ResNet 원 논문
참고 자료
[논문읽기] 02. Deep Residual Learning for Image Recognition : ResNet
< Deep Residual Learning for Image Recognition > " style="clear: both; font-size: 2.2em; margin: 0px 0px 1em; color: rgb(34, 34, 34); font-family: "Roboto Condensed", Tauri, "Hiragino Sans GB", "Mic..
leechamin.tistory.com
www.youtube.com/watch?v=JI5kXF_OUkY
## 문제 제기
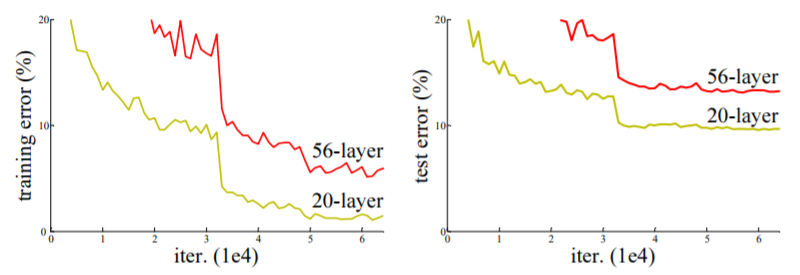
ResNet은 많은 층으로 구성되어 있는 네트워크가 항상 좋은 성능을 내는 것에 대한 의문점에서 출발한다. 본 논문의 저자는 아니다! 라고 말한다.
과거에는 층이 깊어질 수록 overfitting 문제 때문에 좋은 성능을 내지 못했었다. 이를 해결하기 위해 weight initialization과 효율적인 normalization으로 overfitting 문제를 어느정도 해결을 하였다. 하지만 여전히 문제되는 것은 Gradient vaninshing 문제와 exploding 문제로 인해 Degradation이란 문제가 발생하는 것이다.
본 논문은 이를 해결하기 위해 ResNet 모델을 제안한다.
※ 용어 정리(요약)
- Overfitting : train set의 accuracy는 높은데 test set의 accuracy는 낮은 것
- Degradation : train set과 test set의 accuracy가 낮은 것(performance 자체가 낮다)
## Deep Residual Learning 소개
Residual 이란 잔차 즉, true - predict를 말하는 것이다. ResNet의 기본 아이디어는 Original mapping 보다 residual mapping이 더 최적화 하기 용이하다라는 것이다.

Original mapping은 위 그림에서 "Plain layers" 이다. 기존의 신경망과 동일하게 입력값 x 가 convolution 연산과 활성화 함수를 거쳐 H(x)라는 output이 나오게 되는 것이다.

반면에 Residual block은 다음과 같은 식을 따른다.
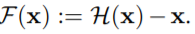
위 식에서 F(x)는 잔차, H(x)는 기존의 network , x는 input 값이다.
본 논문에선 기존의 neural network인 H(x)보다 F(x)의 최적화가 더 용이하다고 말하는데 그 이유는 F(x)=0 이 최적화 조건이기 때문이다.
이에 기반해 이를 feedbackfoward network에 적용한 것을 Identity ShortCut이라고 한다.
※ Shortcut connection : 한개 이상의 layer를 skipping 한 것
shortcut connection을 하기 위해선 한가지 조건이 필요한데 이는 input layer의 dimension과 output layer의 dimension이 동일해야 한다는 것이다.
이 조건에 맞춰서 ResNet에는 두가지 shortcut 이 존재한다.
1. Identity shortcut

