원 논문 : arxiv.org/abs/1812.04948
A Style-Based Generator Architecture for Generative Adversarial Networks
We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identit
arxiv.org
참고 링크 :
www.youtube.com/watch?v=HXgfw3Z5zRo&t=2692s
갓동빈님의 강의를 한번 듣고나니 너무 빠져들어서...갓동빈님의 강의를 또 다시 참고하였다.
이번에 리뷰할 논문은 StyleGAN 이다. 이 논문은 CVPR2019에 개제된 논문이며 무려 NVIDA 팀이 만들었다...거기도 외계인 집단인거 같다..너무 똑똑한듯... 암튼 StyleGAN은 현재 StyleGAN2 까지 발전하였고 네이버팀에서도 StyleGAN 기반의 StyleMap GAN 논문을 CVPR2021에 낼 정도로 GAN 계열의 큰 영향을 주고 있는 논문이다.
StyleGAN은 한마디로 정리하자면 고화질 이미지에 적합한 아키텍쳐를 제안하는 것이다. 거기에 다양한 특징들이 잘 분류되게 만든다.
StyleGAN의 Contribution은 Disentanglement(다양한 특징(안경, 머리색)들이 잘 분류되어 있는 것)라는 특성을 향상 시켰고, FFHQ라는 고해상도 얼굴 데이터셋을 발표하였을 뿐더러 새로운 성능 지표를 제안한다.
Abstract
GAN이라고 알려진 분야는 Generator와 Descriminator를 동시에 학습하는 방식으로 하나의 Generator를 학습하는 방식으로 이뤄진다. 본 논문에선 Generator에 초점을 맞추어서 효과적으로 고효율의 Generator를 생성하는 것에 초점을 맞춘다. 기존에 알려진 style transfer를 이용하여 효과적으로 이미지를 구성하는 다양한 이미지를 생성할 수 있는 방법을 제안한다.
본 논문의 가장 큰 특징은 고해상도의 다른 사람들의 이미지에서 각각의 style을 이용하여 여러개의 특징들을 조합하여 생성할 수 있는 것이다. 여기서 각각의 특징을 하나의 파라미터로 컨트롤 할 수 있게한다.
즉, 논문에서 생성하는 이미지는 여러개의 style이 합쳐진 이미지라는 것이다.
두번째로 본 논문에선 여러가지 확률적 다양성을 고려한다.(ex.바람이 불면서 머리가 바뀌는 그런 것들)
본 논문은 PGGAN의 성능을 개선시킬 수 있었고 Fid(GAN 성능 평가 지표)를 이용했을 때도 SOTA 달성을 이뤄냈다.
Introduction
GAN 논문이 나온 이후에 여러 가지 이미지 생성 분야가 연구가 되었다. PGGAN에 한계를 언급하면서 고해상도 이미지에서 생성의 어려움을 말하고, 그리고 각 이미지의 style을 조합하는 연구에 대해서도 미비하다고 문제점을 언급하였다.
본 논문은 이를 개선하기 위해 연구하였고 style-transfer라는 논문에 아이디어를 얻어서 생성자 네트워크 구조를 개선하였다.
본 논문에선 뒤에서 설명하겠지만 학습된 하나의 상수로부터 여러개의 block을 거쳐가면서 해상도가 점점 커지게 되고 채널은 감소한다. 이 때, block 안에 있는 convolution layer에 각각의 style을 입력받게 하면서 다양한 style을 입력받을 수 있게 한다. 또한, stochastic variation도 control 할 수 있게 된다.Generator network의 수정에 초점을 맞추고 loss function과 Descriminator는 기존에 연구되어져 왔던 방식을 차용한다.
latent vector가 가우시안 분포를 따르게 될 때 entanglement 될 수 밖에 없다고 언급을 하고 이를 개선하기 위해 intermediate latent space를 mapping한 후에 이를 input 으로 사용하면 disentanglement되면서 더욱 좋아진다고 한다.
마지막으로 FFHQ(고해상도 얼굴 데이터셋)을 공개한다.
Style-based Generator
본 논문에선 하나의 학습된 상수를 생성자의 입력으로 넣어주고 convolution을 거치면서 style의 정보를 반영할 수 있게 한다.(기존엔 latent vector를 입력했어야만 했다)
따라서 본 논문은 다음과 같은 방식을 따른다.
f: z -> w z : latent vector, w : latent vector z를 FC 네트워크를 거친 vector
w vector를 input으로 들어가게 한다.

