원 논문 : arxiv.org/abs/1703.10593
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be a
arxiv.org
참고 링크 : www.youtube.com/watch?v=Fkqf3dS9Cqw
참고한 링크는 CycleGAN 논문 작업에 참여하셨던 박태성님이 직접 설명해주신 영상이다.
좋은 설명 다시 한 번 감사드립니다.
본 글은 좀 더 이해를 돕기 위해 순서를 발표의 순서를 따른다.
CycleGAN은 각기 다른 도메인 이미지가 있을 때 첫번째 도메인 이미지를 다른 도메인으로 바꿀 수 있는 모델이다.
논문의 시작은 CycleGAN의 결과물로 시작한다.

앞서 설명한 것과 같이 모네의 그림을 사진처럼 바꿔주고, 얼룩말을 말로 여름 사진을 겨울 풍경으로 바꿔준다. 심지어 이 반대도 가능하다. 그리고 하나의 사진을 화가의 화풍으로 바꿔줄 수도 있다.
이러한 작업은 pix2pix -> GAN -> CycleGAN순으로 loss function을 위주로 살펴보며 설명이 가능하다.
## Abstract
Image to Image Translation은 pair 형태의 이미지를 train set으로 이용하여 input iamge와 output image를 매핑한다. 그러나 pair한 이미지를 얻기에는 어려운 일이다. 본 논문은 pair된 이미지 없이 도메인으로부터 얻은 이미지를 target doomain Y로 바꾸는 방법을 제안한다.
Aversarial loss를 이용하여 G(x)로 부터의 이미지 데이터의 분포와 Y로부터의 이미지 데이터의 분포가 구분 불가능하도록 불가능하도록 G를 학습시키고(GAN), 이를 F: Y-> X와 같은 역방향 매핑을 진행하여 F(G(x))가 X가 유사해지도록 하는 cycle consistency loss를 도입한다.
즉, 그림을 사진으로 바꾸고 바꾼 사진을 다시 그림으로 바꾸었을 때 원본과의 차이가 적어지도록 만드는 loss function이다.
이러한 과정을 알기 위해선 pix2pix와 GAN 개념을 알아야하는데, GAN은 기존에 리뷰했던
2021.04.04 - [논문 정리] - Generative Adversarial Nets(GAN)
Generative Adversarial Nets(GAN)
원 논문 arxiv.org/pdf/1406.2661.pdf 참고 자료 www.youtube.com/watch?v=AVvlDmhHgC4 나동빈님의 유튜브를 참고하여 진행하였는데 정말 갓동빈님이시다...설명을 이렇게 쉽게 해주시는 분은 거의 처음본다..역시.
bigdata-analyst.tistory.com
이를 참고하면 더욱 자세히 알 수 있고, pix2pix는 조만간 리뷰하도록 하겠다. 그래도 CycleGAN에서 적용한 각 논문의 핵심 내용을 정리해보도록 하겠다.
## pix2pix
pix2pix는 타이틀에서도 추측할 수 있듯이 픽셀을 다른 픽셀로 바꿀 수 있다는 것이다.

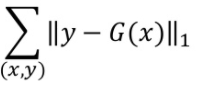
pix2pix는 supervised learning으로 라벨링된 input 이미지를 학습시키고 생성한 이미지 G(x)와 Ground Truth Y와의 절대값 오차를 최소화하는 loss function을 가진다.(L1 Loss)
하지만 이러한 loss function을 가질 때 문제점은 다음 사진과 같다.

꽤 잘 복원한 것 같지만 누가봐도 어떤게 가짜 이미지고 가짜 사진인지 알 수 있다.

흑백 사진을 컬러 이미지로 복원하였을 때의 문제점도 다음과 같이 나타난다.
이러한 문제가 생기는 이유는 실제 사진이 어떠한 색깔인지를 모르기 때문에 loss를 최소화 하는 방향으로 중간값의 색깔로 이미지의 색깔을 결정하게 된다. 따라서 Ground Truth와 다른 색을 갖게 된다.
이러한 문제점이 나타나서 GAN의 개념을 적용하게 된다.
## GAN
앞서 리뷰한 GAN을 정리하자면 input x를 통해서 생성자 G를 통해 G(x)라는 이미지를 생성하고 이 이미지를 판별자 D가 진짜인지 가짜인지 판별하는 것이다.

