본 글은 A comprehensive Survey on Pretrained Foundation Models : A History from BERT to ChatGPT
논문을 참고하여 작성한 글입니다.
PFM ( Pretrained Foundation Model) 은 pretraining 기술에 기반을 두고 있는 모델로 많은 양의 데이터와 task를 학습하여 쉽게 fine-tuning 하여 일반적인 모델로 훈련할 수 있는 것에 목적을 둔 모델이다. 최근 각광받고 있는 ChatGPT도 이에 대한 일종이다. 따라서 이러한 모델들이 AI 분야의 전반적으로 널리 쓰이고 있으며 본 장에서는 NLP에서의 PFM을 알아보도록 한다.
NLP task에서 현재 주로 연구되는 분야는 다음과 같다. (기타 포함)
1. Named entity recognition : text의 entity 에 해당하는 유형으로 태그를 지정하는 작업. 보통 BIO로 구분하여 B (Beginning), I (Inside) , O (Other - 해당 없음)를 말함.
2. semantic role labeling : 문장에서 "누가 누구에게 무엇을 했는가"를 답하는 것 처럼 text에서 의미를 찾는 task
3. machine translation : 한 언어에서 다른 언어로 번역하는 task
4. Question and Answering (QA) : 질문이 주어지면 이를 답하는 task
5. sentiment analysis : 문장의 감정을 분석하는 task
6. text summarization : 문장 요약 task
7. text classification : 문장이 어느 카테고리에 있는지 분류
8. relationship extraction : 문장에서 각 단어들이 어떠한 관계가 있는지 추출
9. event extraction : 문장에서 어떠한 이벤트가 발생하는지 추출
이러한 task 들이 있는 NLP에서 PFM 의 아이디어가 나왔고, 많은 발전을 이루었다.
이번 장에서는 word representation method 와 Model Architecture Designing method, Masking Designing Method, Boosting Method, Instruction Aligning Method 를 중심으로 얘기한다.
Word Representation Method
현재 존재하는 Pretrained LM(Language Model)은 주로 3가지로 나눌 수 있다 : Autoregressive LM, Contextual LM, and premuted LM. 이러한 모델에서 단어 예측 방향과 문맥적 정보는 가장 중요한 요소이다.
Autoregressive LM
autoregressive LM 은 앞선 단어 또는 연속적인 단어에 기반한 마지막 확률을 기반으로 다음 단어의 나올 확률을 예측하는 것이다. 따라서 이는 feature selector로써 역할을 하고 이전 단어로 부터 text representation 이 추출된다. 그래서 이는 text summarization task 와 machine translation task 에서 좋은 성능을 보인다.
sequence \( T = [ w_1 , w_2 , \cdots , w_N ] \)이 있을 때, 주어진 단어의 확률은 앞 단어에 따라 계산되고, 이는 다음과 같은 식을 따른다.
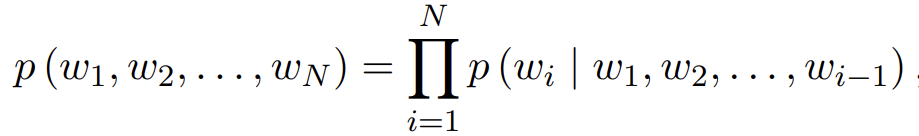
Transformer Decoder는 auto-regressive 한 방식을 사용하였다. GPT도 이러한 방식을 2-stage 방식으로 채택했으며 self-supervised pretraining 및 supervised fine-tunning 방식을 사용한 Transformer decoder를 쌓은 방식을 사용하였다.
GPT-2는 이런 Transformer decoder를 48 layer로 증가하여 쌓았다. 이와 더불어 서로 연관있는 task들을 동시에 학습하여 모든 과제 수행의 성능을 전반적으로 학습하려는 multi-task learning도 소개하였다. GPT-2의 또 하나의 contribution은 transformer decoder 위에 하나의 auto-regressive LM 을 구축하여 computation cost 를 늘리지 않았다.
