한눈에 보는 머신러닝
머신러닝이란?
- 머신러닝은 데이터로부터 학습하도록 컴퓨터를 프로그래밍하는 과학
- 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구분야
예시 : 스팸 필터
- Training Set : 시스템이 학습하는데 사용하는 샘플
- Tranining Data : 이 메일은 스팸이다라는 경험
- Accuracy : 성능 측정(정확도)
왜 머신러닝을 사용하는가?
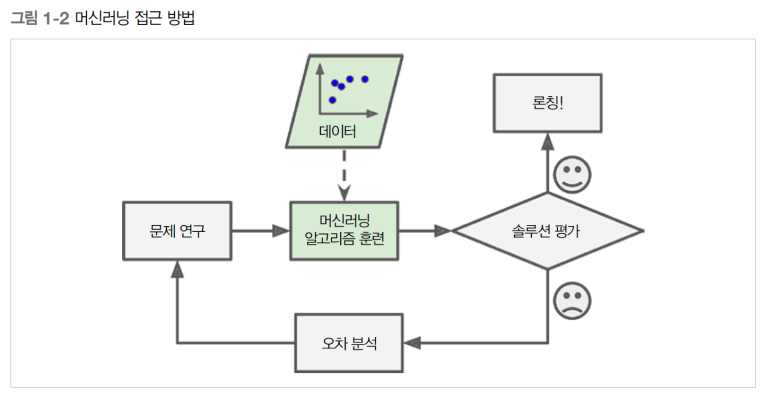
오차 분석 등을 통해 새로운 오차들을 학습시켜서 더 좋은 예측 성능을 낼 수 있음
데이터 마이닝(Data Mining) : 머신러닝 기술을 적용해서 대용량의 데이터를 분석하면 겉으로 보이지 않던 패턴을 발견할 수 있음

- 머신러닝을 사용했을 때 더욱 효율적인 분야
```
- 기존 솔루션으로는 많은 수동 조정과 규칙이 필요한 문제
- 전통적인 방식으로는 전혀 해결 방법이 없는 복잡한 문제
- 유동적인 환경
- 복잡한 문제와 대량의 데이터에서 인사이트 얻기
머신러닝 시스템의 종류
1. 학습하는 동안의 감독 형태나 정보량에 따라 분류
- 지도학습
지도학습(Supervised Learning) 이란 알고리즘에 주입하는 훈련 데이터에 레이블(label) 이라는 답이 포함되어 학습
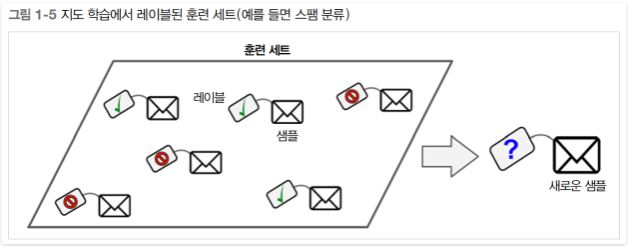
분류(Classification) : 전형적인 지도학습의 예( ex. 스팸이다 아니다 분류 예측)
회귀(Regression) : 예측 변수를 특성을 이용하여 타겟 수치를 예측 ( ex. 주행거리, 연식, 브랜드로 중고차의 가격 예측)
지도학습 알고리즘 예시:
- KNN(K-Nearest Neighbors)
- Linear Regression
- Logistic Regression
- Support Vector Machine(SVM)
- Decision Tree & RandomForest
- Neural Networks
비지도학습
비지도학습이란 훈련 데이터에 레이블이 없음(지도학습과 반대)
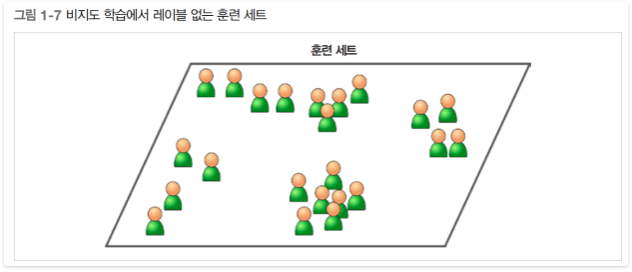
비지도학습 알고리즘 예시:
- Clustering
- KMeans Clustering
- Hierarchical Cluster Anaylsis(HCA)
- Expectation Maximization
- Visualization & Dimensionality Reduction
- PCA
- kernelPCA
- LLE(Locally-Linear Embedding)
