원 논문 : https://arxiv.org/pdf/2102.07074.pdf
퀄리티 높은 포스팅을 위해 논문을 1차적으로 읽고 여러 리뷰를 통해 완벽히 이해하고 논문 리뷰를 진행하였는데.. 이번 논문은 전혀 리뷰가 없어서(있어도 외국..있으나 마나이다..) 내가 쌩으로 읽고 쌩으로 이해한 것을 바탕으로 포스팅한다.
따라서..틀린 점이 있을 수도 있다...! 하지만 난 이걸 갖고 발표도 해야하므로..최대한 완벽하게 읽고 이해하고 포스팅을 진행한다.(주관적 기준..)
요즘 Comuputer Vision 분야에서 CNN이 살아남을 수 있을까라는게 큰 이슈이다. 최근에는 Transformer 기반의 Networks 구조가 각광을 받고 있고 심지어 더 최근에는 MLP가 더 발전을 해서 Computer Vision 분야에서 각광받고 있다. 이에 대한 논문은 아직 안읽어봤고 그냥 어쩌다가 최근 동향을 들은거라 자세히 설명을 못하지만 암튼 추세가 그렇다...
그러던 중 이 논문은 따끈따끈하게 2021년 2월에 나온 Transformer를 적용한 GAN 이다. 그래서 이름도 TransGAN이다. 사실 이러한 논문과 최근 동향을 많이 접하면서 NLP 분야에 나온 논문들도 많이 읽어야되겠다는 다짐을 하였다...논문 좀 그만 나왔으면..공부할 양이 너무 많다..
암튼 이제 한 번 정리해보겠다!
## Abstract
최근 Computer Vision 분야에서 Classification, Segmentation, Detection 등 Transformer의 잠재력이 발휘되면서 큰 영향을 끼치고 있다. 그런데 GAN 처럼 어려운 Task에서도 이러한 Transformer 적용이 가능할까?
이러한 궁금증에 기반해서 본 논문에선 완전히 Convolution을 사용하지 않은 방식을 제안한다. 그래서 오직 Transformer만 사용한다. 본 논문에선 이를 TransGAN 이라고 명칭한다.
이 TransGAN의 구성은 다음과 같다.
- memory-friendly Transformer를 베이스를 한 생성자. 이 생성자는 임베딩 차원이 감소하는 동안 점진적으로 feature resolution이 증가한다.
- patch-level의 Discriminator도 Transformer를 기반으로 한다.
TransGAN 3가지 이점이 있다. 첫번째는 Data 증강에 대해서 기존의 GAN 보다 더 좋은 성능을 내었다. 두번째론 생성자의 multi-task co-training 방식에 이점이 있다. 마지막으론 이미지의 주변영역을 smooth하게 하는 것에 더 강점이 있다.
그리고 TransGAN은 고화질의 이미지에 대해서도 강점이 있다. TransGAN은 SOTA에 있는 convolution 기반의 GAN이랑 도 비교했을 때 꽤 괜찮은 성능을 보였다.
특히, STL-10 데이터셋에 대해 IS(Inception score)는 10.10으로 , FID score는 25.32로 SOTA를 달성하였다.
## Introduction
introduction 에는 GAN이라는 모델이 나오면서 훈련의 불안정성을 해결하기 위한 연구가 진행되었음을 소개하고 ResNet backbone 기반으로 해결하려는 연구들을 소개하였다.
그러나 본 논문의 저자는 이 논문들이 깨지 못하는 하나의 상식(commonsense)이 있는데 그게 바로 무조건 convolution network의 backbone을 써야한다는 것이었다.
그리고 본 논문의 저자는 위와 같이 말한다.
"Can we build a strong GAN completely free of convolutions?"
convolution 은 최적화의 어려움이 있고, 세부 정보가 손실될 가능성도 있다.
그래서 본 논문의 저자는 Transformer architectures for computer vision tasks(https://arxiv.org/abs/2012.00364) 논문에 영감을 받아서 Transformer를 GAN에 적용하는 방법을 생각해냈다.
Transformer는 알다시피 NLP에서 자주 쓰이는 기법이다. 이러한 기법을 computer vision 분야에 적용하였을 때의 강점은 다음과 같다.
1. it has strong representation capability and is free of human-defined inductive bias.
= 인간이 정의하는 편향이 없고 표현력이 좋다.
2. Transformer는 간단하고 범용적으로 쓰일 가능성이 있다.
It can get rid of many ad-hoc building blocks commonly seen in CNN-based pipelines.
= Transformer는 CNN에서 많이 보이는 ad-hoc 빌딩 블록을 제거 할 수 있다.
## Our Contribution
본 논문의 main contribution은 오직 transformer 만을 사용한 최초의 completely free of convolution GAN모델인 것이다. 이는 기존의 encoder block 에서만 적용한 방식과는 완전히 다르다는 것을 강조한다.
기존 transformer 기반 CV모델들은 classification 혹은 detection에만 주로 사용되었기에 구조나 색상, 질감 등의 공간적인 일관성에도 효과가 좋은지 분명하지가 않다.
이미지를 출력하는 몇 안되는 transformer 기반 모델은 하나같이 convolution 기반의 encoder를 사용하였다. 이러한 이유는 visual transformer 모델의 training은 매우 무겁고 어렵기 때문이다. 거기에 본 논문에선 GAN이기 때문에 일반적으로 불안정하고 mode collapse가 쉽게 일어난다. 그래서 본 논문에선 이러한 문제를 해결하기 위한 노력을 기울인다. 그러면서 이를 해결하기 위한 혁신적인 방법을 공개한다.
본 논문에선 친절하게도 이를 잘 정리해서 나타냈다.

