2021/01/04 - [핸즈온 머신러닝] - Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(1)
Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(1)
Big Picture : 비즈니스의 목적이 무엇인지 정확히 판단해야한다! 성능 지표 선택: - RMSE(평균 제곱 오차): np.sqrt(mean_square_error(true_y,pred_y) - MAE(평균 절대 오차) : mean_absolute_error(treu_y,..
bigdata-analyst.tistory.com
2021/01/05 - [핸즈온 머신러닝] - Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(2)
Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(2)
2021/01/04 - [핸즈온 머신러닝] - Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(1) Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(1) Big Picture : 비즈니스의 목적이 무엇인지 정확히 판단해야한다! 성능
bigdata-analyst.tistory.com
## 특성 스케일링
왜 스케일링을 하는가? ->
데이터의 값이 너무 크거나 혹은 작은 경우에 모델 알고리즘 학습과정에서 0으로 수렴하거나 무한으로 발산해버릴 수 있기 때문
- 스케일링의 종류
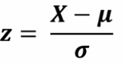
- StandardScaler : from sklearn.preprocessing import StandardScaler
Z-정규화 -> 각 변수들의 평균을 0, 분산을 1로 변경

- MinMaxScaler : from sklearn.preprocessing import MinMaxScaler
모든 변수들이 0~1 사이의 값을 갖게 만듦 -> 이상치에 민감하게 반응
- MaxAbxScaler : from sklearn.preprocessing import MaxAbsScaler
모든 변수들이 절대값 1 사이 즉, -1~1 사이의 값을 갖게 됨
큰 이상치에 민감. 상대적으로 standardscaler와 minmaxscaler에 비해 덜 민감

