대체로 참고한 자료는 dmqm.korea.ac.kr/activity/seminar/281
고려대학교 DMQA 연구실
고려대학교 산업경영공학부 데이터마이닝 및 품질애널리틱스 연구실
dmqa.korea.ac.kr
김상훈님의 세미나 발표 자료이다.
위 논문은 아주 간단한 문제점에서 출발하고 이 문제점을 해결하기 위해 어떤 함수를 구현하는 것이다.
기존에 Open Set Recognition 논문이 발표 되었지만 위 논문은 DNN에 Open Set Recognition을 적용하는 첫 사례이다.
무려 CVPR2016에 발표된 논문이다.
- 분류의 문제점(SoftMax Function의 문제점)
기존의 신경망을 이용한 분류 모델은 다음과 같이 구현되어있다.
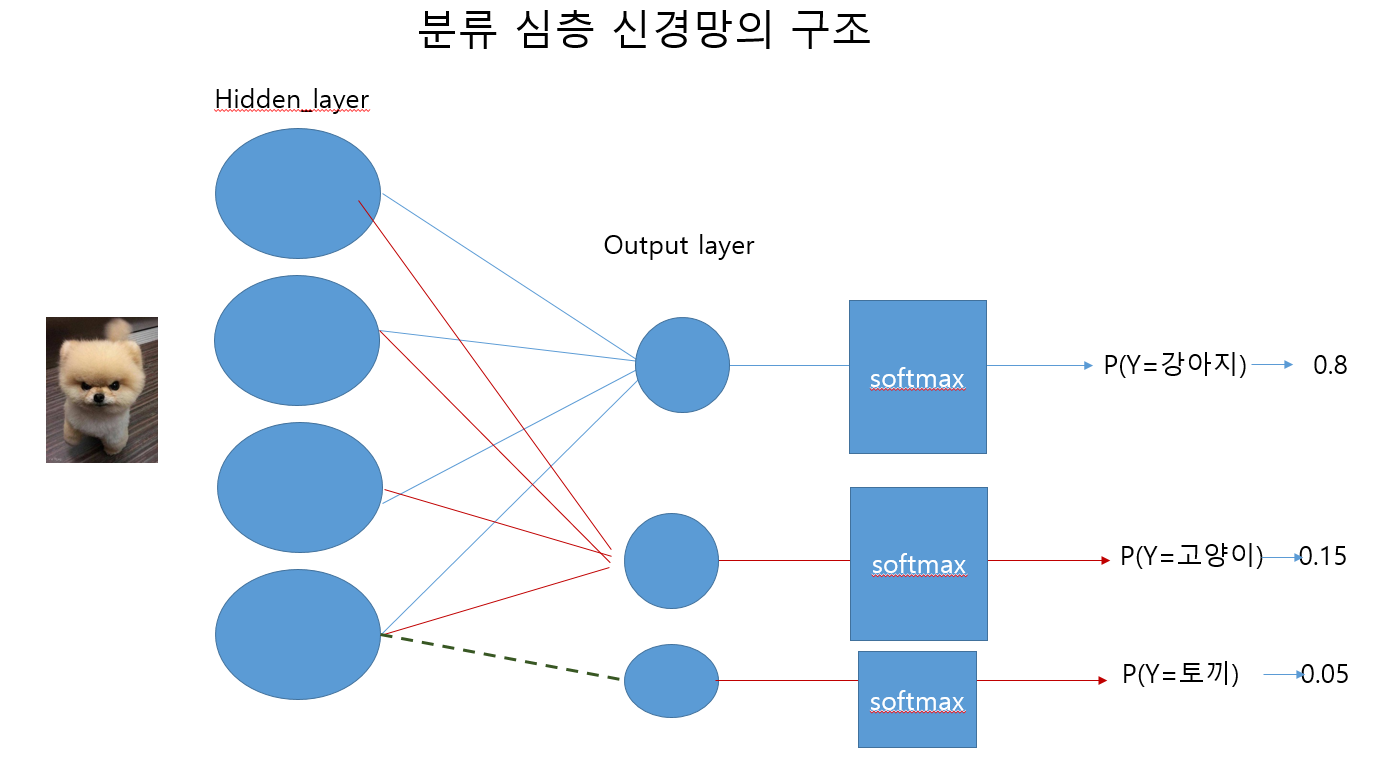
임시로 피피티로 그린건데..너무 그리기 힘들어서 간략하게 그렸습니다..이해 바랍니다...
Image Classification으로 예를 들자면 강아지 사진의 pixel(input X)값을 입력값으로 넣어 신경망을 거치고 softmax 함수를 이용하여 각 클래스의 확률값을 반환한다.
예를 들어 class1 = 강아지, class2 = 고양이, class3 = 토끼 라고 하였을 때 softmax를 통과한 값은 [0.8,0.15,0.05] 라는 확률값이 나오게 된다.
그리고 argmax 함수를 통해 가장 값이 큰 확률값의 인덱스를 반환하여 이 값이 어떤 클래스인지를 예측하게 되는 구조이다. 이 때의 output은 OneHotEncoding 형태로 나오게 된다. 이렇게 강아지/고양이/토끼 분류기가 생성되게 되는 것이다.
그럼 만약 이 분류기에 돌고래라는 사진이 들어간다면 이 분류기는 어떤 반환값을 내게 될까?
아마 강아지/고양이/토끼 중 무조건 하나라고 반환하게 될 것이다. 왜냐하면 전혀 관련 없는 이미지가 들어가도 꼭 셋중에 하나라는 것이라고 생각하는게 softmax 함수이기 때문이다.(의인화..표현법이 생각이 안납니다..)
이러한 softmax의 함수 값은 아마 [0.4,0.3,0.3] 라는 값이 반환될 것이다.(추측) 그러면 이 값은 강아지라고 예측하는 것이다. 이게 과연 정확한 분류라고 할 수 있을까???? 전혀 그렇지 않다.
이러한 문제점을 해결하기 위해선 어떻게 해야할까?라는 질문에 대답하는 논문이다.