위 그림은 모델의 전체적인 아키텍쳐인데 latent z를 정규화 한 뒤 mapping network 를 거쳐서 새로운 latent vector w를 만든다. (z,w vector는 512 shape를 따름) 그리고 만든 w vector를 input으로 넣어서 별도의 Affine Transform을 거치게 만든다. 이러한 변환을 거친 것은 하나의 style로 들어가게 되고 Block 안에서 연산을 하면서 style을 반영하게 된다. 또한, Block 안에서 noise라는 Stochastic variation을 넣어주면서 확률적인 상황(피부 컨디션, 주근깨 등)을 극복하려 하였다.
위 그림에서 Style을 학습할 때 AdaIN이라는 하나의 noramlization layer를 쓰는데 하나의 feature에 대한 statistic을 바꿀 수 있게 한다. 즉, scaling과 bias를 적용하면서 convolution 연산을 통해 얻은 feature의 통계적인 특징을 변화시키는 역할을 하는 것이다.
Mapping network는 8개의 layer로 구성되어 하나의 512 latent vector z를 또 다른 하나의 512 shape의 latent vector w를 생성시키는 역할을 한다.
Generator는 18개의 layer로 구성되고 9개의 block이 존재한다.(4x4 에서 1024x1024로 단계적으로 upscaling)
마지막엔 RGB 형식으로 나올 수 있게 3 channel의 tensor를 만들게 한다.(a.k.a toRGB layer)
## AdaIN
AdaIN 방식은 StyleGAN에서 다른 데이터로부터 style 정보를 가져와 적용하는 역할을 한다.
AdaIN 방식의 큰 특징은 학습시킬 파라미터가 필요하지 않다는 것이다. 즉, gamma와 beta를 사용하지 않는 것이다.
이 AdaIN 방식은 Instance 단위로 Norm을 수행한다.

이러한 방식으로 feed-forward 방식의 style Transfer에서 좋은 성능을 낼 수 있었다.

여기서 x_i는 feature map이고 이를 normalization을 한다. 또한 여기에 style y에 scaling과 bias를 적용을 하는 것이다.
최종적으로 이와 같은 방법을 적용한 결과는 다음과 같다.
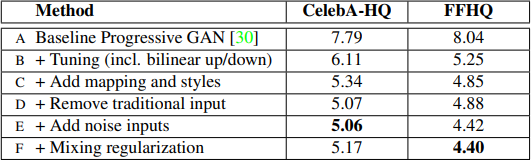
이 테이블의 성능 지표는 FID(Frechet inception Distance)를 사용하였고 이는 생성자의 퀄리티를 측정하기 위한 전통적인 GAN 측정 지표이다.
본 논문은 PGGAN을 베이스라인으로 잡고 조금씩 방식을 추가하여 성능을 향상시킨 것을 볼 수 있다. 여기서 F는 논문에서 제안한 모든 기법들을 합친 것이라고 볼 수 있다.(F = A+B+C+D+E + Mixing regularization)
추가한 기법들을 간단히 요약하자면 다음 표와 같다.
| Method | Description |
| B(Tunning) | interpolation = bilinear 사용, long training time, hyperparameterter tunning |
| C(Add mapping style) | mapping Network + AdaIN |
| D(Remove traditional input) | 학습된 상수 tensor(4x4x512)를 input으로 사용 |
| E(add noise inputs) | Stochastic variation 추가 |
| F(mixing Regularization) | 인접한 layer 간의 상관관계를 줄이기 위한 방법 |
loss function = WGAN-GP 사용하였다. 기존에 널리 사용하는 loss function 이다.(참고 링크 : leechamin.tistory.com/232)
이러한 StyleGAN을 적용한 결과는 다음 사진과 같다.

