## Abstract
MOT(Multi Object Tracking) 과 Segmentation을 합쳐서 픽셀 단위의 tracking을 이뤄내는 논문이다.
이를 위해 새로운 annotation을 이뤄냈다.
평가를 위해 새로운 MOT의 metric에서 확장을 하였다.
본 논문에선 단일 모델을 통해 Detection + Segmentation + Tracking을 하는 모델 제안한다.
## Introduction
현재 Segmentation과 Tracking은 좋은 성능을 보이지만 MOT에 관해선 여전히 어려운 문제가 있다. 특히, Bounding Box 단위로 detection 및 tracking을 할 땐 occulsion 때문에 coarse(조잡한) 경향이 있다.( 객체가 부분적으로 가려져서 다른 객체의 정보로 인해 손실될 수 있기 때문 )
따라서 본 논문에선 bounding box 단위가 아니라 pixel 단위로 instance segmentation을 하는 MOTS(Multi-Object Tracking and Segmentation)을 제안한다.
본 논문에선 MOTS 작업의 모든 측면을 다루는 기본 방법으로 Track R-CNN을 제안한다.
Track R-CNN은 Mask-RCNN을 시간 정보를 통합하고 시간이 지남에 따라 re-identification에 사용되는 연결 헤드에 의해 3d-convolution으로 확장한다.
따라서 본 논문의 contribution은
- 새로운 두가지 데이터셋을 만듦: Tracking 정보와 Segmentation 정보가 포함된 KITTI와 MOTChallenge Dataset.
- 새로운 평가지표 제안 : sMOTA(soft multi object Tracking and Sengmentation). -> 새로운 task에 대해 모두 평가할 수 있는 지표
- TrackR-CNN 모델 제안 : Detection + Tracking + Segmentation
- 시연해서 검증함
## Related Works
(생략)
## Datasets

## Evaluation Measures
기존에 활용된 Tracking metric 에 있어선 CLEAR MOT metric(MOTA)을 적용한다. 그런데 Segmentation 의 pixel mask GT값도 잘 고려되야한다. 따라서 객체의 GT값과 MOTS 방법으로 생성된 마스크는 모두 겹치지 않아야한다.
따라서 이를 고려한 MOTS 의 새로운 평가지표를 제안한다.
### 변수 정의
- \(T\) : frame time
- \(h\) : height
- \(w\) : width
- \(N\) : object 개수(GT)
- \(m\) : mask(GT)
- \(M\) : mask set(GT)
- \(id\) : 객체 아이디
- \(h_K\) : mask (predict)
- H : mask set (predict)
- K : object 개수(Predict)
### Establishing Correspondences (예측 얼마나 잘했는지)
Segmentation 할 때 IoU가 0.5를 겨우 넘는 수준이기 때문에 Bounding Box보다 IoU가 높게 나오기 힘들다.
GT와 Predict mask의 IoU에 따라서 \( c(h) \) 로 나타냄. 즉, IoU(h,m) > 0.5 일 때 IoU max 값으로 c(h) 설정. 그 밑에면 공집합 처리

이를 이용하여 TP,FP,FN 정의
TP : True Positive \( \{ h \in H | c(h) \neq \emptyset \} \)
FP : False Positive \( \{ h \in H | c(h) = \emptyset \} \)
FN : False Positive \( \{ h \in H | c^{-1}(m) = \emptyset \} \)
동일함의 기준 = mask뿐만 아니라 gt id와 pred id도 동일해야한다.
ID switching 평가 지표는

저기서 \( \wedge \)는 and를 의미. 높을수록 좋지 않은 것.
### Mask based evaluation measures
MOTA 기반
- soft version TP ( True Positive 개수 )
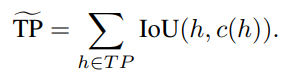
- MOTSA ( Multi-Object Tracking and Segmentation Accuracy)
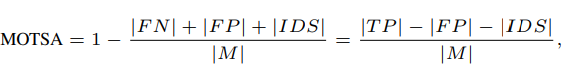
여기서 M은 GT mask의 길이이고 " | | " 표시는 length of set을 말하는 것
- MOTSP (Multi-Object Tracking and Segmentation Precision)

- sMOTSA (soft Multi Object Tracking and Segmenation Accuracy)

## Method

Mask R-CNN 기반으로 구축. 3d convolution layer에 의해 mask-rcnn 확장.
### Integrating temporal context
Resnet-101로 feature extraction 하고 3D convolution layer(시간축도 확장)로 feature 통합. 그래서 temporally enhanced image feature 뽑은 담에 이걸 RPN에 넣음. 여기서 RPN 대신 Convolutional LSTM 도 고려. (대신 얜 행렬곱 대신 convolution 연산함)
### Association
시간이 지남에 따라 detection을 할 수 있도록 FC 로 mask r-cnn 확장. 여기서 FC는 region proposal을 input으로 받고 연관 벡터를 예측하기 위함.
같은 instance에 속하는 벡터는 서로 가깝고, 다른 instance에 속하는 벡터는 멀리 떨어져 있도록 훈련하는데, 이때 euclidean 거리로 측정한다.
Hermans et al의 batch hard triplet loss로 훈련. 이 loss는 각 detection에 대해 hard positive와 hard negative sampling함.

여기서 \( D \)는 video의 detection 집합. \( mask_d\)와 \(a_d\)는 mask와 association vector를 나타냄.
이는 같은 아이디를 가질 때 두 벡터의 거리의 최대값 - 다른 아이디일 때 두 벡터의 거리 최솟값 + \( \alpha \)의 최대값의 summation 의미
## Mask Propogation
PWC-Net 이용하여 optical flow 계산

여기서 W 함수는 Warping 함수 말함. 즉, \( mask_d \) 에 대해서 t-1 과 t frame의 optical flow를 의미.
## Tracking
유클리디안 distance 기반으로 tracking 수행. 기존 MOT 논문과 유사.
## Experiments
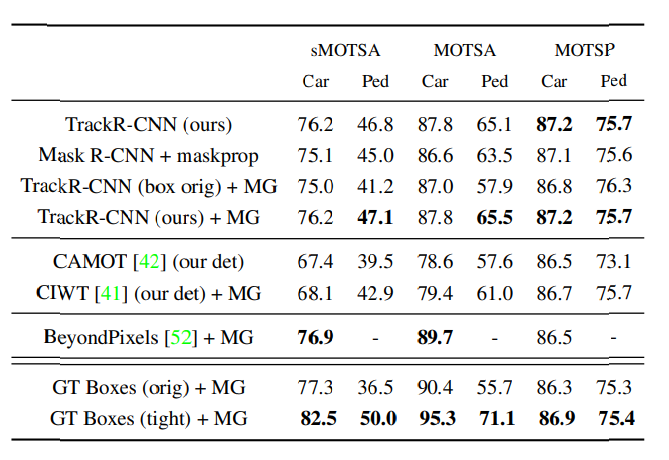

'논문 정리' 카테고리의 다른 글
| Image Generation 정리(1) (0) | 2022.06.19 |
|---|---|
| HVPS : A Human Video Panoptic Segmentation Framework (0) | 2022.05.30 |
| StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery (0) | 2021.11.11 |
| Sequence to Sequence Learning with Neural Networks(Seq2Seq) (0) | 2021.11.01 |
| Neural Sign Language Translation based on Human Keypoint Estimation (0) | 2021.09.16 |




댓글