- t-SNE
- Association rule learning
- Apriori
- Eclat
- 군집 알고리즘(Clustering) : 각 사용자의 특성을 고려하여 군집화 시킴
- 시각화 : 시각화를 통해서 데이터의 조직을 파악(EDA)
- 차원 축소 : 많은 정보를 잃지 않으면서 데이터를 간소화 하는 작업(ex. 상관관계가 있는 여러 특성을 하나로 합침 - Feature Extraction)
- 이상치 탐지 : 정상 샘플로 훈련하여 새로운 샘플이 정상인지 아닌지를 판단
- 연관 규칙 학습 : 장바구니 분석 등 대량의 데이터에서 특성 간의 유의미한 관계를 찾는 것
- Clustering
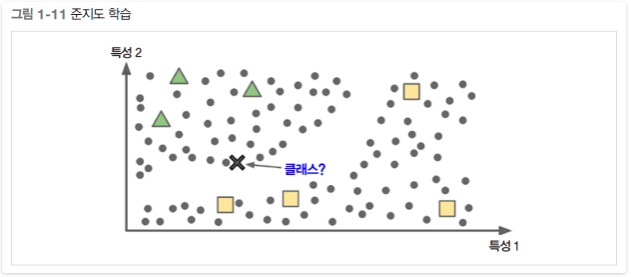
준지도학습
준지도학습이란 레이블이 일부만 있는 데이터. 보통은 레이블이 없는 데이터가 많고 레이블이 있는 데이터는 적음(ex. 구글 포토 호스팅 서비스)
비지도학습 알고리즘 예시: (비지도 + 지도)
- DBN(Deep Belif Network) -> RBM(Restricted Boltzmann Machine)이란 비지도 학습에 기초, RBM으로 훈련 후 지도학습으로 세밀 조정
- DBN(Deep Belif Network) -> RBM(Restricted Boltzmann Machine)이란 비지도 학습에 기초, RBM으로 훈련 후 지도학습으로 세밀 조정
강화학습
강화학습 이란 에이전트라는 학습하는 시스템에서 환경을 관찰해서 행동을 하고 그 결과로 보상(Reward) 또는 벌점(Penalty) 을 받아 최적의 정책(Policy) 을 수립

2. 데이터의 스트림으로 부터 점진적으로 학습할 수 있는지 여부에 따라 분류
- 배치학습
배치학습이란 가용한 데이터를 모두 사용하여 훈련 시킴. 단지 학습한 것만 적용.(=오프라인 학습)
- 장점 : 과정이 매우 간단.
- 단점 : 많은 컴퓨팅 자원 필요 및 빠른 적응 불가
- 온라인 학습
온라인 학습은 데이터를 순차적으로 미니 배치라 부르는 묶음 단위로 주입하여 시스템 훈련. 학습 단계가 빠르고 비용이 적게 들어가 즉시 학습 가능(=점진적 학습)
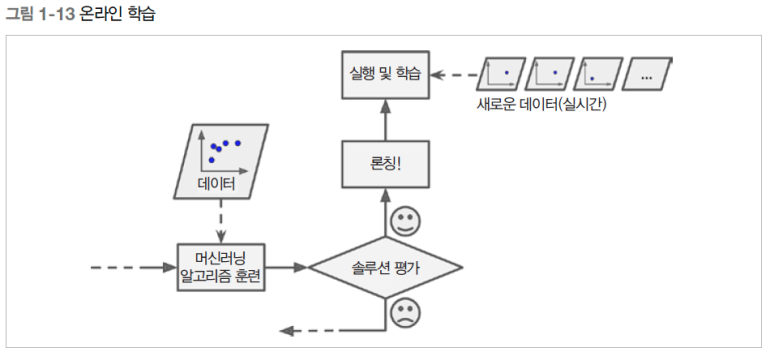
학습률에 따라서 변화나는 데이터에 얼마나 빠르게 적응할 것인지 판단
- If, 학습률 ↑ -> 데이터에 빠른 적응, but 기존의 데이터 학습 능력 떨어짐
- If, 학습률 ↓ -> 데이터에 느리게 적응, but 이상치에 둔감
3. 어떻게 일반화 되느냐에 따라 분류
- 사례기반 학습
사례기반 학습은 단순히 기억하는 것. 유사도를 측정하여 그 기준으로..

