https://www.youtube.com/watch?v=4DzKM0vgG1Y
나동빈님 유튜브를 바탕으로 리뷰하였습니다.
Seq2Seq는 현재 Transformer에 밀려 잘 사용되진 않지만 NLP의 기초를 공부하기 위해서 이 논문을 리뷰한다.
## seq2seq
seq2seq 모델은 LSTM을 활용한 효율적인 seq2seq 기계번역 아키텍쳐이다. 기존(seq2seq가 나오기 전)엔 딥러닝을 활용한 기계번역보다 통계적인 방법을 활용한 번역을 더 많이 사용하였다. 그러나 seq2seq 가 나옴으로써 딥러닝을 활용한 기계번역 연구에 불을 지폈다.
seq2seq의 간단한 동작 과정은 다음과 같다.
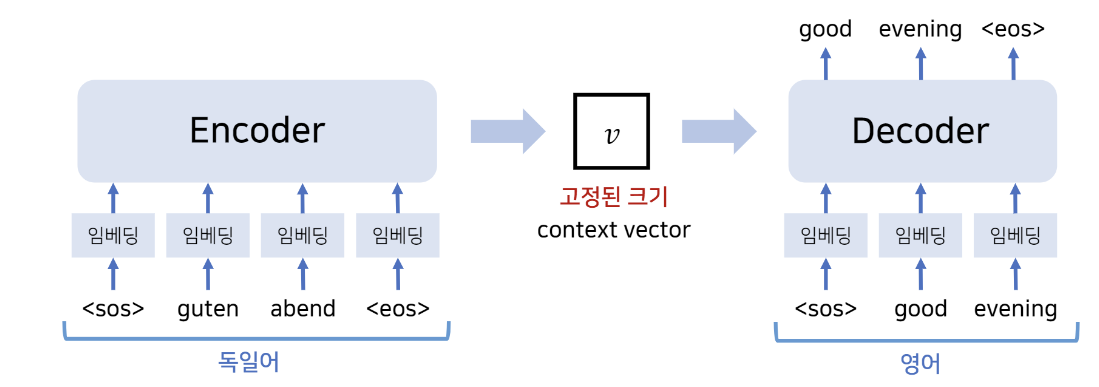
encoder와 decoder로 구성이 되어있고 context vector \(v\)를 활용한다.
seq2seq는 하나의 sequence(문장)에서 다른 sequence(문장)으로 번역을 하겠다라는 의미이다. 여기서 문장은 여러개의 단어로 구성되어 있다. 이 단어 각각은 하나의 토큰(token)으로써 생각을 한다.
따라서 다시 정리하자면 이러한 token(단어)들이 모인 것이 sequence(문장)라고 생각하면 된다.
- Encoder의 간단한 동작과정은 다음과 같다. input 문장(여기선 독일어)을 RNN과 LSTM 같은 sequential한 모델에 들여보내서 하나의 context vector를 만들어낸다.. 여기서 token 들을 순차적으로 딥러닝 모델에 들여보내는 것이다.
즉, 하나의 sequence가 들어갔을 때 encoder에선 입력 sequence를 표현할 수 있는 하나의 vector를 만드는 것이다.
- Decoder에선 context vector에 담겨있는 의미들을 target output 언어로 뱉어내는 과정이다.
Seq2Seq에서의 특징은 context vector의 크기가 고정되어 있다는 점이다. 이로 인해 context vector에 input 문장에 대한 문맥 정보를 잘 담지 못한다면 번역성능에 영향을 끼친다. 따라서 이는 일종의 bottleneck 현상이 발생할 수 있다는 것이다.
## seq2seq가 중요한 이유
seq2seq를 기점으로 Transformer나 Bert, GPT 등의 모델이 나오게 되고 기계번역은 비약적인 향상을 이루게 된다. 그래서 이러한 모델들을 이해하려면 이 모델들이 어떤 문제를 풀어나가서 기계번역의 성능을 올렸는지 알아야한다.
seq2seq는 기계번역의 초기 모델로 기계 번역 모델들의 모든 논문들에서 base논문으로써 잘 알아야한다.
## 언어 모델(Language Model)
기계 번역에선 확률값에 기초해 문장을 번역한다. 예시를 보고 설명하겠다.
$$ P(난 널 사랑해 | I love you) > P(난 널 싫어해 | I love you)$$
다음과 같은 수식은 I love you 라는 문장이 있고 한국어에 "난 널 사랑해", "난 널 싫어해" 라는 두 문장이 있다고 하자. 이럴 때 두 문장 중 I love you를 한국어로 번역할 때 "난 널 사랑해"로 번역하는 것이 "난 널 싫어해"로 번역하는 것 보다 의미가 맞을 확률이 높다는 것이다.