- Idea1
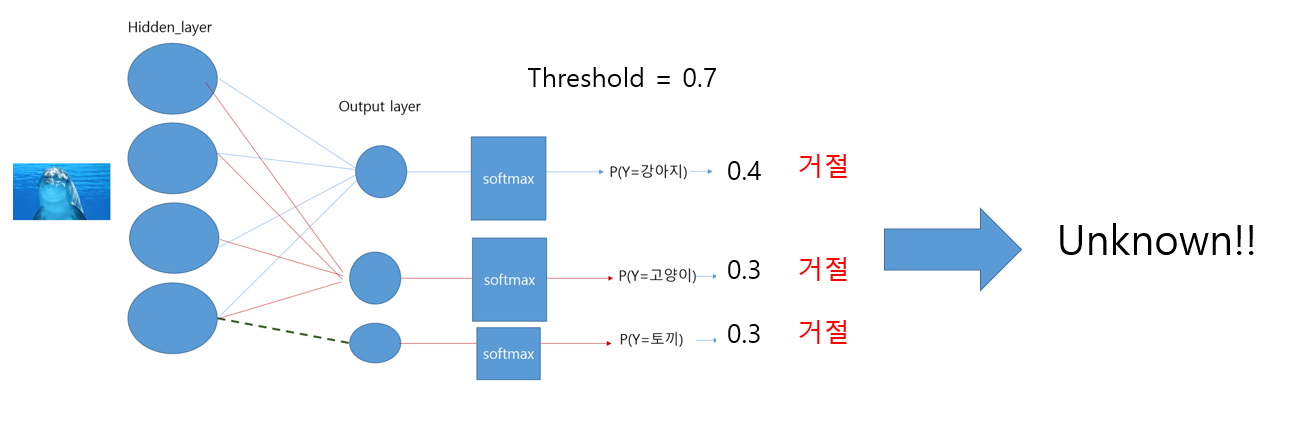
다음 그림과 같이 Threshold 값을 주어서 특정 확률을 넘지 않으면 reject 하고 Unknown이라는 클래스로 명시하는 것이다. 그러나 이는 문제점이 있다.
앞서 추측했던 softmax 값은 아주 이상적인 경우이다. 다음과 같은 예시를 보자