진짜 GAN 논문 보면서 항상 놀라지만 진짜 어딘가에 존재할 것 같은 이미지들이다..아무튼 고해상도의 이미지에서도 거의 완벽에 가깝게 이미지를 생성하는 것을 볼 수 있다. 물론 이 때 생성할 때,truncation trick 기법을 사용하였는데 이는 이미지를 생성할 때 그럴싸한 이미지가 나올 수 있도록 평균에 가까운 이미지가 나오게 w latent vector에 truncation을 적용한 것이다.(성능 측정할 땐 말고 좋은 결과 이미지가 나오게 할 때 사용)
※ truncation trick
학습이 완료된 네트워크의 input을 제어하는 방법으로 생성자가 이미지를 더 잘 뽑아낼 수 있게 만드는 기법
sampling을 수행할 때 가능한 densitity가 높은 곳에서부터 sampling을 수행하게 만드는 기법

위 식에서 w_bar는 이미지(=얼굴)의 평균 값이라고 생각하면 된다.
가장 핵심은 ψ이다. ψ는 항상 1보다 작은 값인데 ψ를 1로 설정하면 truncation trick을 사용하지 않은 경우이고, ψ가 0이면 모두 다 같은 얼굴이 나오게 된다. 본 논문에선 ψ 값을 0.7로 설정하였다.
Properties of the style-based generator
각각의 스타일은 convolution에 의해 수행되고 다음 AdaIN 연산으로 style을 덮어 씌울 수 있다.
본 논문에선 style을 더 지역화를 잘 시키기 위해 mixing regularization 방법을 수행한다.
이 방법은 학습을 진행할 때 두개의 latent vector를 서로 섞어서 이미지를 만드는 것이다. 이 때 섞는 다는 것은 cross over를 한다는 것인데 이는 특정 포인트를 기점으로 하여 위쪽은 w1 vector, 밑에는 w2 vector를 사용하는 것이다. 이러한 방식은 인접한 layer간의 상관관계를 줄여주면서 다양한 스타일이 서로 잘 분리 될 수 있도록 한다.

이해를 돕기 위해 나동빈님의 자료에서 발췌해왔다. 앞서 설명한 mixing regularization을 직관적으로 보여주는 그림이라고 할 수 있다. 이미지 A를 기반으로 이미지 B의 특징들을 섞는 것이다. 이 때 이러한 특징을 섞을 때 예를 들면 Coarse style을 적용한다고 하자. 그러면 오른쪽 matrix의 4열 까지는 Image B의 특징을 갖고(image B의 latent vector) 그리고 나머지 열은 Image A의 특징(image A의 latent vector)이 적용되는 것이다.
- Coarse style : 전반적인 style 변화(ex. 얼굴 포즈, 안경 유무)
- Middle style : 조금 더 세밀한 style(ex. 헤어스타일, 눈 떴냐 감았냐)
- Fine style : 훨씬 더 세밀한 정보(ex. 색상, 미세한 구조)
## Stochastic variation
사람은 그대로인데 그 날의 컨디션에 따라서 주근깨가 생기거나 바람이 불어서 머리 스타일이 바뀌는 것들에 대한 noise를 학습시키는 것이다. 즉, 확률적인 다양성이라고 말한다.

a는 noise를 모든 layer에 적용한 것, b는 noise를 적용 안한 것, c는 64x64~1024x1024 레이어(fine layer)에만 노이즈를 적용한 것, d는 4x4~32x32 layer(coarse layer)에만 노이즈를 적용한 것이다. 확실히 a가 잘 만들어짐을 확인할 수 있다.
Disentanglement studies