이와 같은 확률 개념은 다음 단어 예측을 할 때도 사용이 된다.
$$ P(먹었다 | 나는 밥을) > P(싸웠다 | 나는 밥을) $$
이도 위 예시와 마찬가지로 "나는 밥을" 이라는 문장 다음에 어떤 단어가 나올 지에 대해 "먹었다"가 "싸웠다"보다 더 높은 확률로 뒤에 나오는 것을 의미하는 식이다.
이를 좀 더 일반적인 식으로 나타내면 다음과 같다. 문장은 W라 하고, 단어는 w라고 했을 때, 문장의 확률은 다음과 같이 나타나진다.
$$ P(W) = P(w_{1},w_{2},w_{3},w_{4}...w_{n})$$
이는 여러개의 단어가 한꺼번에 등장할 확률을 의미한다. 즉, 익숙한 개념으로 환산하자면 joint \( \cap\)과 같은 것이다. 이를 joint problem probability 라고 부른다.
이는 베이즈 정리에 의하여 다음과 같이 Chain Rule이 적용된다.
$$ P(w_{1},w_{2},w_{3},w_{4}...w_{n}) = P(w_{1}) * P(w_{2} | w_{1}) * P(w_{3} | w_{1},w_{2}),...,P(w_{n} | w_{1},w_{2}...,w_{n-1})$$
이를 수식적으로 간단하게 나타내면
$$ \prod^{n}_{i=1} P(w_{i} | w_{1},...w_{i-1}) $$
로 나타내진다.
전통적인 통계적 언어 모델은 이러한 수학식을 사용하여 count 기반의 접근을 사용한다. 다음과 같은 식처럼 나타내진다.
$$ P(rice | I eat) = \frac{count(I eat rice)}{count(I eat)} $$
하지만 이러한 방법은 매우매우 방대한 양의 데이터가 필요하고 사전이라는 데이터 베이스 안에 "I eat"이라는 시퀀스 자체가 없으면 소용이 없는 방법이다. 또한, 긴 문장의 처리는 어려운 방법이다.
긴문장 처리를 위해 인접한 단어 일부만 고려하는 아이디어 N-gram 언어 모델이 등장을 한다.
## 전통적인 RNN 기반의 번역 과정
RNN 기반의 언어 모델은 input 과 output의 크기가 같다고 가정한다.

위 그림은 (나는 - I), (네가 - miss) (그리워 - you) 이런 식으로 각각 단어가 매핑되게 하는 것이다.
여기서 RNN의 input, output, hidden 식을 잠깐 살펴보면 다음과 같다.
input : \( (x_{1},...,x_{T}) \) , output : \( (y_{1},...,y_{T}) \) 일 때, (이 떄, T는 seq의 단어 개수)
\( h_{t} = sigmoid(W^{hx} x_{t} + W^{hh}h_{t-1} \)
\(y_{t} = W^{yh}h_{t} \)
hidden state는 기존까지 입력 되었던 데이터에 대한 전반적인 정보를 의미한다.
hidden state 에 대해서 그림과 연관지어 설명하자면 \(h_{0} \) 라는 지금까지 들어오는 문장의 정보와 새로 들어오는 \( x_{1}\)의 문장 정보를 조합해서 \(h_{1}\) 이라는 값을 return 해준다. 여기서 \( h_{1} \)은 \( x_{1} \) 값인 '나는'에 대해서만 정보를 가지게 된다. 그리고 이전까지에 대한 단어에 대한 정보를 모두 포함하고 있는 \( h_{1} \) 을 다시 RNN state에 넣고 여기서 \(x_{2} \)를 넣어준다. 그러면 \( x_{2} \) 에 정보도 학습하게 된다. 이러한 과정을 반복한다.
하지만 이런 RNN 방식은 앞서 언급한 것과 마찬가지로 문제점이 있다.
첫번쨰로 input 과 output의 길이가 같아야한다는 점에서 현실세계에 적용하기 힘들다는 것이다.
두번쨰로 input 언어와 output 언어의 문법이 다르면 문제가 생긴다는 것이다. 일례로 한국어는 S+O+V 의 형태라면 영어는 S+V+O의 형태여서 매핑되어서 예측하는 방식에서는 번역이 힘들다는 점이 있다.