즉, multi-task pretraining과 super-large dataset, super-large model로 GPT-2는 한방향 Transformer의 문맥 이해가 부족한 점을 보안하였다.
그러나 auto-regressive LM은 이전 또는 그 후 정보만 사용하고, 이를 동시에 사용할 수 없다는 단점이 있다.
Contextual LM
Contextual LM은 contextual word에 기반한 예측을 한다. 이는 Transformer encoder를 사용하며 모델의 상부 및 하부 레이어는 모두 self-attention 으로 인해 서로 직접 연결된다. 즉 이는 autoregressive LM 과 다르게 sequence T에 대해서 다음과 같이 확률이 계산된다.

BERT는 이러한 bi-directional Transformer를 기본구조로 쌓는 것으로 이뤄져 있고, 단어 분할을 Word-Peice tokenize로 한다. BERT의 모델 input은 3가지 부분으로 구성이 되어 있는데 word embedding 과 segment embedding, 그리고 position embedding으로 구성되어 있다. 이는 Transformer Encoder를 feature extractor 로 사용해 ELMO와 GPT의 결함을 극복하였다. 그러나 bidirectional Transformer 구조는 sefl-encoding의 제약사항을 제거할 수 없다. 즉, 이는 모델의 파라미터가 너무 많아서 많은 컴퓨팅 비용이 든다는 것이다. 그리고 공개되지 않은 pretraining 모델을사용했다.
대부분의 PRM은 많은 training task와 더 큰 corpus가 필요하다. RoBERTa 는 이러한 불충분한 training 문제에 초점을 맞춰 이를 극복하기 위한 모델이다. 이는 큰 batch size와 unlabeled data를 사용하였다.그리고 오래 훈련하면서 NSP (Next Sentence Predcition) loss 제거하고 full sentence에 대한 훈련을 하여 순서를 학습하게 하였다. RoBERTa는 BERT와 달리 BPE (Bype Pair Encoding)을 사용하여 단어 분할을 위한 input text에 대한 처리를 하였다. BPE는 각 input sequence 마다 다른 mask 처리를 해주는 것으로 input sequence가 동시에 들어와도 다르게 처리하는 것을 말한다.
Permuted LM
contextual LM은 auto-encoding 모델로 여겨진다. 그러나 훈련단계와 fine tuning 단계에서의 불일치성 때문에 NLG (Natural Language Generation) task에선 좋은 성능을 내지 못하였다. 따라서 이를 극복하는 방법이 Permuted LM 이다.
Permuted LM은 auto regressive LM 과 auto-encoder LM의 장점을 결합하려 노력하였다.Permuted LM의 input sequence T 에 대해서 target function 식은 다음과 같다.

여기서 \( \theta \)는 모든 permutation에서 공유된 parameter를 말하고 \( Z_N \) 은 input sequence T의 모든 permutation의 확률 집합을 말한다. 그리고 \( z_{T=t} , z_{T<t} \) 는 permutation \( z \in Z_N \) 의 t 번째 원소를 말한다.
BERT 에서 표현된 Masked LM (MLM)은 bi-directional coding이 잘된다. 그러나 MLM은 pretraining 동안만 masking marking이 되지 fine tunning 에선 안되어서 여전히 pretraining 과 fine-tunning 간의 불일치가 발생한다. 이러한 MLM의 문제를 해결하기 위해 permuted LM이 제안되었다.
permuted LM은 데이터의 불일치성이 일어나지 않은 auto-regressive LM을 기반으로 inconsistent 문제를 해결하고자 하였다. 그러나 전통적인 autoregressive model 과 달리, permuted LM은 sequence를 순서대로 모델링하지 않는다. sequence의 에상된 log likelihood를 최대화 하기 위해 sequence의 가능한 모든 순열을 제공한다. 이러한 방식으로 모든 위치에 있는 문맥 정보를 파악할 수 있고, permuted LM은 bidirectional encoding이 가능해진다. 이에 대해 처음 제안한 논문은 XLNet이다. XLNet은 relative positional encoding 과 segment recurrence 를 Transformer-XL에 결합하였다.
