KETI에서 쓴 논문이다. 우리나라의 수화 영상 데이터셋을 구축하고, 이를 keypoint 기반으로 번역하는 알고리즘을 구축하였다.
# Abstract
- 본 논문은 Human Keypoint 추정 기반의 SLT(수화 번역) 알고리즘을 제안함
- KETI dataset 소개 (11578 개의 비디오)
- 얼굴, 손, 몸에 대한 keypoint를 추출
- human keypoint vector는 keypoint의 평균과 표준편차로 normalization 수행
- sequence to sequence 모델을 베이스로 번역 진행 ( 모델 설명 : https://blog.naver.com/sooftware/221784419691)
- training 하는 dataset이 작아도 robust한 결과를 얻는다.
# Introduction
- 수화는 특유의 문법이 있다.(표정 몸짓 등을 사용하는)
- 수화 인식 및 번역은 데이터셋 부족으로 문제를 겪고 있다.
- 고려하는 여러 요소가 많다
- 긴급한 상황에 대한 수화로 한정 짓는다
# Related Work
- ASL(미국 수화) 같은 경우 RandomFoest로 알파벳만 인식하는것으론 92% 성능
- 표정(눈살 찌푸림 입 모양 등)과 손 모양과 위치를 이용하여 수화 번역 모델 만들었던 연구 존재
- seq2seq 방식 : 단점 - long-tem dependency 때문에 vanishing gradient 문제 발생
- NMT(Neural Machine Translation) 을 기반으로 target sequnces와 sign video를 형식화 한 연구
- sign video에서 추출한 non linear frame을 CNN을 통해 희소 표현으로 바꾸고 이를 tokenize 함
# KETI Dataset
- 한국어 수화 데이터셋
- 11,578 Full HD resoltuion(1920 x 1080) , 30 FPS, 두 카메라의 다른 각도로 찍음
- 105개의 문장, 419의 단어 사용( 실제론 더 많음)
- 비장애인의 표현 오류를 제거하기 위해 11명의 청각 장애인 수화인이 수행한 문장과 단어를 포함하고 있다.
- 11명의 signer 중 10명의 signer를 training과 validation에 사용. 그리고 9개의 sign video를 선택


- 위급한 상항에서 쓰이는 105개의 수화들을 각각 한국어로 된 5개의 자연어 문장으로 추가 어노테이션 함
- 문장에서 glosses를 추가로 annotation 함
- ex) I am burned 라는 문장에서 (FIRE,SCAR) 라는 단어 annotation. A house is on fire -> (House, Fire)
# Our Approach
- Keypoint 기반의 SLR 제안한다. keypoint 추출은 Openpose로 한다.
- openpose는 총 130개 keypoint 추출 ( 몸에서 18개, 손에서 21개, 얼굴에서 70개)

## Human Keypoint Detection by OpenPose
- Openpose는 사람에 대해서만 동작하기 때문에 다른 배경에서도 견고하다
- 추출된 키포인트의 분산이 무시할 수 있는 수준이기 때문에 인간 키포인트 탐지에 기반한 시스템은 signer와 상관없이 잘 작동
## Feature Vector Normalization
- 훈련할 때 안정성과 속도를 위한 normalization method 에 대한 연구를 많이 함
- Large visual variance가 signer에 따라 크다는 어려운 점이 있음
- keypoint에서 \( V_{x} = (v_{1}^{x}, v_{2}^{x} ... v_{n}^{x}) \), \( V_{y} = (v_{1}^{y}, v_{2}^{y} ... v_{n}^{y}) \) 벡터가 추출된다.
- 이는 각각 keypoint의 x,y 좌표이다.
- 이러한 keypoint 좌표를 다음과 같이 정규화 시킨다.
$$ V_{x}^{*} = \frac{V_{x} - \bar{V_{x}} }{\sigma (V_{x})}$$
- y 벡터도 이와 유사하게 계산한다.
- 이 값을 neural network의 input 값으로 넣는다.
- 하지만 이 137개의 keypoint 값 모두가 필요한 것은 아니다. 따라서 124개의 keypoint만 골라서 넣는다.(하반신 제외)
- 입력벡터의 차원은 248 x |v| 이다.
## Frame skip Sampling for Data Augmentation
- 데이터셋이 작아서 이를 극복하기 위해 random frame skip sampling 기법을 사용한다.
- \( l \) 개의 frame 이 있을 때, \( n \) 번째 frame을 radom으로 선택해서 고정한다. 그리고 차이의 평균적인 길이 z를 계산한다. \( z = \lfloor\frac{l}{n-1}\rfloor \) 그리고 연속적인 프레임에 더해서 Y 값을 계산한다.
$$ Y = (y, y+z, y+2z, ..., y+(n-1)z) where y= \lfloor\frac{l-z(n-1)}{2}\rfloor $$
그리고 이를 baseline sequence라고 한다. 그리고 여기에 임의의 정수 r(1~z)을 더해줌으로써 \( l \) 까지의 범위로 나타내게 된다. 그래서 key 값을 무조건 포함시킬 수 있는 임의의 기준 sequence가 생성되는 것이다.
------???----- 수정 필요-----
## Attention-based Encoder-Decoder Network
- 번역에 유명한 알고리즘인 RNN 베이스(LSTM, GRU)로 encoder-decoder 설정
- input sentence = x vector 이를 이용해 전체 문장을 RNN의 hidden state에 넣으면 순서를 표현하는 고정된 크기의 context vector가 생성된다.
- output vector y 는 RNN encoder에 있는 context vector와 이전의 예측한 단어로 훈련된다. 즉, decoder는 뒤에 나올 단어의 확률을 계산하는 것이다.
### Bahdanau attention
- 고정된 길이의 context vector c는 번역 모델 향상에 bottleneck이 있으며 context vector를 인코더의 hidden states로 부터 관련있는 부분을 자동적으로 계산하는 방식을 제안
- 동적으로 계산된 context vector \(c_{i} \)에 따라 시간 i에 조건부 확률을 정의하는 새로운 모델 제안
- context vector \(c_{i} \)는 encoder에서 hidden state의 가중치 합으로 계산
- alignment function 으로 불리는 score를 통해 encoder와 decoder 각각 두개의 hidden state가 얼마나 일치하는지 계산

