Image Classification은 Computer Vision에서 가장 핵심이 되는 작업이다.
Image Classification이란, 사진이 있을 때 정해진 Label을 보고 어떤 사진인지 판단을 하는 것을 말한다.
Image Classification이 가능하면 Object Detection, Image Segmentation, Image Captioning이 가능하도록 한다.
Image는 3차원 행렬로 0~255 사이의 정수로 이뤄져있다. RGB 값을 받기 때문에 3차원으로 이뤄진다.
shape은 H x W x C로 구성된다.
Image Classification의 문제는 여러가지가 있다.
1. Viewpoint variation : 이미지를 보는 시각에 따라서 이미지는 다르게 보일 수 있기 때문이다.
2. illumination : 조명의 밝기에 따라 이미지가 달라질 수 있다.
3. Deformation : 형태의 변형
4. Occlusion : 분류하고자하는 객체가 어딘가에 가려짐의 문제
5. Background clutter : 배경하고 구분이 거의 안되는 문제
6. Intraclass Variation : 예를 들어 고양이의 종류의 다양성 같은 문제
과거엔 Image classification을 하기 위해 여러 방법을 시도하였는데 그 중 하나가 이미지의 특징점(Corner, Edge)를 찾고 이러한 배열이 어떻게 구성되어 있는가를 찾아낸다. 그리고 이를 통해서 Classification을 하려는 시도가 있었다.
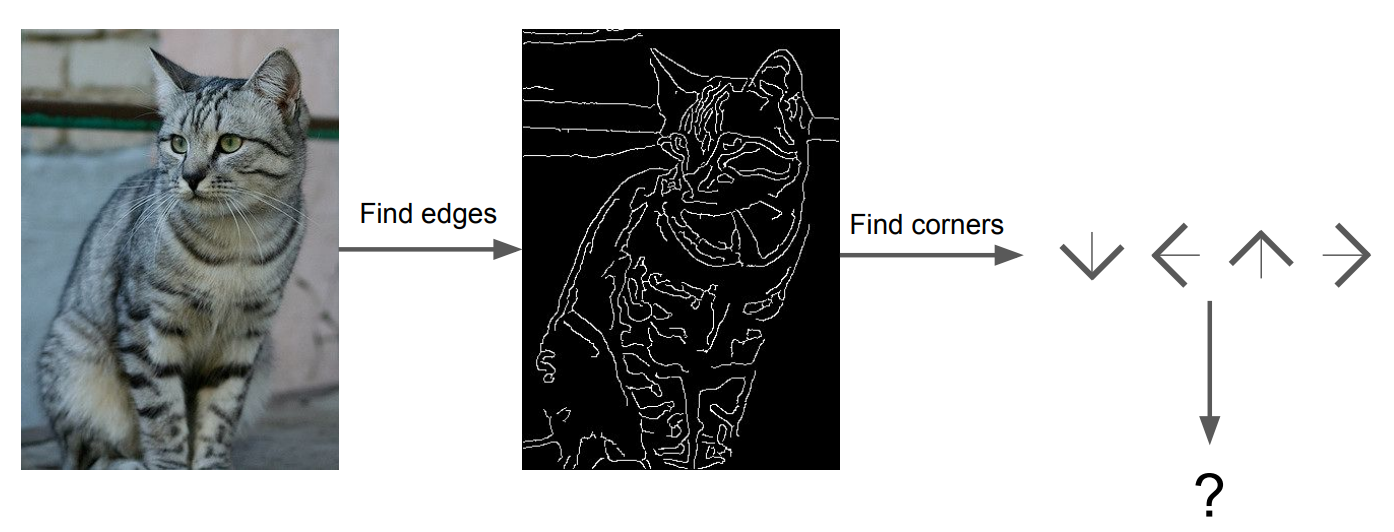
하지만 이 방식은 한계점이 있었고, 현재는 Data-Driven 방식을 이용하여 접근한다.
Data-Driven Approach는 다음과 같다.
1. 이미지와 라벨로 구성된 데이터셋을 수집한다.
2. 이미지 분류를 위한 머신러닝을 사용해서 학습한다.
3. test image set을 이용하여 학습시킨 Image Classifier 모델을 평가한다.
이러한 Data-Driven에 대한 첫번째 방법으로 Nearest Neighbor Classifier를 학습한다.
## Nearest Neighbor Classifier
Nearest Neighbor Classifier는 모든 training image와 label을 모두 메모리에 올린다. 즉, 모든 train dataset을 기억하는 것이다. 그리고 예측단계에선 test image를 기억했던 모든 training image와 하나하나 다 비교한다. 비교하고 가장 비슷한 label로 예측한다.
강의에선 예제 데이터셋으로 CIFAR-10을 사용한다. CIFAR-10은 32x32 이미지이고 클래스는 10개이다. 그리고 5만장의 훈련 이미지와 만장의 test 이미지로 구성되어있다.