MPNet 은 MLM 과 permuted LM을 결합하고 permuted LM을 통해 token 간의 의존성을 예측한다. 이는 보조 입력 정보를 input으로 넣어 모델이 완전한 문장을 볼 수 있도록 하여 위치에 대한 차이를 줄인다.
Model Architecture Designing Methods
ELMO 는 오직 bi-LSTM 만을 사용한 모델로 양방향의 likelihood를 최대화 하는 목적으로 학습된다.word vector 방법과 비교하였을 때, ELMO는 문맥 정보를 도입하고, 다의어 문제를 향상시켰지만, 언어적 특징을 추출하는 것은 잘하지 못하였다.
PFM 을 적용하는 방식에는 두가지 방향으로 나뉜다. 1. fine tunning (e.g. BERT) 2. zero / few shot prompts ( e.g. GPT)
BERT는 Transformer의 bi-directional Encoder를 사용하여 어떤 단어가 마스킹 되는지 예측하고 두 문장이 문맥에 맞는지 판단한다. 그러나 양방향으로 인코딩 되고 놓친 토큰들은 독립적으로 예측되어서 이는 generation 능력을 저하시킨다.
반면에 GPT 는 feature extractor로 auto-regressive decoder를 사용하여 처음 단어에 기반하여 다음 단어를 예측하고 fine-tunning을 통해 downstream task 를 해결하여 이는 text generation task에 적합하다. 그러나 GPT는 오직 이전의 단어만 예측에 사용하므로 bidrectional interaction information을 배우지 못한다.
※ downstream task는 사전 학습된 언어 모델 위에 구축된 특정 자연어 처리 작업을 나타냄.
따라서 BART 는 encoding-decoding 구조의 seq2seq 모델로 구축하여 noise를 줄인 auto-encoder 모델이다. 그림에서 볼 수 있듯이, BERT Encoder와 GPT Decoder의 결합니다. BART 는 noise 를 사용하여 text를 파괴한 후, seq2seq 모델로 원본 텍스트를 재구성한다. 이를 좀 더 자세히 말하자면, noise는 5가지 모드로 추가되는데, 다음과 같다. single word mask, word deletion, span mask, sentence rearrangement, and document rearrangement. encoder 안에 들어가기 전에 sequence는 masking 되어 encoder에 들어간다. 그리고 나서 decoder는 masking이 되기 전의 original sequence를 복구하도록 한다.
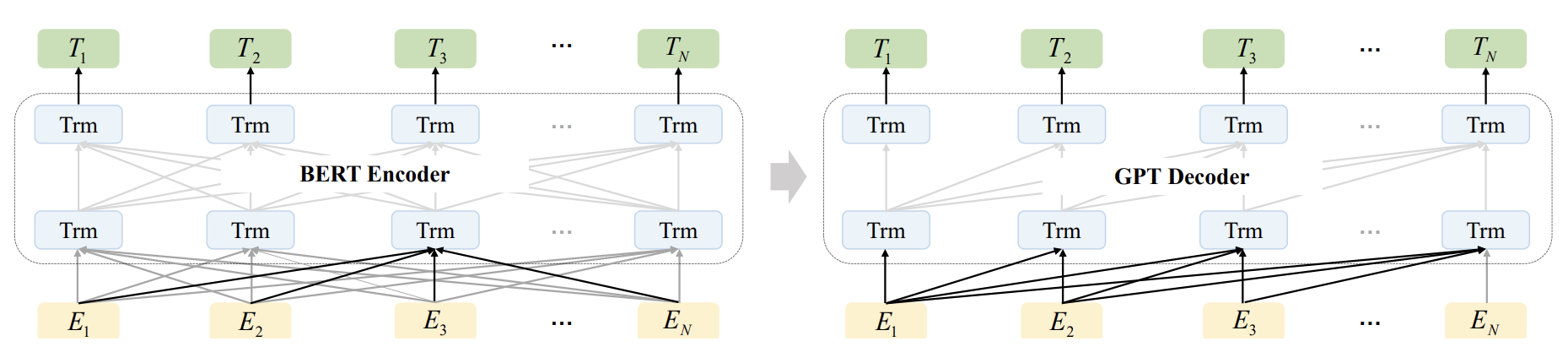
Masking Designing Methods
Attention mechanism은 먼저 필수 단어를 문장 벡터로 중요한 문장 벡터를 text vector로 합쳐 모델이 서로 다른 input에 대해 attention 을 갖도록 한다. bi-directional 한 Encoder를 가진 BERT 는 여전히 Natural Language Generation task 에 대해선 문제가 있었다.