전혀 다른 그림이 나와도 softmax의 확률은 높을 수 있다. 그러면 threshold를 결정해줘봤자 틀린 결과값을 낼 것이다.
- Open Set Recognition
논문에선 Open Set Recognition을 이용한다.
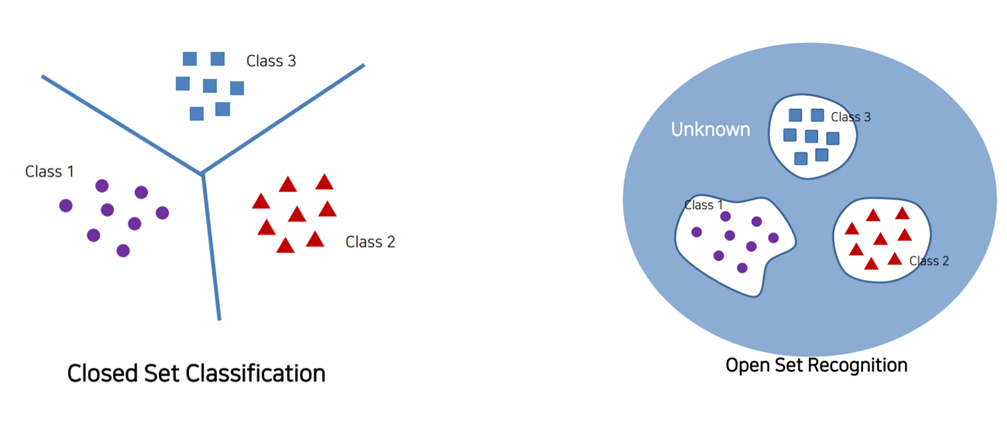
Closed Set 은 우리가 흔히 아는 분류기 SVM Classifier 라고 생각하면 된다. 분류선을 그어 클래스를 분류하는 것이다.
Open Set은 다르다. Class를 거리기반으로 뭉뚱그려 묶고 분류한다. 그 이후 class와 다른 것들은 Unknown Class라고 지정한다.
Open Set의 종류에 대해서 알아보자
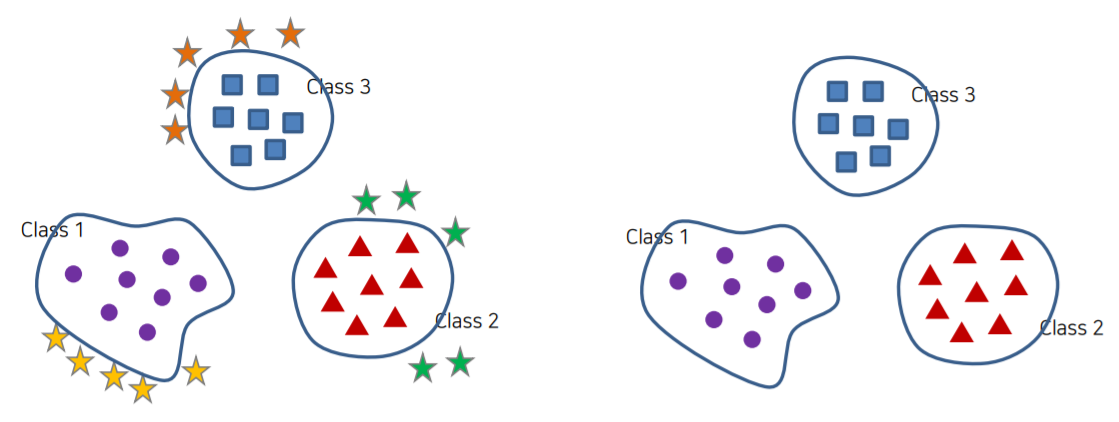
OpenSet의 종류는 크게 두가지가 있다.
1. Adversarial Learning-based : GAN와 같은 모델을 통해 각 클래스와 비슷한 다른 이미지들을 생성하여 새로운 클래스로 추가 학습을 시키는 것이다.
간단한 예시로 강아지/고양이/토끼 분류기에서 치타가 들어왔다면 치타라는 클래스를 하나 더 생성하는 것이다.
2. Distance-Based : 평균으로부터 떨어진 거리나 마진 등을 통해 결정 경계를 생성하는 것이다. 거리는 유클리디안 거리나 코사인 거리를 사용하고 이 둘을 합친 EUCOS 거리도 사용한다.
Open Set Recognition에 대해 더 알아보고 싶다면 Toward Open Set Recognition 논문을 읽어보는 것을 추천한다.
- OPENMAX
앞서 말한 Open Set Recognition 개념을 활용하여 OpenMAX 알고리즘을 구성한다.