따라서 생성자 G는 D를 속이기위해 최대한 진짜같은 이미지를 만들어야한다는 것이다.
GAN의 loss function은 다음과 같다.
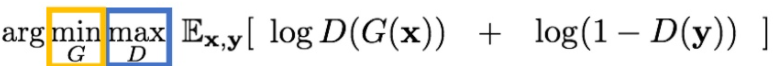
이를 G의 관점에서 보자면 D는 loss function인데 이는 고정된 값이 아니라 변화하면서 학습하는 것이다. 즉, G와 D는 함께 경쟁을 통해 성장해나가면서 더욱 진짜같은 이미지를 만들어내는 것이다.
## pix2pix(+GAN 적용)
따라서 pix2pix는 GAN의 Loss function을 이용하여 기존의 loss function의 단점을 극복하였다.

따라서 기존의 L1 loss에 GAN의 loss function을 추가하여 pix2pix의 loss function을 생성하였다.
이렇게 pix2pix와 GAN의 개념을 알아보면서 CycleGAN을 이해하기 위한 기본 개념을 알아보았다.
## CycleGAN
CycleGAN의 목표는 앞서 말한 것과 같이 하나의 도메인을 다른 도메인에 적용하는 것이다(pair image 없이)
이를 수식으로 표현하면 다음과 같다.

두개의 매핑함수 G: X -> Y와 F: Y -> X를 포함시킨다. 또한 여기에 두개의 adversarial D_x와 D_y를 도입한다.
이러한 loss function을 만든 이유는 다음과 같다. 만약 GAN의 loss function만 적용한다면 아무 사진이 들어와도 그럴듯한 사진을 하나 생성할 수 있다. 그런데 이 때 우리가 원하는 것은 그럴듯한 이미지가 아니라 원 사진과 비슷한 pair image를 원하는 것이다. 그림으로 보면 다음과 같다.

왼쪽이 input 이미지고 오른쪽이 GAN이 생성한 이미지라고 해보자. GAN은 실제로 있을 법한 사진을 생성하였다. 그러나 input image와는 전혀 비슷하지 않다. 또한 첫번째 input image를 넣어도 첫번째 output G(X)가 나오고 두번째 input image를 넣어도 첫번째 output G(x)가 나오는 문제점이 발생한다. 즉, input image를 무시한다는 것이라고 할 수 있다.
따라서 CycleGAN의 key objective는 G가 그림을 사진으로 바꾸는데 다시 그 사진을 그림으로 바꿀만하게 바꿔라 라는 것이다. 즉, 원래 그림이 복구 가능할 정도로만 바꾸는 것이다.
이를 위해 다음과 같은 식을 도출하게 된다.


즉, 생성자 G와 반대방향의 사진을 그림으로 바꿔주는 네트워크 F를 동시에 훈련시킨다. loss function의 식에 대입하여 풀어서 말하자면 cyclegan의 목표 F(G(x)) = x는 그림을 사진으로 바꿨을 때의 사진을 다시 그림으로 바꿨을 때 원래 x와 똑같아야된다는 것이다.
이를 더 확장하면 그림을 사진으로 바꿔주는 것 뿐만 아니라 사진을 그림으로 바꿔주는 것까지 학습을 시킬 수 있다. 확장해서 Loss function을 도출하면 다음과 같다.
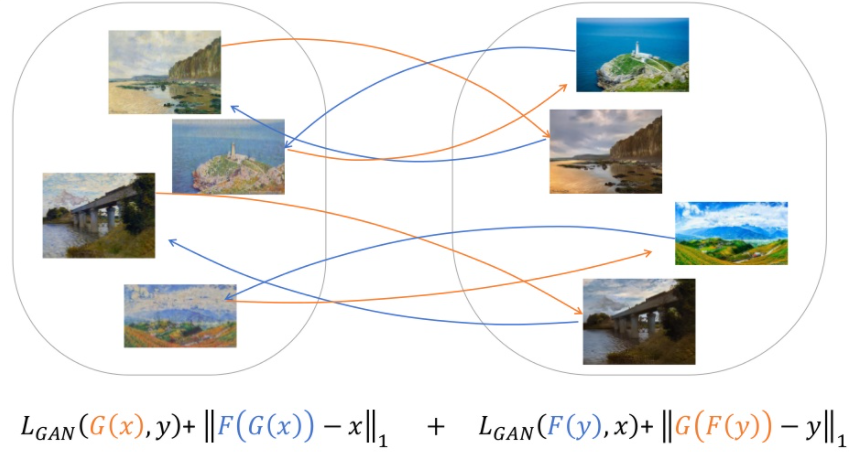
여기서 빨간색은 G이고 파란색은 F이다. 사실 이를 추가한 이유는 결과의 향상을 위한 것이다. 첫번째 식만 적용하였을 때에는 결과가 좋지 않고 모든 경우의 loss를 합쳐야지 더 좋은 성능이 나오고 더욱 다양성 있는 결과가 생성되기 때문이다.
이렇게 정리된 것을 Cycle Loss라고 칭한다.
## Experiments