-RobustScaler : from sklearn.preprocessing import RobustScaler
평균대신 중앙값을 사용. 중위수를 뺀 다음 사분위간 범위(IQR)로 나눔
이상치 영향 최소화
## Pipeline
파이프라인이란?
변환을 순서대로 처리할 수 있도록 하는 모듈
즉, imputer(결측치 처리) -> onehotencoding(카테고리 처리) -> StandardScaling(정규화)를 한꺼번에 진행할 수 있게 도와줌
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([('imputer',SimpleImputer(np.nan,strategy='median')),
('attribs_adder',CombinedAttributesAdder()),
('std_scaler',StandardScaler())])
housing_num_tr = num_pipeline.fit_transform(housing_num)이름/추정기의 쌍을 만들어 입력을 받음
pipeline을 만들고 fit_transform으로 데이터 프레임에 적용 가능
다른 pipeline 결합 방법 :
•FeatureUnion(transformer_list=[‘pipe1_name’:pipe1, ‘pipe2_name’ : pipe2])
## 훈련세트에서 훈련하고 평가하기
1. 선형 회귀 (linear regression)
Linear Regression 모듈 : from sklearn.linear_model import LinearRegression
사용 예시
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
lin_reg.predict(some_data_prepared)
'''
array([211574.39524336, 321345.10514334, 210947.51983552, 61921.01197602,
192362.32961567])
'''
이러한 간단한 모델로 전체 훈련셋에 대한 회귀 모델의 RMSE 측정
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels,housing_predictions)
lin_rmse = np.sqrt(lin_mse)
lin_rmse
```
69050.98178244587
```정확도는 매우 낮다. 중간 주택의 가격(종속변수)의 범위는 12000~265000 인 반면에 오차가 약 69000이면 안좋은 모델. 즉, 과소적합(underfitting)
2. DecisionTree
Decision Tree 모듈 : from sklearn.tree import DecisionTreeRegressor
from sklearn.tree import DecisionTreeRegressor
dt = DecisionTreeRegressor()
dt.fit(housing_prepared,housing_labels
housing_predictions = dt.predict(housing_prepared)
dt_mse = mean_squared_error(housing_labels,housing_predictions)
dt_rmse = np.sqrt(dt_mse)
dt_rmse
```
0.0
```전혀 오차가 없다. 이는 전형적인 과대적합(overfitting)
과대적합 과소적합을 방지하기 위해 교차 검증이 필요하다.
## 교차검증(K-fold)
교차 검증 코드
from sklearn.model_selection import cross_val_score
scores = cross_val_score(dt,housing_prepared,housing_labels,scoring='neg_mean_squared_error',cv=10)
tree_mse_scores = np.sqrt(-scores)10번 교차 검증한다. DecisionTree 모델로. 이 때 scoring 에서 neg_mean_squared_error 를 적용하였으므로 scores에 음수를 붙여서 root 값 계산
scoring은 효용 함수(높을 수록 좋은)을 기대. 따라서 MSE(비용함수-낮을 수록 좋은)에 음수값을 계산하는 scoring 사용
tree_mse_scores.mean()
'''
69570.62104449584
'''
성능이 좋지 않다. 다음으로 linear regression을 check한다.
lin_scores = cross_val_score(lin_reg,housing_prepared,housing_labels,scoring='neg_mean_squared_error',cv=10)
rmse = np.sqrt(-lin_scores)
rmse.mean()
'''
69223.1859414427
'''얘도 좋지 않다.
3. RandomForest
RandomForest 모듈 : from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(housing_prepared,housing_labels)
pred = rf.predict(housing_prepared)
rf_score = cross_val_score(rf,housing_prepared,housing_labels,scoring='neg_mean_squared_error',cv=10)
rf_rmse = np.sqrt(-rf_score)
rf_rmse.mean()
'''
49536.20528241699
'''다른 모델에 비해 성능이 확실히 뛰어남을 알 수 있다.
# 모델 세부 튜닝
## Grid Search
GridSearch란 하이퍼파라미터의 조합을 교차 검증하여 평가. 지정한 조합 중 가장 좋은 조합을 반환
from sklearn.model_selection import GridSearchCV
param_grid = [{'n_estimators':[3,10,30],'max_features':[2,4,6,8],'bootstrap':[False]}]
rf = RandomForestRegressor()
grid_search = GridSearchCV(rf,param_grid,cv=5,scoring='neg_mean_squared_error',return_train_score=True)
grid_search.fit(housing_prepared,housing_labels)
grid_search.best_params_
'''
{'bootstrap': False, 'max_features': 4, 'n_estimators': 30}
'''
반환된 하이퍼 파라미터의 조합이 가장 높은 성능을 내었다는 것을 알 수 있다.
각각의 평가 점수도 계산 가능
cvres = grid_search.cv_results_
for mean_scores,params in zip(cvres['mean_test_score'],cvres['params']):
print(np.sqrt(-mean_scores),params)
'''
62870.6111296466 {'bootstrap': False, 'max_features': 2, 'n_estimators': 3}
54038.99580762019 {'bootstrap': False, 'max_features': 2, 'n_estimators': 10}
51927.629173833455 {'bootstrap': False, 'max_features': 2, 'n_estimators': 30}
59273.17388845567 {'bootstrap': False, 'max_features': 4, 'n_estimators': 3}
51837.50943337966 {'bootstrap': False, 'max_features': 4, 'n_estimators': 10}
50061.269670345035 {'bootstrap': False, 'max_features': 4, 'n_estimators': 30}
58582.394661914965 {'bootstrap': False, 'max_features': 6, 'n_estimators': 3}
51595.289570749395 {'bootstrap': False, 'max_features': 6, 'n_estimators': 10}
50355.92487424536 {'bootstrap': False, 'max_features': 6, 'n_estimators': 30}
57624.96130644364 {'bootstrap': False, 'max_features': 8, 'n_estimators': 3}
52723.07427524798 {'bootstrap': False, 'max_features': 8, 'n_estimators': 10}
50351.220947864145 {'bootstrap': False, 'max_features': 8, 'n_estimators': 30}
'''
## 랜덤 탐색
RandomizedSearchCV 모듈 사용 : 각 반복마다 하이퍼파라미터에 임의의 수를 대입하여 지어한 횟수만큼 평가
- 만약 1000번 반복하면 1000가지의 경우의 수 하이퍼파라미터 조합을 가능하게 함
- 단, 반복 횟수가 많을수록 시간은 오래 걸린다.
## 최상의 모델과 오차 분석
feature_importances = grid_search.best_estimator_.feature_importances_
feature_importances
'''
array([1.27062437e-01, 1.13182708e-01, 4.74119707e-02, 4.28282484e-02,
3.25232942e-02, 4.98281984e-02, 3.24728285e-02, 3.78334802e-01,
2.09341025e-02, 1.37205204e-01, 6.35052910e-05, 7.34152679e-03,
1.08111744e-02])
'''모델이 정확한 예측을 만들기 위한 각 특성의 상대적 중요도를 반환
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
# cat_encoder = cat_pipeline.named_steps["cat_encoder"]
attributes = num_attribs + extra_attribs
sorted(zip(feature_importances, attributes), reverse=True)
'''
[(0.3783348020443614, 'median_income'),
(0.13720520382456597, 'pop_per_hhold'),
(0.12706243723531702, 'longitude'),
(0.11318270774168193, 'latitude'),
(0.04982819839008343, 'population'),
(0.047411970746068274, 'housing_median_age'),
(0.042828248431746305, 'total_rooms'),
(0.03252329415357459, 'total_bedrooms'),
(0.03247282846400168, 'households'),
(0.020934102494924684, 'rooms_per_hhold'),
(6.350529099763644e-05, 'bedrooms_per_room')]
'''median income이 정답을 맞추는데 가장 중요한 역할을 하였다.
## Test
final_model = grid_search.best_estimator_
X_test = start_test_set.drop("median_house_value", axis=1)
y_test = start_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse
# 47834.546604105315
튜닝이 끝난 모델의 조합으로 Test셋으로 테스트한다. 예측 결과 반환 rmse : 47834
'핸즈온 머신러닝' 카테고리의 다른 글
| Chapter 4 - 모델 훈련(1) (0) | 2021.01.31 |
|---|---|
| Chpater3 - 분류 (0) | 2021.01.10 |
| Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(2) (0) | 2021.01.05 |
| Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(1) (1) | 2021.01.04 |
| Chapter1 - 한눈에 보는 머신러닝 (1) | 2020.12.29 |




댓글