V0는 Unknown 클래스의 logit vector의 값이다. V_k도 마찬가지로 logit 값이다.
그리고 w_k는 분류기가 k class로 잘못 분류 했을 때 대응하는 가중치이다.
여기서 그러면 w_k는 어떻게 정할 것인가라는 문제에 직면한다.
본 논문에선 Extreme value theorem(최대최소정리)에 기반하여 평균 Logit Vector로부터의 거리에 대한 극단값(이상치)의 분포를 통해 w_k를 정의한다.
Extreme value theorem 은 고등학교 때 살짝 배웠던 그 최대최소정리이다. 아마 그림을 보면 아~ 할 것이다.
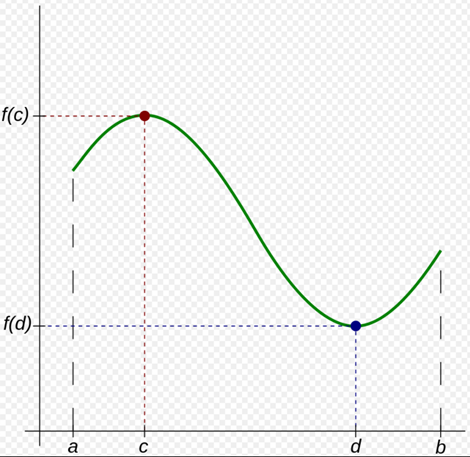
닫힌구간 [a, b]에서 연속인 함수 f는 최댓값 f(c)와 최솟값 f(d)를 반드시 갖는다. 라는 정리이다. 사실 이를 찾아보곤 어떻게 이걸 이용하여 가중치를 정의한다는 것인지 이해가 안갔지만 좀 더 읽어보도록 하자..!(곧 나옵니다)
- OPENMAX FLOW
openmax 알고리즘의 플로우는 다음과 같다.
1. 학습 데이터 중 분류기가 정확하게 선별한 데이터 선별한다. (softmax 함수를 통해 정확히 분류된 이미지들)
2. 선별된 데이터의 X(input)데이터를 클래스 별로 분리한다.
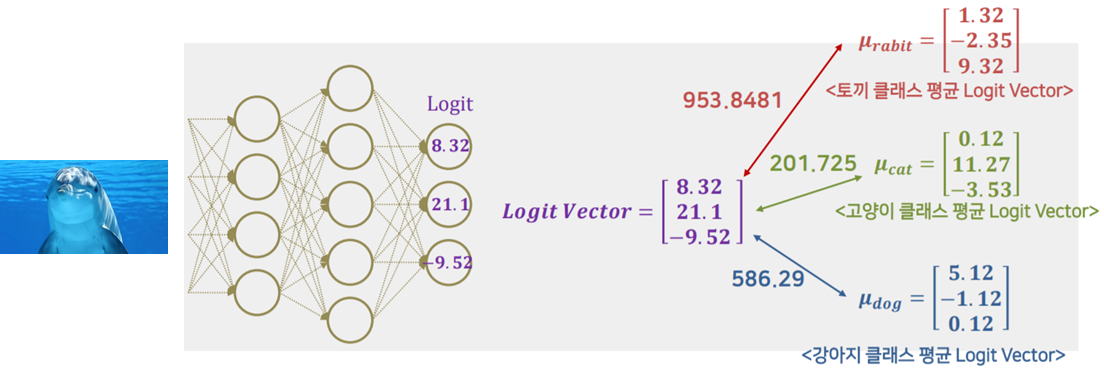
3. 각 클래스 별로 선별된 데이터를 이용하여 Logit Vector 계산(Softmax 들어가기 전 단계)
4. 각 클래스 별 Logit Vector의 평균 계산한다.

5. 각 클래스 별 평균 Logit Vector와의 거리 계산한다.

위 사진에선 간단하게 유클리디안 거리를 사용하였고 모든 이미지의 logit vector 값과 평균 logit vector 값과의 거리를 구한다.
6. 각 클래스 별로 계산된 거리 Matrix를 거리 기준 내림차순으로 정렬 후 평균 Logit Vector와 가장 거리가 큰 n개를 각 클래스 별로 추출한다.
이 과정은 n(정확히는 에타)개의 가장 먼 거리들의 matrix를 극단치라고 정의하기 위한 과정이다.
이 때 최대최소정리 개념이 등장한다.(사실 내가 알고 있는 짧은 지식의 그 정리 개념이 아니었다.)
The Fisher-Tippet Theorem 이란 정리가 최대최소정리 안에 따로 있었다..
이 이론은 동일분포에서 독립적으로 추출한 변수의 샘플 중 가장 큰 값을 뽑으면, 가장 큰 값보다 클 확률은 Weibull 분포, Frechet 분포, Gumbel 분포의 형태로 만들 수 있다. 라는 이론이다.