RoBERTa 의 기반을 둔 SpanBERT 는 dynamic masking과 single segment pretraining 방법을 택하였다. span mask 와 SBO (Span Boundary Objective) 특정한 길이로 단어들을 마스킹을 한다. 기존의 모델은 한 단어를 masking 하여 masking 한 단어를 예측하였지만, SpanBERT 는 연속된 여러 단어의 masking으로 여러 단어를 예측할 수 있도록 한다. 그림에서 보이는 것과 같이 문장 중간의 여러 단어를 masking 하여 masking 의 전 단어와 그 후 단어들로 masking 한 단어들을 예측할 수 있게 한다. data processing 에서 masking을 하는 것이 아닌 훈련 과정에서 이와 같은 dynamic masking 전략을 사용한다.
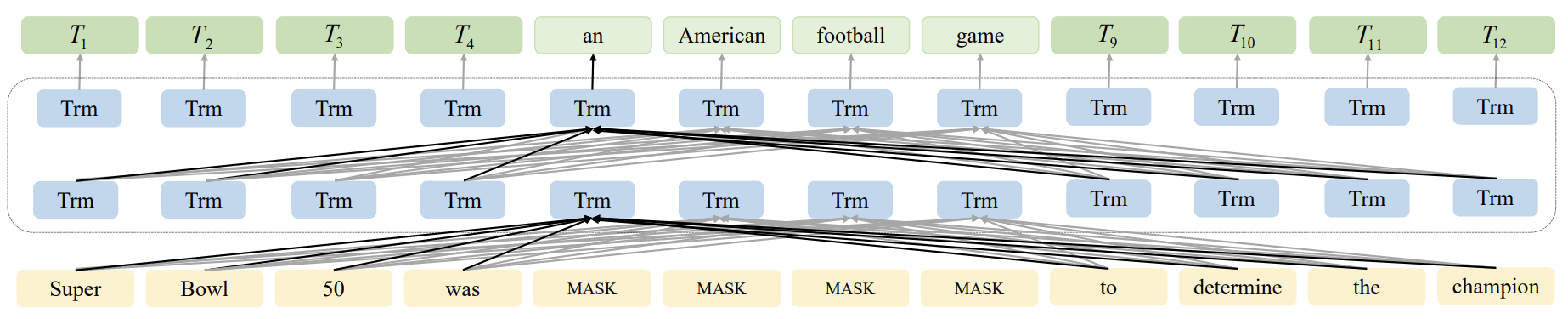
MASS 는 masking 된 seq2seq 모델을 제안하여 훈련 단계에서는 encoder에 들어가는 input seqeucne는 k의 길이를 가진 연속적인 segment를 랜덤하게 masking 하고, decoder는 이를 복구하는 식으로 훈련한다.