사실 뭐 이 정리가 논문 요약이다. 그래도 더 자세히 파보겠다.
## Relative Works
GAN 과 Visual Transformer에 대해서 설명한다. 또한, Transformer modules Image Generation에 대해 설명한다.
GAN 설명
2021.04.04 - [논문 정리] - Generative Adversarial Nets(GAN)
Generative Adversarial Nets(GAN)
원 논문 arxiv.org/pdf/1406.2661.pdf 참고 자료 www.youtube.com/watch?v=AVvlDmhHgC4 나동빈님의 유튜브를 참고하여 진행하였는데 정말 갓동빈님이시다...설명을 이렇게 쉽게 해주시는 분은 거의 처음본다..역시.
bigdata-analyst.tistory.com
Visual Transformer : https://arxiv.org/abs/2012.00364
Pre-Trained Image Processing Transformer
As the computing power of modern hardware is increasing strongly, pre-trained deep learning models (e.g., BERT, GPT-3) learned on large-scale datasets have shown their effectiveness over conventional methods. The big progress is mainly contributed to the r
arxiv.org
Transformer modules Image Generation : https://arxiv.org/abs/1911.12287
Your Local GAN: Designing Two Dimensional Local Attention Mechanisms for Generative Models
We introduce a new local sparse attention layer that preserves two-dimensional geometry and locality. We show that by just replacing the dense attention layer of SAGAN with our construction, we obtain very significant FID, Inception score and pure visual i
arxiv.org
## Technical Approach : A Journey Towards GAN with Pure Transformer
본 논문에선 G와 D의 minmax 싸움을 transformer가 이해할 수 있게 만드는 것으로 시작하였다.
그리고 이를 메모리 효율성을 위해 최적화 하는 노력을 하였다.
## Vanilla Architecture Design for TransGAN
Transformer encoder를 basic block으로 택했고 이를 최소한의 변화를 시도하였다. Transformer의 형태를 유지하기 위함이다.
그리고 encoder block은 두가지로 구성된다.
첫번째 block : multi-head self-attention module
두번째 block : feed-forward MLP with GELU
그리고 이 layer를 통과하기 전에 normalization layer를 적용시켰다. 그리고 두 부분 모두 residual connection을 적용시켰다.
## Memory-Friendly Generator
NLP에서 Transformer 모델은 각각의 단어를 모두 input으로 넣는다. 근데 이걸 비슷한 방식으로 이미지에 적용하면 pixel-by-pixel을 모두 input으로 넣어야되는데 이는 큰 무리가 있다. 예를 들어 32x32어도 1024의 길이가 나온다.
그리고 이는 self-attention에서도 큰 cost가 발생한다.
본 논문에선 이를 해결하기 위해 일반적인 CNN 기반의 GAN의 구조에서 영감을 받았는데 점차 upscaling 하는 방법을 차용한다. 그래서 본 논문의 전략은 점차적으로 input sequence를 늘리고 embedding 차원을 줄이는 것이다.
본 논문의 flow는 다음과 같다

