Big Picture : 비즈니스의 목적이 무엇인지 정확히 판단해야한다!
성능 지표 선택:
- RMSE(평균 제곱 오차): np.sqrt(mean_square_error(true_y,pred_y)
- MAE(평균 절대 오차) : mean_absolute_error(treu_y,pred_y) <- 이상치가 많을 때 사용
## 데이터 로딩 : (파일 다운로드)

ocean_proximity 만 문자형 변수
따라서
housing['ocean_proximity'].value_counts()를 통해서 값이 몇개 있는질 확인

data.describe() 를 통해 수치형 데이터의 통계적 수치를 볼 수 있음
데이터의 전체적인 특성을 시각화로 볼 때
data.hist(bins=50,figsize=(20,15))
plt.show()

housing median age와 median house value 는 최댓값과 최솟값을 한정함.
median income은 스케일링을 거친 값이다.
train셋과 test 셋을 분리하기 위해서 sklearn의 모듈을 사용.
나누는 이유 : 과대적합 방지. 실제 머신러닝이 잘 작동하는지를 test셋을 통해 확인
from sklearn.model_selection import train_test_split
train_set,test_set = train_test_split(housing,test_size=.2,random_state=42)80:20으로 랜덤 샘플링을 한다. random_state는 랜덤값이 고정되게 seed값을 주는 것
계층 샘플링
랜덤으로 샘플링 했을 때 데이터의 편향 현상이 생길 수 있다. 이를 방지하기 위해 특정 feature의 비율을 정하고 그 비율에 맞게 샘플링을 함.
data['income_cat'] = np.ceil(data['median_income']/1.5)
data['income_cat'].where(data['income_cat']<5,5.0,inplace=True)
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1,test_size=.2,random_state=42)
for train_idx,test_idx in split.split(data,data['income_cat']):
start_train_set = data.loc[train_idx]
start_test_set = data.loc[test_idx]income_cat이라는 변수의 비율 분포에 맞게 계층 샘플링 진행
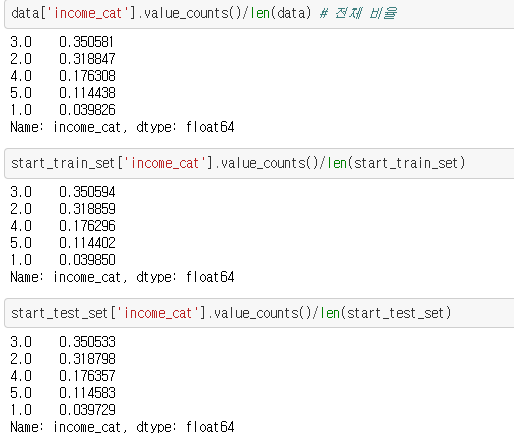
위 결과처럼 비율이 유지되는 것을 볼 수 있다.
## Visualization
경위도 데이터가 있으니 이에 맞게 지리적인 산점도를 그림

alpha 라는 파라미터로 투명도를 0.2로 조절하여 밀집된 지역을 쉽게 알아볼 수 있게 조절
어느 지역에 인구가 많이 모여있는지를 보기 위해 원의 색으로 집의 중앙값을 나타내고 원의 크기로 인구 수를 나타내는 scatter plot을 그림
housing.plot(kind='scatter',x='longitude',y='latitude',alpha=.4,
s=housing['population']/100,label='population',figsize=(10,7),
c='median_house_value',cmap = plt.get_cmap('jet'),colorbar=True,sharex=False)
plt.legend()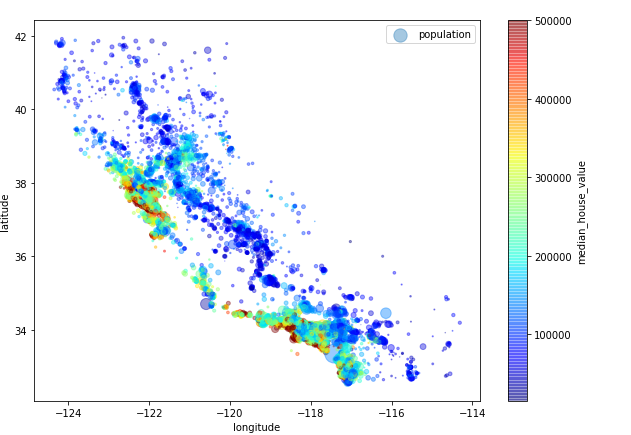
바다 쪽에 몰려있음을 알 수 있다.
## 상관관계 조사
corr_matrix = housing.corr()
corr_matrix['median_house_value'].sort_values(ascending=False)
위와 같은 상관계수의 시각화
from pandas.plotting import scatter_matrix
attributes = ['median_house_value','median_income','total_rooms','housing_median_age']
scatter_matrix(housing[attributes],figsize=(12,8))
각 변수의 자신의 것은 히스토그램으로 나타내고 나머지는 scatter plot 을 그려줌
median income,median_house_value 양의 상관관계 가 있음을 알 수 있다.
변수 튜닝을 통한 상관관계 분석
housing['rooms_per_household'] = housing['total_rooms']/housing['households']
housing['bedrooms_per_room'] = housing['total_bedrooms']/housing['total_rooms']
housing['population_per_household'] = housing['population']/housing['households']
corr_matrix = housing.corr()
corr_matrix['median_house_value'].sort_values(ascending=False)
bedrooms_per_room 변수는 집 가격과 음의 상관관계를 갖고 있다는 것을 알 수 있다. 새로운 파생변수 생성
'핸즈온 머신러닝' 카테고리의 다른 글
| Chapter 4 - 모델 훈련(1) (0) | 2021.01.31 |
|---|---|
| Chpater3 - 분류 (0) | 2021.01.10 |
| Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(3) (0) | 2021.01.05 |
| Chapter2 - 머신러닝 프로젝트 처음부터 끝까지(2) (0) | 2021.01.05 |
| Chapter1 - 한눈에 보는 머신러닝 (1) | 2020.12.29 |



댓글