UniLM 은 두 문장 간의 다른 마스크들을 씌움으로써 NLG 모델의 훈련을 이뤄냈다. 첫번째 문장에선 UniLM은 Transformer Encoder를 사용하여 각 단어가 앞뒤 단어를 알 수 있도록 한다. 그리고 이어서 두번째 문장에서는 각 단어는 첫번째 문장의 모든 단어와 현재 문장의 앞 단어만 인식할 수 있다. 따라서 첫번째 두번째 문장만을 model (=seq2seq)의 input으로 넣는다.
Boosting Methods
Boosting on Model Performance
대부분의 Pretrained 모델들은 많은 양의 데이터가 필요한데, 이는 많은 hardware resource 가 필요하다. 그래서 사용자들은 retraining 하기엔 어렵고 오직 fine-tunning 만 할 수 있다. 그래서 이러한 문제를 해결하기 위해 몇몇 모델들이 등장하였다. 예를 들어 ERINE Tiny는 ERINE 모델을 경량화하여 inference time을 줄였고, ALBERT 는 메모리 소비와 training speed를 줄였다.
Boosting for Multi-task learning
ERNIE는 Transformer Encoder와 task embedding 파트로 나뉜다. Transformer Encoder 부분에선 self-attention을 통해 각 토큰에 대한 context 정보를 추출하고, context representation을 임베딩을 생성하는 용도로 사용된다. 그리고 Task embedding 에선 다른 task 들의 특성을 적용한다.
ERNIE 2.0 은 muti-task learning으로 lexical, grammar, semantics의 pretraining을 실현한다. 여기서 7개의 다른 task 들이 사용되는데, 이는 3가지 측면 (word level, sentence level, semantic level)을 포함한다. 이는 continual learning을 사용하여 이전에 학습한 정보들을 유지하고, model이 long distance memory를 갖게 한다. Transformer Encoder 와 task embedding 을 제안하여 task의 명확한 차이를 continual learning으로 model이 인식할 수 있게하였다.
UniLM은 3 가지 pretraining task (unidirectional LM, bidirectional LM, encoder-decoder LM)를 사용하였고, self-attention layer를 통해 pretraining 단계에서 이러한 task들을 동시에 완료할 수 있게 만들었다. 훈련 단계에서 UniLM은 SpanBERT에서 제안된 small segment mask 전략을 택하면서 loss function을 3가지 task를 수행할 수 있게 만들었다.
Boosting Examples: ChatGPT and Bard
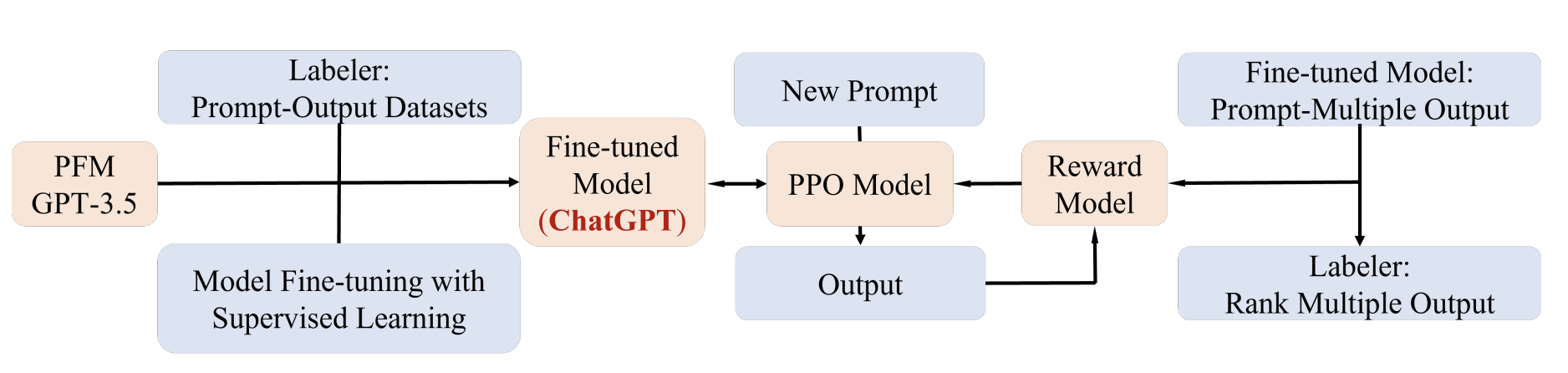
