https://www.youtube.com/watch?v=hFC7DSh9RIw
본 글은 나동빈님의 유튜브를 참조하여 작성하였습니다.
- Base 논문 : StyleGAN (StyleGAN 리뷰)
A Style Based Generator Architecture for Generative Adversarial Networks(StyleGAN)
원 논문 : arxiv.org/abs/1812.04948 A Style-Based Generator Architecture for Generative Adversarial Networks We propose an alternative generator architecture for generative adversarial networks, borr..
bigdata-analyst.tistory.com
- Base 논문 : CLIP
## CLIP의 간단한 소개

특정한 이미지와 Text를 같은 space에 encoding을 시킬 수 있다는 점이다. 즉, 어떠한 이미지와 어떠한 Text가 얼마나 닮아있는지를 판단할 수 있다는 것이다.
여기서 중요한 포인트는 예를 들어 "DOG"와 강아지 사진이 있으면 두 text와 image의 cosine 유사도가 높게 나온다는 점이다.
(CLIP에 대한 논문 리뷰는 따로 포스팅하겠다)
## StyleClip Main IDEA

StyleClip을 한마디로 정의하자면 StyleGAN과 Clip의 Image Encoder와 Text Encoder를 같이 사용한 모델이다.
StyleGAN의 Encoding 과정에 Clip Loss를 추가하여 텍스트로 Style을 바꾸는 작업을 가능하게 만든다.
Latent Vector w로 부터 만들어진 이미지에 semantic embedding 값이 미리 설정한 특정한 텍스트와 유사해질 수 있는 방향으로 Latent vector를 업데이트 하는 것이다.
StyleClip에선 3가지의 방식을 제안한다.
1. CLIP 기반의 로스를 활용하여 최적화 하는 방법을 제안(Gradient Descent로 Latent Vector update)
2. Latent mapper 제안(일종의 Encoder Network) -> Inference Time이 짧다.
3. 적절한 Gloabl Directions을 찾기 위한 방법 제안 -> 어떠한 Latent Vector에서도 곧바로 적용할 수 있는 하나의 방향
## Latent Optimization
Latent Optimization 는 Gradient Descent를 이용하여 특정한 Latent Vector를 업데이트하는 방식이다.
Objective Function은 다음과 같다.
$$ argmin \ D_{CLIP}(G(w),t) + \lambda_{L2} ||w-w_{s}||_{2} + \lambda_{ID}L_{ID}(w) $$
$$ L_{ID} = 1 - \langle R(G(w_s)),R(G(w)) \rangle $$
\( R \) : Pretrained ArcFace Network
\( D_{clip} \) : Cosine Distance between the CLIP embeddings
오른쪽 \( \lambda \) 부터 끝까지의 식은 특정한 이미지를 임베딩하게 사용하는 두가지 식이고, 왼쪽은 CLIP Loss 이다.
Latent Vector를 update 하면서 특정 이미지와 유사한 형태를 갖게 만들면서 그와 동시에 특정한 Text와 유사한 semantic 정보를 갖는 이미지를 얻을 수 있는 방향으로 Latent Vector를 업데이트 하는 것이다.
## Latent Mapper
Encoder Network인 Latent Mapper를 제안하였다. 아키텍쳐는 다음과 같다.
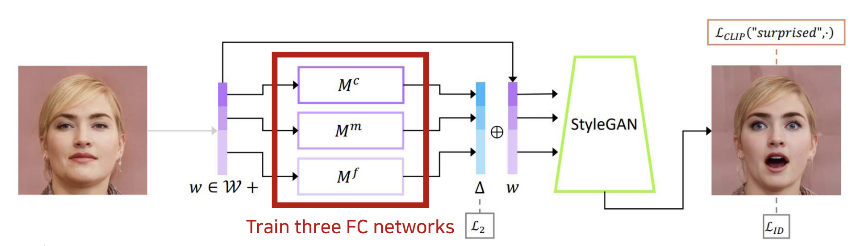
여기서 중요한 점은 각 Mapper 들이 3가지로 분류 된다는 점이다. 각각, coarse, middle, fine style로 구분이 된다. 이렇게 나누면 3개의 스타일을 각각 예측할 수 있게 할 수 있다. 이걸 통해서 스타일의 정도를 지정할 수 있다.
## Global Directions
어떠한 입력이 들어와도 전역적으로 사용이 가능하다는 점이다. 그림을 보고 설명하면 다음과 같다.

'Makeup' ,'Hi-top Fade'와 같은 input text가 들어오면 그에 따른 vector directions 방향으로 이동하기만 하면 원하는 스타일을 곧바로 적용할 수 있다는 점이다.
간단한 핵심만 본 리뷰였다.
'논문 정리' 카테고리의 다른 글
| HVPS : A Human Video Panoptic Segmentation Framework (0) | 2022.05.30 |
|---|---|
| MOTS : Multi-Object Tracking and Segmentation (0) | 2022.05.30 |
| Sequence to Sequence Learning with Neural Networks(Seq2Seq) (0) | 2021.11.01 |
| Neural Sign Language Translation based on Human Keypoint Estimation (0) | 2021.09.16 |
| [STMC] Spatial-Temporal Multi-Cue Network for Continuous Sign Language Recognition (0) | 2021.08.19 |




댓글