Disentanglement 하다는 것은 다양한 특징들이 잘 분류되어 있다는 것이다. 그러나 기존의 Gaussian 분포에서 추출하는 방식은 mapping이 되면서 nonlinear하게 변하게 된다. 즉, 특징들이 얽히고 섥혀서 변화가 된다는 것이다.
그러나 본 논문에서 제안하는 Mapping network 방식은 linear하게 각 특징들이 Disentangle 하게 됨을 알 수 있다. 이로 인해 각 특징들이 분리될 수 있다.
그림에 대한 설명을 조금 더 첨부하자면 a는 학습 데이터셋이다. 여기서 예를 들어 세로 축은 성별(높은 곳은 남성, 낮은 곳은 여성) 이라고 하고, 가로축은 머리 길이(왼쪽은 머리 긺, 오른쪽은 짧음) 이라고 하자. 여기서 데이터셋은 머리길이가 긴 남성이 없다. b 는 기존의 전통적인 방식인 gaussian distribution에서 sampling 한 latent vector z이다. 이 그림에서 보면 보라색과 노란색을 interpolation할 때 가운데 점인 파란색(a에서 오른쪽 아래 색)으로 되게 되는데 이는 entangle하게 될 수 밖에 없다. 즉, 각 특징을 잃어버리게 된다. 그러나 본 논문에서 제안하는 방식 latent vector z를 fully connected 네트워크를 거쳐 매핑한 w space를 보면 그림 c 처럼 각 색이 잘 분리되어 있는 것을 볼 수 있다. 즉, 각각의 특징을 잘 보존할 수 있다는 것이다.
## Path length
본 논문에선 성능 지표를 제안하였다.(다 해먹는다 진짜...)
이 성능지표는 두 벡터를 interpolation 할 때 얼마나 급격하게 이미지 특징이 변하는지를 측정하는 성능 지표이다.

z1과 z2에 대해서 interpolation을 수행할 때 t라는 상수로 지점을 명시할 수 있다. 대게 t는 0~1사이의 값으로 어디서부터 어디까지 얼마나 섞을 수 있을지를 명시한다. 그리고 이 때 앱실론은 아주 작은 값으로 10**(-4)이다.
따라서 z1과 z2를 interpolation을 하되 가장 근접한 두 지점에서 샘플링된 결과에서의 perceptual distance를 계산해서 두 이미지가 얼마나 많이 feature상에서 변화가 있었는지를 구하는 것이다. 따라서 l_z가 작을수록 급격한 변화가 없다는 것을 의미한다.
본 논문에선 latent vector z 에서만 계산하는 것이 아니라 w vector에 대해서도 계산을 한다.

latent vector w는 선형 보간법(linear interpolation)을 이용하고 위 방식과 동일하게 거리를 측정한다. 이 때, f(z1)은 w vector라고 생각하면 된다(because mapping network ! f : z ->w)
## Linear separability
latent space에서 속성이 얼마나 선형적으로 분류될 수 있는지를 평가한다.
CelebA-HQ라는 얼굴마다 성별 등의 40 개의 binary attributes가 명시되어있는 데이터셋이 있는데 이를 이용하여 40개의 분류 모델을 학습시킨다. 그리고 하나의 속성마다 20만개의 이미지를 생성하여 분류 모델에 넣는다.
분류모델에서 confidence가 낮은 절반은 제거 하고 10만개의 레이블이 명시된 latent vector를 생성한다. 즉, 높은 confidence를 가진 잘 만들어진 이미지만 남겨놓는 것이다. 그리고 이를 새로운 데이터셋으로 활용한다.(성별 등의 40개의 binary 속성에 대한 label 값이 포함된 데이터셋)
이 데이터 셋에서 각각의 attributes 마다 linear SVM 모델을 학습하고 이 모델에서 엔트로피를 계산한다.
conclusion은 생략한다.
'논문 정리' 카테고리의 다른 글
| Object Detection 정리(RCNN, FastRNN,FasterRCNN 중심으로) (0) | 2021.06.21 |
|---|---|
| TransGAN : Two Transformers Can Make One Strong GAN (0) | 2021.05.15 |
| Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks(CycleGAN) (0) | 2021.04.29 |
| Generative Adversarial Nets(GAN) (2) | 2021.04.04 |
| Auto Encoding Variational Bayes(VAE) -1 (5) | 2021.03.29 |




댓글