶으므로 하나의 코드를 더 작성한다.
d=source.find_all('td',class_='date')[0].text #td class이름이 있을때
d
#out
# '2020.05.15'이제 날짜 추출이 가능해졌다! 하지만 type은 string type 이므로 python에 알맞는 날짜형식으로 바꿔야한다. 따라서 datetime 을 사용하여 함수를 만든다.
import datetime as dt
def date_format(d): #python 에 맞는 날짜 형식으로 바꾸기
d=str(d).replace('-','.')
yyyy=int(d.split('.')[0])
mm=int(d.split('.')[1])
dd=int(d.split('.')[2])
this_date=dt.date(yyyy,mm,dd)
return this_date
date_format('2020.05.15')
# out
# datetime.date(2020, 5, 15)위와 같은 방식으로 나타내는 함수를 구현한다.
날짜를 추출한 방식으로 똑같이 종가를 추출한다.
# /html/body/div/table[1]/tbody/tr[3]/td[2]
this_close = source.find_all('table')[0].find_all('tr')[2].find_all('td')[1].text # 종가 받아오는(table 생략 가능)
this_close=this_close.replace(',','') #쉼표 제거 -> 1000이상 넘어갈때
this_close=float(this_close)이를 일반화 시킨다.
dates=source.find_all('td',class_='date')
prices=source.find_all('td',class_='number_1')class의 이름을 통해 일반화를 시킨 것이다. 이 변수들을 한 번 뽑아보자.
# 한페이지 날짜 및 종가 뽑기
for n in range(len(dates)):
this_date = dates[n].text
this_date= date_format(this_date)
this_close=prices[n*4].text # 종가만 추출 - > 종가는 4의 배수에 있음
this_close = this_close.replace(',','')
this_close=float(this_close)
print(this_date,this_close)
2019년 11월 4일에 마지막으로 이 함수를 실행했으므로 이러한 결과값이 나온다. 최근에 다시 실행하면 최근 것이 나올 것이다.
이제 페이지 맨 마지막까지 추출하는 코드를 알아보자.
paging=source.find('td',class_='pgRR').find('a')['href']
paging
# out
# '/sise/sise_index_day.nhn?code=KPI200&page=570'
내가 원하는 값은 page=이후 570이라는 값이므로 (시간이 지날 수록 늘어남) 이를 추출 하는 코드를 짜야된다.
paging=paging.split('&')[1].split('=')[1] # 맨 마지막 숫자까지 추출
last_page=int(paging)
last_page
# out
570
이제 위와 같은 코드를 일반화 시켜 언제든지 추출할 수 있는 함수를 짜보자
from urllib.request import urlopen
import bs4
def historical_index_naver(index_cd,start_date='',end_date='',page_n=1,last_page=0): #날짜 지정하면 그 날의 종가 지수 출력(kospi)
if start_date:
start_date=date_format(start_date) #date포맷으로 변환
else:
start_date=dt.date.today() #없으면 오늘로 지정
if end_date:
end_date=date_format(end_date)
else:
end_date=dt.date.today()
naver_index='https://finance.naver.com/sise/sise_index_day.nhn?code='+index_cd+'&page='+str(page_n)
source=urlopen(naver_index).read() #지정한 페이지에서 코드 읽기
source=bs4.BeautifulSoup(source,'html.parser') #뷰티풀 수프로 태그별로 코드 분류
dates=source.find_all('td',class_='date') #<td class='date'>태그에서 날짜 수집
prices=source.find_all('td',class_='number_1') #<td class='number_1'>태그에서 종가 수집
for n in range(len(dates)): #dates 개수만큼 반복
if dates[n].text.split('.')[0].isdigit(): # 날짜가 숫자형이면
#날짜처리
this_date=dates[n].text
this_date=date_format(this_date)
if this_date<= end_date and this_date>=start_date: #start_date 와 end_date 사이에서 데이터 처리
#종가처리
this_close=prices[n*4].text
this_close=this_close.replace(',','')
this_close=float(this_close)
#딕셔너리에 저장
historical_prices[this_date]=this_close
elif this_date<start_date:
return historical_prices
#페이지 네비게이션
if last_page==0:
last_page = source.find('td',class_='pgRR').find('a')['href']
#마지막 페이지 주소추출
last_page=last_page.split('&')[1]
last_page=last_page.split('=')[1]
last_page=int(last_page)
if page_n<last_page:
page_n+=1
historical_index_naver(index_cd,start_date,end_date,page_n,last_page) # 재귀 알고리즘
return historical_prices갑자기 어려워 보이지만 자세히 들여다보면 지금까지 한 코드를 사용한 것을 알 수 있다.
이를 통해 원하는 날짜의 종가를 추출해보자.
index_cd = 'KPI200'
historical_prices = dict()
kpi200=historical_index_naver(index_cd,'2018-5-4','2019-10-31')
tmp={'KPI200':kpi200}
data=pd.DataFrame(tmp)
data

원하는 날짜는 input 함수를 통해 직접 입력 받게 코드를 짤 수 있다. 지금까지 우리는 코스피 200을 추출하는 코드를 짜보았다. 다음 K10 지수를 추출하는 코드를 소개하겠습니다.
'심심풀이 project' 카테고리의 다른 글
| 회귀 알고리즘을 이용한 주가분석 -2 (0) | 2020.05.17 |
|---|---|
| 복권 분석 (2) | 2020.04.10 |


댓글