Nearest Neighbor를 사용했을 때의 결과는 다음과 같다.

맨 왼쪽열에 있는 것이 Test Image이고 화살표 다음에 맨 처음에 나온 이미지들이 가장 비슷한 이미지들이다.
개구리 사진을 보면 가장 비슷한 이미지가 고양이로 나왔다. 이를 통해 정확도가 높지 않음을 알 수 있다.
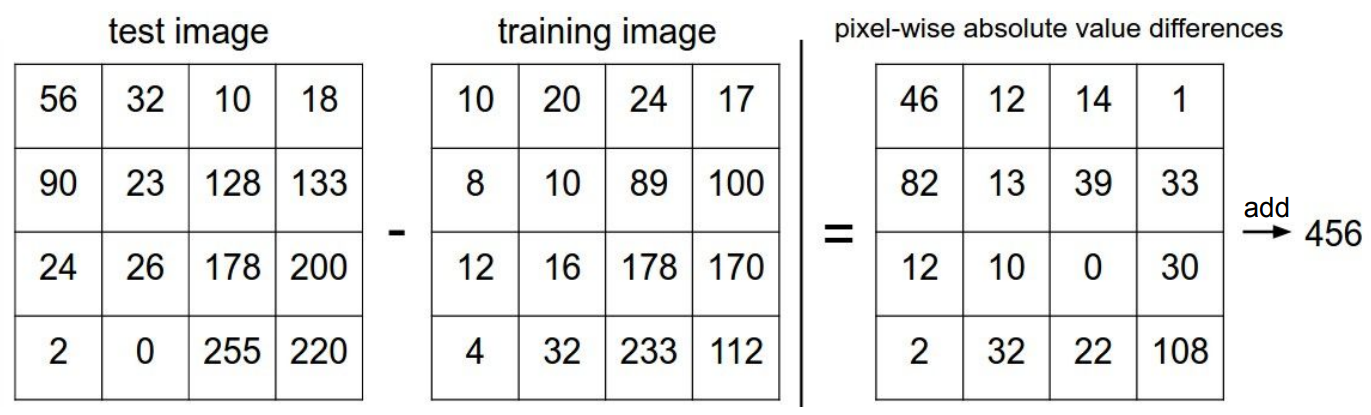
Nearest Neigbor 알고리즘은 어떻게 유사도를 판단할까? 이는 L1 Distance를 통해 할 수 있다.
$$ L_{1} = \sum_{p} \vert I_{1}^{p} - I_{2}^{p} \vert $$
즉, 이미지 1과 이미지 2의 차이의 절대값을 말한다.
만약에 이런 모델에서 이미지의 크기가 더 커지면 연산 속도는 어떻게 될까?
당연히 Linear 하게 늘어나게 된다. 이미지의 크기가 커지면 그만큼 픽셀이 늘어나는거니 연산량이 많아질 수 밖에 없다. 또한, 모든 이미지를 메모리에 올리니 메모리 아웃도 날 수 있다.
Nearest Neighbor에선 L1 Distance를 사용하였는데, L1 Distance 뿐만 아니라 L2 Distance도 존재한다. 이는 하나의 하이퍼파라미터이다. L2 Distance는 다음과 같다.
$$ L_{2} = \sqrt{\sum_{p} (I_{1}^{p} - I_{2}^{p}) ^ {2}} $$
## KNN
Nearest Neighbor와 비슷하지만 Nearest Neighbor는 가장 유사한 것만 뽑는거였다면 KNN은 K개의 유사한 이미지들을 선택하고 그 중 다수결로 어떤 label이 많이 나왔는지를 선택해서 예측하는 것이다. 일반적으로 KNN이 성능이 더 높다고 알려져있다.
## Hyperparamter Setting
KNN 알고리즘에서 K와 distance method는 하이퍼파라미터이다. 그러면 이러한 하이퍼파라미터는 어떻게 설정할까?
본 강의에선 문제에 따라 매우 다르다는 것을 말한다. 즉, 다 시도해보고 거기서 best를 찾아야된다는 것이다.
그러면 training set에서 하이퍼파라미터를 계속 바꿔가면서 계속 test에 적용하면 될까? 절대 안된다!
test set은 성능 평가를 위해 무조건 최후까지 남겨야되는 dataset이다. 그러기 때문에 함부로 사용해선 안된다.
test set을 활용할 수 없으니 Training set의 일부분을 갖고 validataion set을 설정해야한다. 보통은 Training data의 20% 정도를 활용한다. 만약에 Training data가 너무 적은 경우는 어떻게 할까?
이 땐 Cross Validation을 이용해야한다.

