이 글은 https://www.youtube.com/watch?v=_sz3KTyB9Lk&list=PLSAJwo7mw8jn8iaXwT4MqLbZnS-LJwnBd&index=12
이 강의를 바탕으로 작성되었다.
## Overfitting Problem
예측 모델에서 model capacity(파라미터 수)가 늘어날 수록 더 복잡한 데이터들을 예측할 수 있다.
그러면 항상 파라미터 수를 많이 늘려서 복잡한 데이터들을 예측하면 되지 않을까? 라는 생각을 할 수 있다. 그러나 이렇게 파라미터 수를 많이 늘리게 되면 한가지 문제점이 생기는데 바로 Overfitting 이다.
Overfitting이란 훈련이 너무 train set에 맞춰져서 test set으로 테스트했을 때 성능이 떨어지는 현상이 발생하는 것이다. 즉, 새로운 데이터가 들어오면 예측을 잘 못하는 현상이다.(=일반적이지 않다.)
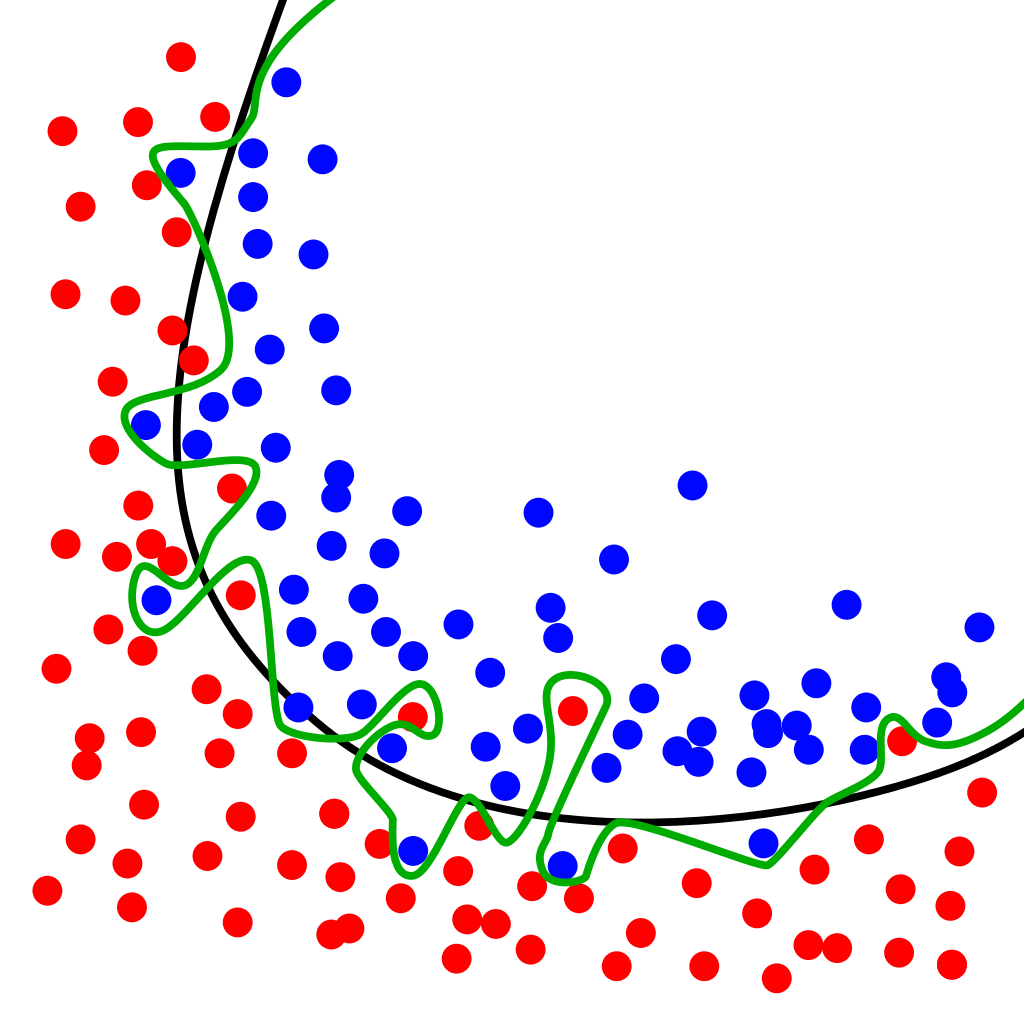
오버피팅을 이해하기 위해선 True Risk 와 Empirical Risk의 개념을 짚고 넘어가야한다.