### Luong attention
- 기본 attention model과 비슷
- encoder와 decoder에서 상위 RNN 계층의 hidden states만 사용
- t 시점에서 디코더의 hidden state를 계산한 후 attention mastrix를 계산하여 계산 경로 단순화
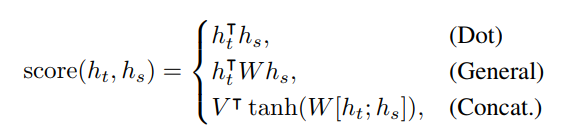
### Multi-head Attention
- Transformer임. (추후에 Transformer에 관한 정리 포스팅을 올릴 예정)
- 1. Encoder - decoder Attention : Decoder는 input sequence에 대해 모두 관여할 수 있다
- 2. Encoder self-attention : encoder에 있는 모든 layer들은 이전 layer의 encoder에 대해 관여할 수 있다
- 3. Decoder self-attention : decoder에 있는 각각의 위치들은 모든 위치에 관여할 수 있다.(decoder 내의)
- Transformer는 재귀와 convolution을 사용하지 않기 때문에 순서에 대한 정보가 필요
## Experimental Results
- 개발환경 : pytorch 사용, epoch = 50, lr = 0.001 20 epoch 마다 스케쥴러 사용, dropout = 0.8
- seq2seq 모델 사용(hidden states = 256)
- 성능 지표 : 정확도(Accuracy) 사용, BELU, ROUGE-L, METEOR, CIDEr 사용
### Setence-level vs Gloss-level
- gloss 번역이 더 낫다.


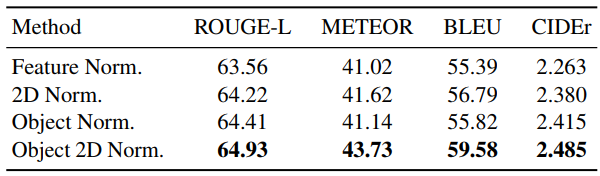
### Effect of feature normalization methods
- 5가지 case 실험 : 1. no normalization 2. feature normalization 3. object normalization 4. 2d normalization 5. object 2d normalization
### Effect of argumentation factor
- augmentation sample의 개수에 따른 지표 변화
- 50이 가장 낫다

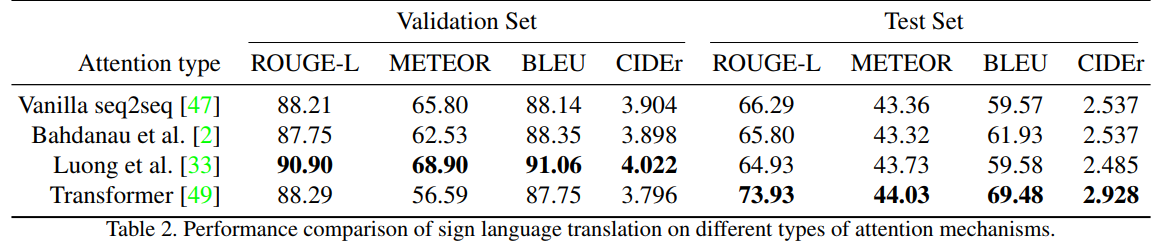
### Effect of attention mechanisims
- 어떤 Attention 방법이 가장 나은지 test
- validation set은 Luong et al. test set은 Transformer
### Effect of the number of sampled frames

- validation은 30개의 sample frame, test set은 50개의 sample frame
### Effect of batch size

### Ablation Study
- 손 / 얼굴 / 몸 의 feature들을 모두 다 이용하는게 나을까? 라는 실험

- Hand 랑 Body만 고려하는게 가장 나았다
내 의견
솔직히 좋은 논문은 아니다.. 그냥 실험에 대한 나열 정도여서 좋은 논문이라고 할 순 없지만 그래도 keypoint 기반의 수화 번역 방식을 제안했다는 것에 대해 좋은 평가를 주고 싶다. 또한 많은 실험을 했다는 것에도 좋은 평가를 주고 싶다.
그러나 데이터셋 활용이 생각보다 적은 점. (아마 하드웨어 문제일 것으로 생각은 된다.) 그리고 end2end 방식이 아닌 점에 대해 논문의 퀄리티에 대해 높은 점수는 줄 수 없다고 생각한다.
그래도 한국의 데이터셋으로 이런 프로젝트를 한 것에 대한 contribution이 좋다고 생각한다.
'논문 정리' 카테고리의 다른 글
| StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery (0) | 2021.11.11 |
|---|---|
| Sequence to Sequence Learning with Neural Networks(Seq2Seq) (0) | 2021.11.01 |
| [STMC] Spatial-Temporal Multi-Cue Network for Continuous Sign Language Recognition (0) | 2021.08.19 |
| 저자가 직접 리뷰하는 YOLOv5 + Optical Flow 보행자 위험 예측 (0) | 2021.08.15 |
| Better Sign Language Translation with STMC-Transformer (0) | 2021.08.11 |




댓글