Cross Validation은 처음에 N개(예시로 5라고 설정)으로 나누고 fold 5번째를 validation set으로 설정한다.
즉, 1 iteration 땐 fold1~4 를 training set으로 fold5를 validation set으로 설정한다.
2 iteration 일 땐 fold1,2,3,5를 training set으로 fold 4를 validation set으로 설정한다.
이러한 과정을 N번(5번)을 반복해서 나온 결과(정확도)를 평균내서 성능을 평가한다.
## KNN을 사용하면 안되는 이유
첫번째로 test 하는데 매우 많은 시간이 든다.
그리고 두번째는 다음의 그림으로 볼 수 있다.

Original에서 변환된 3개의 이미지는 모두 같은 L2 distance를 가진다. 이 3개의 이미지는 완전히 다른 이미지임에도 불구하고 동일하게 판단을 하게 된다는 것이다.
## Linear Classification
Linear Classification은 Parameteric Approach를 취하고 있다. 앞서 설명한 NN과 KNN은 parameter를 사용하지 않는데 Linear Classfication 부턴 Parameter를 기반으로 접근하는 방식이다.

위 식에서 x는 image이고 W는 paramter이다. X는 사용자가 튜닝할 수 없는 것이다. 그러나 W는 사용자가 튜닝을 할 수 있다. 즉, 여기서 W는 paramter가 되고 이를 weight라고 보통 부른다. 이러한 W를 조절하면서 예측을 하는 것이다.
$$ f(x,W) = Wx $$
이를 하기 위해서 먼저 3차원의 행렬을 1차원의 행렬로 쭉 펼친다. (32,32,3) -> (3072,1)로 변환되서 x라는 벡터가 된다.
그리고 이를 계산하기 위해 W의 shape은 (10,3072) 가 된다. 여기서 10은 10개의 클래스를 예측하기 위함이다.
이를 그림으로 표현하면 다음과 같다.