위 이미지는 loss function을 몇개씩 뺐을 때의 결과 값이다. Cycle은 위 loss function에서 ||F(G(x))-x|| 부분만 사용한 것이다. 그리고 forward는 loss function에서 우항에 있는 것이고, backward는 좌항에 있는 것이다.
따라서 CycleGAN에서 제시한 Loss function을 모두 사용하였을 때의 결과가 가장 만족스러운 결과를 이뤄냈다.

GTA 데이터셋을 사용했을 때, input X에서 GAN을 이용하여 Fake Photo를 생성하면 차를 만들어낸다. 그러나 신기하게도 Reconstruction 즉, CycleGAN이 다 동작하였을 때는 원래 이미지와 비슷하게 나온다.
## Training Details
### Generator G
논문의 저자가 밝힌 내용에 따르면 고해상도의 이미지를 적용하기 위해서 CycleGAN이 발명되었다고 한다. 그리고 이를 위해 처음엔 U-Net을 적용하였다.

U-Net을 적용할 때 skip connection을 이용하여 처음 이미지의 feature를 그대로 적용 가능하게 만들었다. 따라서 Detail을 훨씬 더 많이 갖고 있다는 장점이 있다. 그러나 단점은 skip connection을 너무 많이 사용하여 BottleNeck이 많아지고 Depth가 적어져서 만족스러운 결과를 얻지 못했다고 한다. 그래서 이를 극복하기 위해 ResNet을 사용하게 되었다.

ResNet을 사용하게 되면서 image의 quality는 더욱 향상이 되었다. 그러나 ResNet은 BottleNeck이 없어서 메모리를 많이 사용하게 되고 그렇기 때문에 생성할 수 있는 learnable parameter수가 적어지는 단점이 있다. 그래서 많은 형태의 변화를 만들어낼 수 없다는 단점이 있다.
### Objective
기존의 GAN loss function은 Gradient Vanishing 문제가 발생한다. 그러나 본 논문에서는 LSGAN의 Loss function을 사용함으로써 Gradient Vanishing 문제를 해결하였다.

CrossEntropy 형식이 아닌 제곱을 해준다. LSGAN에서는 진짜 이미지가 1에 가까운 score를 나타나야하고 가짜 이미지는 0에 가까운 스코어를 나타내야한다.
## L1LOSS
앞서 설명한 pix2pix에서의 L1 Loss를 이용함으로써 GAN자체의 훈련 어려움을 좀 더 완화하고 극복하고자 한다. 이로써 L1 Loss가 Guide Line 역할을 해준다고 한다. 직접적인 L1 Loss가 아닌 가짜 L1 Loss를 생성하여 Guide line을 잡는 것이다. 즉, 바꾸려는 사진의 이미지를 넣었을 때 GAN에서 생성한 이미지와의 L1 Loss를 생성하게 되는 것이다. 이를 Identity Loss라고 한다.
이러한 L1 Loss를 추가하여서 좀 더 안정적인 CycleGAN의 결과를 도출할 수 있게 된다.

### Full Obejctive

labmda 는 첫번째 항과 두번째 항의 상대적 중요도에 따라 결정이된다. 그리고 풀고자 하는 목표는 다음과 같다.

## Results

결과 사진을 마무리로 CycleGAN 논문 리뷰를 마치겠다.
'논문 정리' 카테고리의 다른 글
| TransGAN : Two Transformers Can Make One Strong GAN (0) | 2021.05.15 |
|---|---|
| A Style Based Generator Architecture for Generative Adversarial Networks(StyleGAN) (0) | 2021.05.09 |
| Generative Adversarial Nets(GAN) (2) | 2021.04.04 |
| Auto Encoding Variational Bayes(VAE) -1 (5) | 2021.03.29 |
| Deep Residual Learning for Image Recognition(ResNet) (4) | 2021.03.13 |




댓글