확률밀도표를 보면 Weibull 분포가 끊기는 점이 확실한 것을 볼 수 있다. (추후 보강) 위 논문에선 Weibull 분포를 사용하였다.
7. 각 클래스별로 거리가 가장 큰 n개의 샘플로 최대 가능도 추정을 통해 극단치 분포의 파라미터를 추정하고 클래스 별 극단치 분포를 생성한다.

8. 새로운 데이터를 넣고 Logit Vector를 계산하고 기존 클래스의 평균 logit vector와 거리를 계산한다
계산한 거리를 각 클래스 별 생성된 극단분포의 CDF(누적 분포)를 통해 평균 Logit Vector와의 거리 극단 확률을 계산한다.
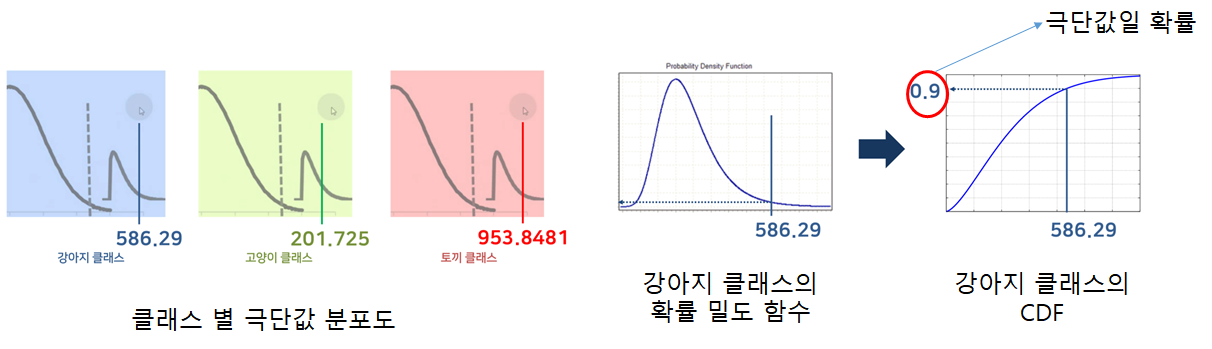
위 그림에서 강아지의 확률 밀도 함수에서 거리 값이 586.29 값이 나왔다. 이를 누적 분포로 바꾸어 극단값일 확률을 구해 이 거리가 극단값일 확률을 0.9로 정한다. 이 과정을 클래스 별로 반복한다.
9. 극단 분포의 CDF값(극단값일 확률)을 w_k로 두어 Logit Vector 업데이트
그리고 위에서 구한 클래스 별 극단값일 확률(예 0.9)을 w_k로 두어 logit vector에 업데이트를 한 후 softmax 함수를 통과시킨다.

위 그림처럼 각 가중치 w값을 업데이트 한 후 Unknown 클래스의 logit 값에도 update를 해준다. 그리고 이 logit 값을 softmax 함수에 통과시킨다. 그리고 확률을 계산하고 argmax를 통해 어떤 클래스인지 반환한다.
위의 예시에는 강아지/고양이/토끼 분류기에 돌고래가 들어갔으므로 Unknown으로 분류한다.
- Conculsion
이 주제는 분류기의 문제점을 다루고 간단한 개념을 통해 이를 해결하는 정말 흥미로운 주제였다.
현재 위 논문은 거리 기반의 Open Set Recognition을 진행하지만 최근에는 Adversarial Learning-based에 대한 연구가 활발히 이뤄지고 있다. 알고리즘이 점점 발달하면서 Computer Vision 뿐만 아니라 Classification의 개념 자체에 혁신을 가져다 준 연구라고 생각한다.
그리고 마지막으로 논문 읽기를 어려워하는 나에게 피피티로 이해시켜주신 고려대 김상훈님에게 정말 감사의 표현을 한다. 진심으로 정말 감사합니다..
'논문 정리' 카테고리의 다른 글
| Auto Encoding Variational Bayes(VAE) -1 (5) | 2021.03.29 |
|---|---|
| Deep Residual Learning for Image Recognition(ResNet) (4) | 2021.03.13 |
| YOLOv5 - training & test (23) | 2020.09.27 |
| YOLOv5 - Introduction (0) | 2020.09.27 |
| YOLO (0) | 2020.09.11 |




댓글