- 모델기반 학습
모델기반 학습은 샘플들의 모델을 만들어 예측에 사용

- 예시 : 돈이 사람을 행복하게 만드는가?(GDP와 삶의 만족도를 기준으로)

데이터가 흩어져 있지만 선형적으로 올라가는 것을 볼 수 있다. 이로 인해 선형 모델을 생성 ( 삶의 만족도 = theta0 + theta1 x GDP)

위와 같이 가능한 선형식을 몇가지 정의 후 모델의 최적의 성능을 가질 수 있게 만들어야 함. 훈련(Tranining) 을 통해서
- 성능 지표
- 효용 함수(Utility Function) → 모델이 얼마나 좋은지👍
- 비용 함수(Cost Function) → 모델이 얼마나 나쁜지👎
머신러닝의 주요 도전 과제
1. 데이터의 양이 적을 때

2. 대표성이 없는 데이터
일반화되지 않은 데이터를 사용했을 때, 샘플링 잡음(Sampling Noise) 또는 샘플링 편향(Sampling Bias) 발생 가능성
3. 낮은 품질의 데이터
에러나 이상치가 많은 데이터에선 알고리즘이 패턴을 파악하기 어려움. 이를 해결하기 위해 전처리(Preprocessing) 과정이 필요
4. 관련 없는 특성
Garbage In,Garbage Out 따라서 훈련에 사용할 좋은 특성들을 찾는 것이 중요
- Feature selection : 훈련에서 가장 유용한 특성 선택 (ex. 전진 선택법, 후진 선택법)
- Feature Extraction : 특성을 결합하여 더욱 유용한 특성을 만듦 (ex. PCA, 파생변수 생성)
5. Training set Overfitting
모델이 매우 훈련 데이터에 대해서만 훈련이 되어 있는 것. Test set에서 훈련 데이터에서 약간만 벗어나도 바로 오류날 가능성
과대적합 해결 방법
- 파라미터 수가 적은 모델을 선택하거나, 훈련 데이터에 있는 featuer 수를 줄이거나 모델에 제약(Regulation) 을 가한다.
- 훈련데이터를 더 많이 모은다.
- 오류 데이터 수정 및 이상치 제거
- 하이퍼파라미터 조절
6. Training set Underfitting
모델이 너무 단순하여 내재된 구조를 학습하지 못할 때 발생
과소적합 해결방법
- 더 많은 파라미터를 가진 모델을 선택
- 학습 알고리즘에 더 좋은 특성 제공(Feature Selection or Feature Extraction)
- 모델의 제약 감소(Regulation 완화)
Validation & Test
보통 Train:Test = 8:2
성능 평가시 성능이 잘 안나올 때 해결 방법 -> Validation Set 사용
Traning set을 사용해 여러가지 하이퍼파라미터 조절을 한 후 Validation Set을 이용하여 최상의 성능을 내는 모델 및 하이퍼파라미터 선택
Validation set에 데이터의 비율을 사용하지 않기 위해 Cross Vaildation 기법 사용(ex. K-Fold)
'핸즈온 머신러닝' 카테고리의 다른 글
| Chapter 4 - 모델 훈련(1) (0) | 2021.01.31 |
|---|---|
| Chpater3 - 분류 (0) | 2021.01.10 |
| Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(3) (0) | 2021.01.05 |
| Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(2) (0) | 2021.01.05 |
| Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(1) (1) | 2021.01.04 |




댓글