- True Risk : 일반적인(=모수)와 비교했을 때 얼마나 loss가 많이 나는지(궁극적인 목표)
- Empirical Risk : 일부의 데이터셋(=표본)과 비교했을 때 얼마나 loss가 많이 나는지
따라서 True Risk를 줄이기 위해서 Empirical Risk를 줄여나가는 것이 훈련의 목표이다.
Overfitting을 Risk의 개념으로 정리하면 Empirical Risk는 작아지는데 True Risk는 커지는 것을 의미한다.
따라서 신경망을 훈련할 때, 적절한 Epoch을 조절하고 적절한 capacity를 조절하는 것이 Overfitting을 방지하는 방법이다.
## Regularizations
Rugularization 중 L2 regularization에 대해 알아보겠다.
만약 Loss가 MSE라고 할 때 L2 Regularization은 다음 식과 같다.
$$L = MSE + R(\lambda)$$
$$R(\lambda) = \lambda || w || ^{2} $$
여기서 \( \lambda \)는 얼마만큼 제한할 것인지의 대한 상수를 의미하고 \( ||w|| ^{2} \)는 파라미터들의 크기를 제한하는 것이다. 이러한 식이 왜 overfitting을 줄일 수 있을까?
그림을 통해 설명한다.

예를 들어 \( w_{1}, w_{2} \) 라는 두개의 파라미터만 갖고 있는 식이 있다고 하자. 여기서 파란색 원의 가운데점이 global minmum point 라고 하자.
만약에 L2 norm 항이 없고 MSE로만 훈련한다고 하면 당연히 global minimum point를 향해서 수렴해나갈 것이다. 그러나 당연한 얘기겠지만 이 global minimum이라는 것은 train set에서만 global minimum이지 모든 dataset에서의 global minimum은 아니다. 따라서 다른 데이터셋으로 예측하였을 때 이미 기존에 설정한 global minium으로만 수렴을 하여서 최적의 결과를 내지 못한다.
이제 L2 regularization을 적용해보자. 여기서 빨간색 원을 loss surface라고 할 때, 빨간색 점과 파란색 점을 합쳐서 그 중간값을 global minization 이라고 정의하면 좀 더 일반화된 모델이 될 수 있다.
## Dropout
Dropout은 어떠한 p의 확률로 각각의 노드를 작동안하게 하는 것이다. 이를 그림으로 나타내면 다음과 같다. 즉, weights 값을 아예 0으로 만들어서 노드가 작동하지 않게 하는 것이다.

이렇게 Dropout을 설정하면 강제적으로 파라미터의 수가 줄어들게 된다. 따라서 너무 복잡하게 예측하는 것이 아니라 general 하게 예측하기 위함이다.
두 번째로는 각각의 뉴런을 조금 더 효율적으로 사용할 수 있게 만드는 역할을 한다. 이를 직관적으로 설명하면 노드가 많아지면 훈련이 옆에 노드 (ex. 1,2,3,4,5)가 같은 양을 분산시켜서 훈련한다. 그러나 dropout을 사용하면 노드가 줄어들기 때문에 (ex. 1,3,5) 각 노드마다 더 많은 것을 학습할 수 있게 된다.
따라서 앙상블적인 효과를 얻음으로써 overfitting을 방지한다. (참고로 training 할 때만 dropout 적용, test는 dropout 적용 X)
## Gradient Vanishing
Gradient vanishing 문제는 backpropogation을 할 때 어떠한 값이 0에 가까운 값이 들어오면 편미분하였을 때, 0에 가까워지면서 훈련이 잘 되지 않는 경우를 말한다.