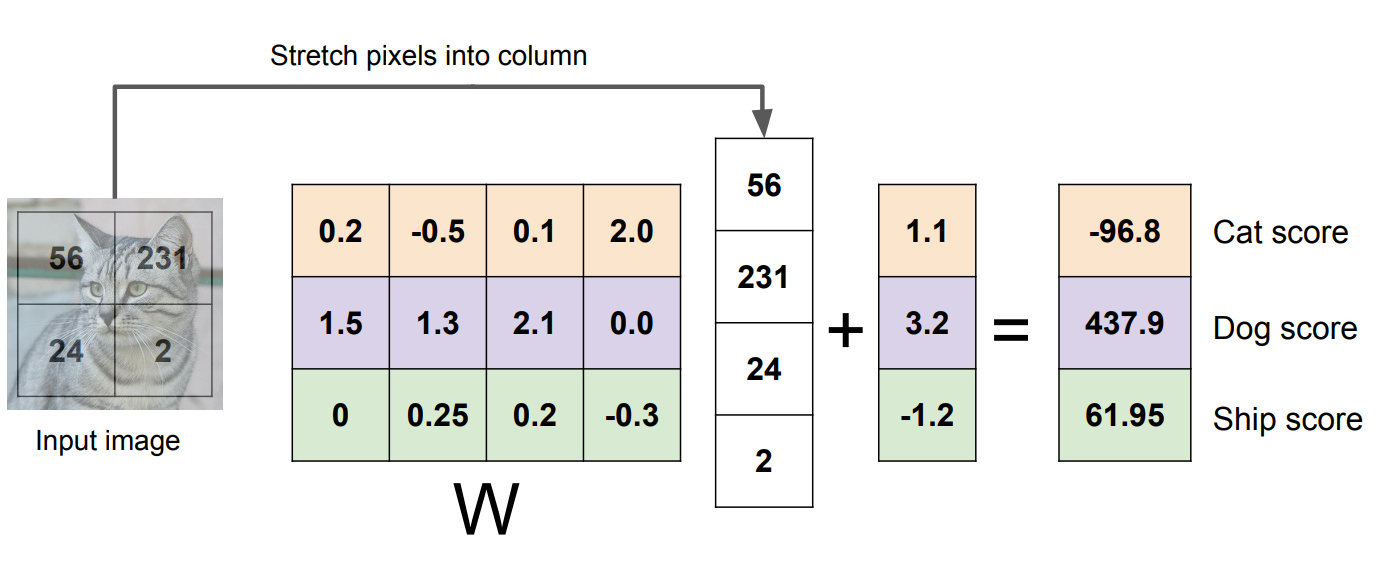
Image의 픽셀을 임의로 4개라고 가정하자. 그리고 클래스는 3이라고 하자.
이 4개의 픽셀을 (4,1)로 쭉 펼쳐준다. 그리고 클래스는 (3,1)이 되고 bias도 동일하게 (3,1)이 된다.
그러면 W의 shape는 \( Wx+b = y \)가 되야하고 shape를 나타내면 \( (n,m) \cdot (4,1)+(3,1) = (3,1) \)
이 된다. 따라서 n =3, m = 4가 되어야한다. 그리고 이 값을 계산해주어서 각각 클래스의 점수를 추출한다.
이러한 방식으로 계산해서 Image Classifier를 한마디로 표현하자면
이미지의 모든 픽셀값에 가중치를 곱하여서 계산한 값의 합
"Just a weighted sum of all the pixel values in the image"
## Linear Classifier의 한계
이미지에 가중치(W)를 준 것을 이미지로 나타낸 그림이다.

이 그림을 봤을 때 차를 예시로 들면 차같은 경우 빨간색 차가 학습이 되었음을 알 수 있다. 여기서 frog를 보면 약간 노란빛 계열을 띄고 있음을 알 수 있다. 그럼 만약에 노란색 차를 test로 했을 땐 어떤 결과가 나올까?
이 그림을 보면 frog로 예측할 확률이 매우 높다. 따라서 색깔 특성에 의존적임을 알 수 있다.
또한, Linear Classifier가 분간하기 힘든 종류는 사진에서의 정반대의 색상으로 이뤄진 것, Grayscaling 된 것, 형태는 다르지만 색상은 동일한 경우 등이 있다.
'cs231n' 카테고리의 다른 글
| cs231n - Backpropogation and NN part1 (0) | 2021.08.30 |
|---|---|
| cs231n - Loss function & Optimization (0) | 2021.08.27 |


댓글