위 그림은 pure한 TransGAN의 generator와 discriminator 구조를 보여준다. 여기서 H와 W는 8이고 H_t와 W_t는 32이다.
여기서 Generator 부분을 집중적으로 보자면 stage를 지나면서 target resolution(여기선 32x32)가 될 때까지 feature map resolution을 점진적으로 2배씩 증가시킨다. 특히 Generator의 input은 random noise로 들어가게 되고 이를 MLP를 통과시켜 HxWxC 크기를 가진 vector를 생성시킨다. 그리고 여기서 생성된 vector = feature map은 learnable한 positional encoding과 결합하게 된다.
transformer는 bert와 비슷하게 인코더에 임베딩 토큰을 inputs으로 넣고 각 토큰 간의 대응 관계를 재귀적으로 계산한다. 그리고 고해상도 이미지를 얻기 위해 pixelshuffle로 구성된 upsampling 모듈을 각각의 stage뒤에 넣는다.
우선 1D로 된 sequence를 2D로 변경 후 pixelshuffle를 적용해 2배 upsample을 하고 dimension 을 1/4로 줄인 후 1D sequence로 변화시킨다.(2H X 2W X C/4) 이 때,sequence는 변하지 않는다. 그리고 최종적으로 목표 해상도에 도달했을때 channel을 3으로 조정한다. 이런 방식으로 메모리 계산의 효율성을 갖고 온다.
즉, 다시 정리하자면
H x W x C -> 2H x 2W x C/4 -> 4H x 4W x C/16 -> 4H x 4W x 3
이러한 upsampling 과정을 거치는 것이다.
## Tokenized-Input For Discriminator
Generator와 달리 Discriminator는 진짜냐 가짜냐만 판단하면 된다. 그래서 입력 이미지를 patch level로 tokenizing 하는것을 허용하게 해준다. 위 그림에서 오른쪽 부분을 보면서 설명하면 input image를 8x8로 각각을 단어처럼 patch level로 만든다. 그리고 이 patch 된 것들을 linear flatten을 통해 임베딩 토큰 1d sequence로 바꾸고 차원은 동일하게 C로 맞춰준다. flatten 된 것들을 transformer encoder를 거치면서 [cls] 토큰을 추가해준다. 그리고 이를 갖고 real/fake를 분류한다.
## Evaluation of Transformer-Based GAN
본 논문에선 4가지 방법에 대해 실험하였다.
1. AutoGAN G + AutoGAN D
2. Transformer G + AutoGAN D
3. AutoGAN G + Trnasformer D
4. Transformer G + Transformer D(본 논문의 method)
Transformer G의 각 stage에 5개 5개 2개의 encoder block이 있고, Transformer D에는 한 스테이지의 7개의 encoder block으로 구성된다.
CIFAR-10으로 훈련을 시킨 후 각각 하이퍼파라미터 조절 시키고 성능 지표는 Inception Score, FID이다.

결과는 다음과 같이 Transformer G 가 매우 강력한 성능을 가짐을 확인할 수 있었다. 그러나 Transformer D는 매우 성능이 좋지 않았고 그나마 Transformer G와 함께했을 때 약간의 성능향상이 이뤄졌다.
결과적으로는 CNN 기반 Discriminator에는 미치지 못하는 성능을 보여줬다.
## Data Augmentation is Crucial for TransGAN
Transformer 기반의 분류기는 사람이 디자인한 편향의 제거 때문에 데이터 부족(data-hungry) 현상이 나타나게 된다. 많은 데이터가 pretraining 되기 전까진 Transformer 기반이 매우 성능이 떨어졌다. 이러한 문제를 해결하기 위해 데이터 증강을 연구하였다.
GAN에서는 기본적으로 augmentation이 잘 언급되지 않았지만 최근 few-shot 모델들이 각광 받고 있다. 따라서 본 논문의 저자는 이러한 모델들을 활용하여 증강을 하였고 다시 실험을 진행하였다.