변수의 의미는 다음과 같다. x : input layer vector, y : output layer vector, W : weight layer
위 식은 F = W2σ(W1x)를 간단하게 표현한 것인데 σ는 ReLU 함수이고 input vector x는 ReLU 함수를 한 번 통과했고 bias 는 생략한다.
Identity shortcut은 x의 demension과 y의 demension이 동일할 때 사용한다.
2. Projection shortcut
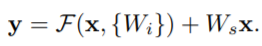
Projection shortcut은 identity shortcut에서 Ws와 x 만 내적해주는 것이다.
Ws 는 square matrix로 단순히 x와 y의 diemension을 맞춰주기 위해 사용한다.
따라서 projection shortcut은 x의 demension과 y의 demension이 다를 때 사용한다.
## ResNet Architecture
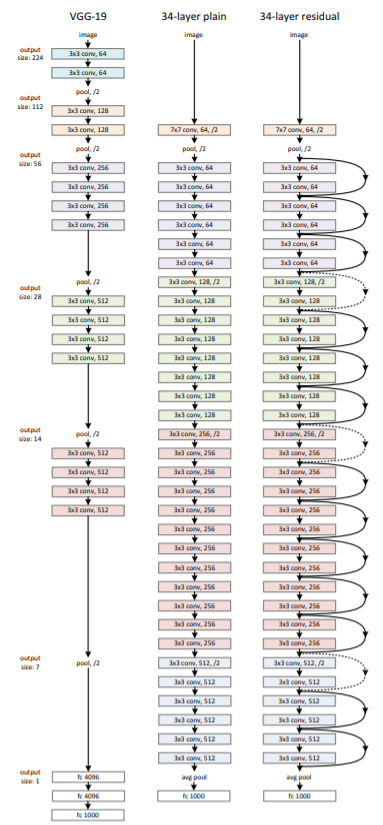
- Plain Network
VGG net을 참고해서 만들었다. 모두 동일한 feature map 사이즈를 갖게 하기 위해서 레이어 들은 동일한 수의 filter를 가지게 한다. 또한 feature map 사이즈가 절반이 되면 filter 수는 2배가 되도록 만들었습니다.
Convolution layer 는 3 x 3의 filter, stride 2로 downsampling, global average pooling layer 를 사용했고, 마지막에는 softmax로 1000-way fully-connected layer를 통과시켰다.
- VGGNet
VGG를 주로 다루지 않으므로 paper 링크로 대신한다.
- Residual Network
Residual Network는 기본적으로 위에서 정의한 Plain Network를 기본으로 한다. Plain Network에 shortcut connection을 도입한다.
그리고 ResNet에선 차원이 증가할 때 두가지 방법을 사용한다.
1. 차원이 상대적으로 작은 쪽의 차원을 늘리기 위해 zero padding 사용. 이 때 추가적인 파라미터는 사용하지 않는다.
2. Projection shortcut 사용 (1x1 convolution 사용)
## Implement
- Image 224x224 cropping
- Batch normalization
- Weight initalization
- mini batch(256) SGD
- iteration : 60x10**4
- weight decay : 0.0001, momentum : 0.9
- No dropout
- learning rate : 0.1 -> local minimalize에 빠질 때 마다 0.1씩 곱해줌(0.1->0.01->0.001...)
## Experiments
Dataset은 ImageNet를 사용하였다.
1. Plain Network vs Residual Network
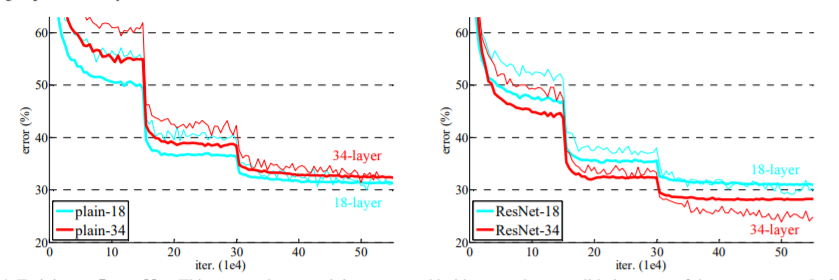
Plain network을 보면 층이 깊어지면(34층) 에러율이 층이 깊지 않은(18층)보다 더 높아진다.
반면에 ResNet은 층이 깊어지면(34층) 에러율이 더 낮아지고 좋은 퍼포먼스를 보인다.
따라서 ResNet의 아이디어 shortcut connection의 효과로 층이 깊어질수록 더 좋은 성능을 낸다는 것을 증명하였다.
2. Identity vs. Projection Shortcuts

- ResNet-A는 차원을 증가시킬 때 zero-padding을 사용하고 기본적으로 Identity shortcut이 들어간 네트워크다.
- ResNet-B는 차원을 증가시킬 때 Projection shortcut을 사용하고 기본적으로 Identity shortcut이 들어간 네트워크다.
- ResNet-C는 차원을 증가시킬 때와 기본 shortcut을 모두 Projection shortcut을 사용한 네트워크다
가장 좋은 성능을 낸 모델은 ResNet-C이다. 그러나 이 모델은 Memory/Time Complexity가 커서 효율적이진 않다.
그리고 ResNet-C와 ResNet-B와 성능 차이가 크지 않으므로 본 논문에선 ResNet-B 방식을 채택한다.
3. Deeper Bottleneck Architectures
Depth가 어느정도 깊어야지 Degradation 문제가 안나는지에 대한 실험이다.
이 때 더 deep 한 모델을 위해 layer를 하나 더 추가한다.