이러한 Gradient Vanishing 문제는 sigmoid function이 가장 잘 일어난다.(0~1 사이)
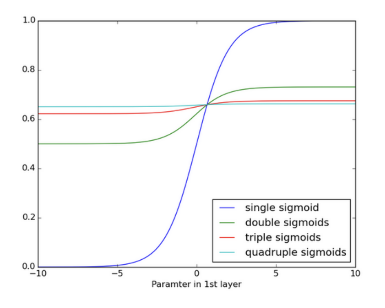
위 그림을 보면 sigmoid function을 4번 곱하였을 때는 거의 변화가 없을 정도의 그래프가 나온다. 따라서 이렇게 sigmoid activation function을 여러번 통과하게 되면 gradient vanishing 문제가 발생한다.
따라서 이를 해결하기 위해서 ReLU activation function이 등장한다. 식은 다음과 같다.
$$ R(z) = max(0,z) $$
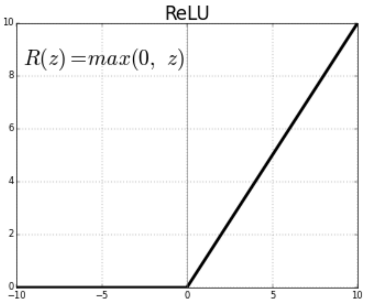
relu는 sigmoid와 달리 0보다 크기만 하면 값이 그대로 전달되는 함수이다. 따라서 이렇게 activation function을 쓰게 되면서 깊은 신경망층이 훈련이 잘 되는 성능을 보였다.
## Xavier initalization
weight initalization 기법 중 하나인 Xavier initalization이다.
만약에 weight initalization을 gaussian distribution에서 random하게 뽑아서 초기화해보자. 그리고 acitvation을 tanh로 해보자. 결과는 다음 그림과 같다.
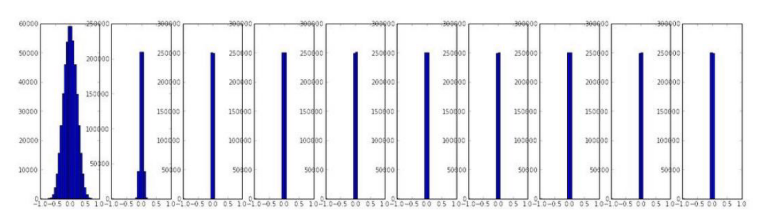
처음에는 gaussian 분포를 잘 따르다가 훈련이 반복되면서 weight가 0에 수렴하는 것을 볼 수 있다. 이러면 훈련이 잘 안되는 문제점이 발생한다.
이러한 문제법을 어떻게 해결할까? 바로 He initalization과 Xavier initalization이다.
간단하게 수식으로 표현하겠다.
- Xavier initalization
$$ W~N(0,Var(W)) $$
$$ Var(W) = \sqrt{\frac{2}{n_{in} + n_{out}}} $$
\( n_{in} \)은 input 노드 수(이전 layer)이고, \( n_{out} \)은 다음 노드 수 이다.
xavier initialization은 비선형함수(sigmoid,tanh) 에서 효과적인 결과를 보여준다.(ReLU X)
- He initalization
$$ W ~ N(0, Var(W) $$
$$ Var(W) = \sqrt{ \frac{2}{n_{in}}} $$
He initalization은 ReLU에 효과적이다.
## Batch normalization
배치 정규화는 배치 단위의 데이터를 정규화 시켜주는 것이다. 그냥 간단하게 설명하면 평균이 0이고 분산이 1이게 batch의 범위를 정규화시켜주는 것이다.
'딥러닝 기초' 카테고리의 다른 글
| Basic of Convolution Neural Network (0) | 2021.08.15 |
|---|---|
| Advanced Optimizer than SGD (0) | 2021.08.14 |
| 코드에서 파라미터 최적화 (0) | 2021.07.28 |
| MultiLayer Perceptron (0) | 2021.07.26 |
| History of DeepLearning (0) | 2021.07.21 |



댓글