위 표에서 DA는 Data augument이다. 3가지 모델(WGAN, AutoGAN, StyleGAN2) 중 StyleGANv2를 적용했을 때 눈에 띄는 성능향상을 이뤘다. 그리고 TransGAN은 데이터를 증강시킴으로써 눈에 띄는 큰 성능 향상이 이뤄졌다. 이로 인해 data-hungry 상태임이 증명이 되었다.
## Co-Training with Self-Supervised Auxiliary Task
NLP 에선 Transformer가 multiple pretraining tasks를 이뤘을 때 좋은 성능을 보였다. 또한 GAN에서도 self-supervised 보조 테스크를 추가하였을 때 좋은 성능을 냈던 기존의 연구가 존재한다. 따라서 이러한 기존의 연구 방식을 차용하여 적용한다.
GAN loss function 외에 추가로 super resolution 보조 테스크를 구성한다. 사용 가능한 실제 영상을 고해상도 영상으로 처리하고 Downsampling으로 저해상도 영상을 얻을 수 있기 때문에 이미지 생성이 쉬워진다. Generator loss 함수에 보조 task lambda * L_SR 을 더한다. L_SR은 MSE 이고 lambda 는 50으로 설정한다.

이 방식을 MT-CT(Multi-Task Co-Training) 이라고 한다.
## Locality-Aware Initialization for Self-Attention
CNN 기반 모델은 이미지를 natural image smoothness 하는 기능이 있다. 하지만 Transformer 모델은 이런 부분이 부족하다. 그러나 Transformer 모델은 convolution 구조를 이미지로 부터 배우는 경향이 있는 것을 발견하였다. 이 convolution의 inductive bais와 transformer의 flexibility 를 같이 encoding 할 수 있는지 실험하였다. 기존 연구에선 convolution layer를 섞어서 low-level 이미지 구조를 encoding 하였다. 그러나 본 논문에선 warm-starting 만으로 이를 구현하여 비슷한 효과를 내게 하였다.
본 논문에선 self-attention을 이용한 Locality-Aware Initialization를 소개한다. 이 특별한 전략은 다음 그림과 같다.
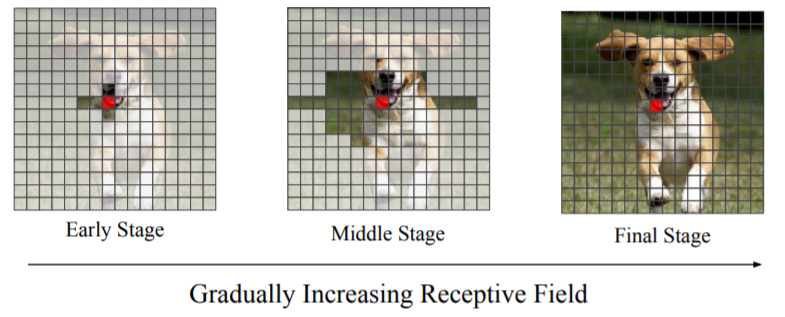
이 전략은 마스크되지 않은 픽셀과만 상호작용이 가능하도록 설정하였다. 이러한 방식을 stage 마다 mask를 확대하여 최종 스테이지에선 receptive field가 global되게 만들었다. 하지만 이 방식은 초기에는 도움이 되지만 훈련을 하면 할수록 성능에 도움이 안된다. 따라서 이러한 초기화 방식을 regularizer로써 초기 train에만 적용을 한다. 이 방식을 통해 TransGAN은 결과 향상을 이룰 수 있었다.

## Scaling up to Large Model
고해상도의 이미지에서도 잘 동작할 수 있기 위한 방법을 제안한다.

각각 S,M,L,XL은 각각 384,512,768,1024의 차원을 나타낸다. 그리고 하이퍼파라미터 튜닝 없이 고해상도일 때도 좋은 결과를 얻었다. XL 같은 경우에는 encoder block의 개수를 늘려서 좋은 성능을 유지할 수 있게 하였다.
## Result
실험 결과에 대해선 짤막하게 설명하겠다.
1. dataset : CIFAR-10

styleganv2에 못미치지만 IS는 3등, FID로는 2등의 결과를 얻었다.
2. dataset : STL-10(SOTA!)

IS, FID 부분에서 모두 SOTA를 달성하였다
최종 결과 사진

흠...솔직히 CelebA 사진은 좀 이상한거 같다..




댓글