우측 그림은 Building Block으로 layer가 34층인 모델에 사용하고 좌측 그림은 BottleNeck Block으로 50층, 101층 152층에 사용한다.
BottleNeck Block의 첫번째는 1x1 convolution을 하면서 차원을 감소시키고, 3x3 convolution으로 Feature Extract 한다. 그 이후 1x1 convolution을 하여 차원을 증가시킨다.
BottleNeck을 통해 Memory/Time Complexity를 줄일 수 있다.
따라서 결과는 다음과 같다.

Depth가 깊어질 수록 에러율이 적어지는 것을 볼 수 있다.
4. Exploring Over 1000 layers
Dataset은 CIFAR-10을 사용한다.
결과는 다음과 같다
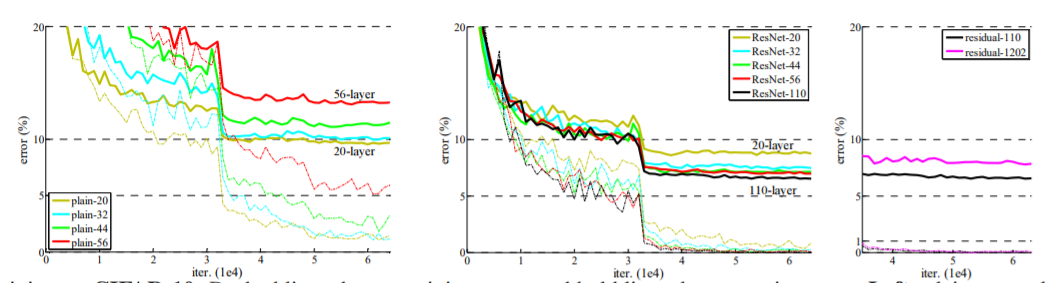
ResNet110과 ResNet1202 를 비교했을 때 ResNet1202의 에러율이 ResNet110보다 높다.
데이터셋의 크기에 비해 layer가 불필요하게 많기 때문에 Overfitting 문제가 발생한다.
하지만 ResNet1202에선 Dropout을 사용하지 않았기 때문에 overfit문제를 해결할 수도 있을 것이다.
5. Object Detection on PASCAL and MS COCO
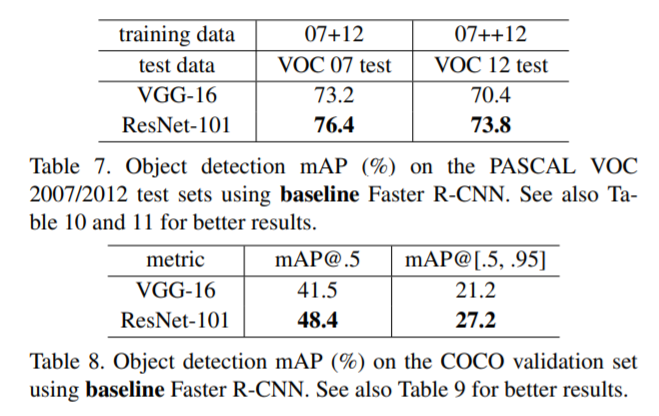
Classification 뿐만 아니라 Detection에서도 좋은 성능을 보여 COCO dataset에서 VGG보다 무려 6%p 높은 성능을 발휘하였다.
'논문 정리' 카테고리의 다른 글
| Generative Adversarial Nets(GAN) (2) | 2021.04.04 |
|---|---|
| Auto Encoding Variational Bayes(VAE) -1 (5) | 2021.03.29 |
| Towards open set deep networks (4) | 2021.01.20 |
| YOLOv5 - training & test (23) | 2020.09.27 |
| YOLOv5 - Introduction (0) | 2020.09.27 |




댓글