Panoptic Segmentation : Instance Segmenation + Semantic Segmentation
- Instance Segmentation : Object 대로 사진 분할( 객체의 아이디가 존재)
- Semantic Segmentation : 의미대로 사진 분할 ( 객체의 아이디가 존재하지 않음 ) , 배경포함
- Panoptic Segmenation : 의미대로 사진을 분류하고 (배경 포함) 거기에 있는 Object들의 id도 부여해서 pixel 단위로 segmentation 수행

https://motchallenge.net/workshops/bmtt2021/reports/motcha_uw_etri.pdf
# Introduction
본 모델은 두가지 step으로 진행된다.
1. 객체(사람) tracking and segmentation -> 2. 배경 semantic segmentation
MOTS(Multi-Object Tracking and Segmentation) 을 통해 비디오의 각각의 instance에 대하여 object mask 예측
여기서 본 논문에선 강력한 embedding feature extractor 제안 - 시공간적 attetion 을 이용 (Temporal Attention + Spatial Attention)
그 후 헝가리안 알고리즘을 이용하여 object 추적.
Evaluation metric : STQ(Segmentation and Tracking Quality)
# Related Works
1. MOTS
2. Video Panoptic Segmentation
이 두 차이는 아직 모르겠음
# Proposal Framework
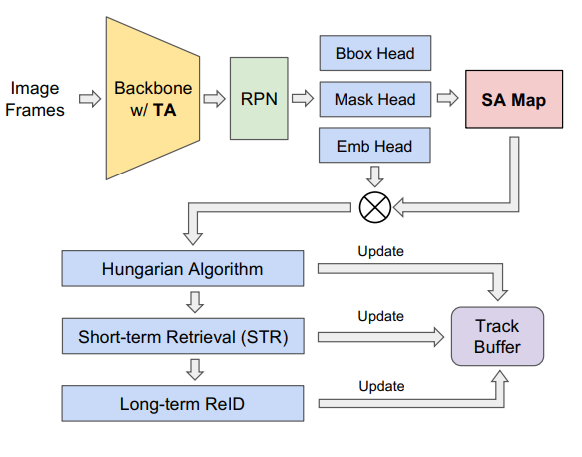
2가지 파트로 나뉨 : human tracking and segmentation, background segmentation.
## Human Tracking and Segmentation
2-stage CNN object detector(multi-task head 기반) 사용. 이는 video clip 에 대한 시공간적 특성을 강조하여 BB regression과 mask generation, Object Classification, instance-aware embedding 따로 하기 위함.
### Temporal Attention
video clip의 prediction을 원활하게 하기 위한 정보 수집과정
FPN을 사용해서 추출한 3개의 프레임의 feature들을 사용.
TA(Temporal Attention) module 각 피라미드 레벨에 대한 pixel 단위의 attention map 학습하고 weight 계산
3개의 frame에서 추출한 feature들을 모은담에 3d convolution해서 feature aggregation 함. 이때, Softmax를 통해 TA map생성.
### Spatial Attention
Bounding Box에서 모호하고 관련없는 특징 제거하는 역할.
foreground 강조하고 background 영향 줄임.
feature는 2d convolution layer를 통과하고 SA map 생성. SA map은 객체의 확률 정보 담겨있음( 객체일 확률 몇 % 이런거)
중간에 convolution 해서 object mask도 생성.
### Tracking
LaMot 기반 Tracking. short-term과 long-term 고려하는 re-identification 수행.
일치하는 Track은 new detection으로 update.
일치하지 않는 것은 현재 트랙과 결합없이 short term retrieval module로 보내진다.
IoU와 distance는 tracking 중 다른 제약 조건으로 간주됨.
이후에 Re-Identification 했을 때 끊어진 track을 다시 연결하여 IDS(ID switch) 줄일 수 있음.
### Semantic Segmentation
EfficientPS 사용
2-stage object segmentation branch와 semantic segmentation branch를 결합함으로써 최종적인 panoptic segmentation 이 생성됨.
여기서 semantic branch는 Feature Pyramid Network(FPN) 사용해서 feature 결합함.
본 논문에선 KITTI로 pretrained 된 가중치 사용. 그리고 MOTChallenge 에 맞춰서 fine-tunning 함.
## Evaluation
STEP 논문 참고 ( https://arxiv.org/pdf/2102.11859.pdf )
PQ ( Panoptic Quality)

AQ(Association Quality)

SQ(Segmentation Quality)

STQ(Segmentation and Tracking Quality)

'논문 정리' 카테고리의 다른 글
| Image Generation 정리 (2) (0) | 2022.06.23 |
|---|---|
| Image Generation 정리(1) (0) | 2022.06.19 |
| MOTS : Multi-Object Tracking and Segmentation (0) | 2022.05.30 |
| StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery (0) | 2021.11.11 |
| Sequence to Sequence Learning with Neural Networks(Seq2Seq) (0) | 2021.11.01 |




댓글