## Seq2Seq의 Outline
- RNN의 단점을 해결하기 위해 Encoder가 고정된 크기의 context vector를 추출
- context vector로 부터 Decoder가 번역 결과 추론
- LSTM을 이용해 context vector를 추출하도록 하여 성능을 향상시킴(Encoder의 마지막 hidden state만을 context vector로 사용)
- Encoder 와 Decoder는 서로 다른 weight 를 가진다.
## RNN 기반의 Sequence to Sequence Architecture
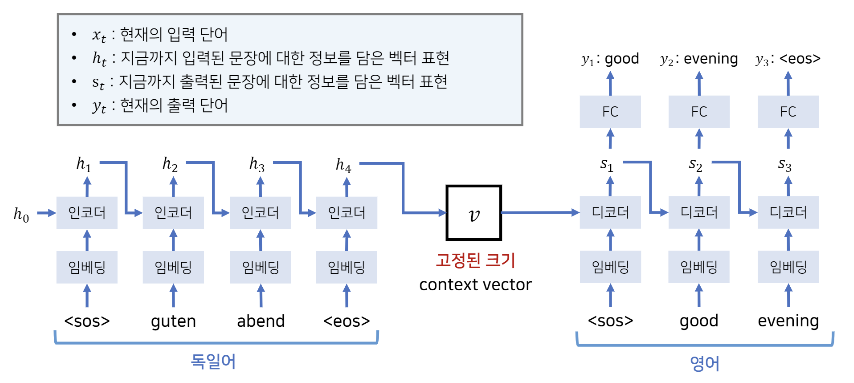
여기서 모델에서 Embedding Layer를 주로 거친다. 이러한 이유는 예시를 통해 설명하겠다.
만약 독일어에서 가장 많이 등장하는 빈도 수가 높은 단어가 약 2만개 정도라고 가정하자. 이러면 2만 차원으로 늘려야하는데 이는 현실적으로 불가능한 일이다. 따라서 이러한 차원을 상대적으로 줄이기 위해 임베딩 레이어를 사용한다.
그림을 보면 직관적으로 알 수 있겠지만 마지막 hidden layer \( h_{4} \)를 context vector로 사용하여 decoder 부분에 넣어서 번역을 수행하는 것이다.
이러한 seq2seq의 formulation은 다음과 같다.
$$p(y_{i} ... y_{T'} | x_{1},...x_{T}) = \prod^{T'}_{t=1} p(y_{T} | v,y_{1},...y_{t-1}) $$
여기서 \( v \)는 \( x_{1}...x_{T} \) 에 대한 정보를 담은 벡터를 표현한 것이고 \( y_{t}\)는 현재의 출력 단어를 의미한다.
이 모델의 종료 시점은 결과가 <eos> (end of sequence) 이면 종료한다. context vector가 decoder 로 들어가서 예측을 하는데 이 결과값이 <eos> 이면 종료하는 방식이다.
위 식에서 인상적인 부분은 입력( \( x_{1} ... x_{T} \) )과 출력( \( y_{1} ... y_{T'} \) )의 길이가 달라도 된다는 것이다.
## Seq2Seq 성능 개선(LSTM + 입력 문장 순서 뒤집기)
기본적인 RNN 대신에 LSTM을 활용하였을 때 더 높은 정확도를 보이고 학습 및 테스트 과정에서 입력 문장의 순서를 뒤집었을 때, 더 높은 정확도를 보인다. ( 단, 출력 문장의 순서는 뒤집지 않음)
문장을 뒤집는 논리는 다음과 같다. "일반적인 언어 체계에서 앞쪽에 위치한 단어끼리 연관성이 높다."
이를 이용해서 앞쪽에 나오는 주어를 뒤집어서 맨 뒤로 가게 한 후, 이 맨 마지막에 있는 주어에서 나오는 단어 정보를 context vector로 활용하는 방식이다.
'논문 정리' 카테고리의 다른 글
| MOTS : Multi-Object Tracking and Segmentation (0) | 2022.05.30 |
|---|---|
| StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery (0) | 2021.11.11 |
| Neural Sign Language Translation based on Human Keypoint Estimation (0) | 2021.09.16 |
| [STMC] Spatial-Temporal Multi-Cue Network for Continuous Sign Language Recognition (0) | 2021.08.19 |
| 저자가 직접 리뷰하는 YOLOv5 + Optical Flow 보행자 위험 예측 (0) | 2021.08.15 |




댓글