chatGPT는 PFM (GPT 3.5)을 기반으로 RLHF(Reinforcement Learning Human feedback) 를 사용하여 fine tunning 한 것이다. InstructGPT와는 다른 데이터셋을 사용하였다. 먼저, 대규모의 prompt가 포함된 데이터셋과 바람직한 output 행동들을 담은 데이텃셋을 모았다. 이 데이터셋은 GPT-3.5를 supervised learning을 통해 fine tunning 하는 용도로 사용되었다. 두번째로 모델과 prompt 가 주어지면, 모델은 그에 대한 output을 반환하고 labeler 들은 이러한 ouput 들을 검수하여 점수와 등수를 매긴다. 이를 통해 RL에서 사용되는 보상 reward가 이뤄지는 것이다. 마지막으로 chatGPT는 Proximal Policy Optimization (PPO) RL 알고리즘에 의해 최적화된다.
Bard 는 구글이 만든 모델로 LaMDA 를 기반으로 한다. LaMDA 는 Transformer로 만들어지며 web data등을 통해 많은 양의 단어를 학습하였다.
Instruction-Aligning Methods
Instruction-aligning method는 LM이 사람의 의도에 따라 유의미한 output을 내는 것을 목적으로 한다. 이에 따른 일반적인 접근 방법은 pretrained LM을 supervised 방식으로 high-quality의 corpus로 fine-tunning 하는 것이다. LM의 활용성을 늘리고 위험성을 줄이기 위해 몇몇 방법들은 RL을 사용하였다. 따라서 supervised 와 RL은 chain-of-though 스타일의 추론을 활용하여 사람이 판단하는 AI의 의사결정의 성능과 투명성을 개선할 수 있다.
Supervised Fine-Tuning (SFT)
사실 이건 설명할 것 없이, 정답값을 아예 알려주면서 tuning 하는 방식이다. input-output pair 로 구성되어야한다. 여기서 주로 human feedback 이 들어가게 되는데 윤리나 사회적 위험에 대한 것들을 검수하는 것이다.
Reinforcement Learning from Feedback
RL은 다양한 NLP task 에서 적용되어 왔다. RL은 언어 생성 분야에서 차별화할 수 없는 목표를 순차적 의사 결정 문제로 처리하는데 최적화된 방법이다. 그러나 overfitting 에 대한 위험성은 여전히 존재한다.
InstructGPT는 학습된 reward model에 PPO를 사용하여 large model을 fine tuning 하여 LM을 사람의 선호도에 맞추는 방법을 제안한다. 이는 chatGPT에서 RLHF 라고 불리는 것과 같은 방식이다. 특히, 보상 모델은 labeler들의 메뉴얼에 의해 순위가 매겨진 데이터로 훈련된 것이다.
DeepMind에서 만든 Sparrow도 RLHF를 사용하여 부정확한 답변의 위험성을 줄였다. 이러한 RLHF의 괜찮은 결과에도 불구하고 open 되지 않았었는데, RL4LMs 라는 RL로 LM을 fine tuning 하는 라이브러리가 최근에 소개되었다.
여기서 나온 각 모델들에 대한 정리는 추후에 공개합니다.
'논문 정리' 카테고리의 다른 글
| Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming (0) | 2023.03.16 |
|---|---|
| Model Summary (NLP) (0) | 2023.03.15 |
| [Task 파악] Phrase Grounding & Weakly Supervised learning (0) | 2022.11.10 |
| Denoising Diffusion Probabilistic Models(DDPM) (1) | 2022.11.08 |
| Zero-shot Learning (2) | 2022.09.05 |




댓글