이 글은 https://www.youtube.com/watch?v=8mI9zRdx2Es&list=PLSAJwo7mw8jn8iaXwT4MqLbZnS-LJwnBd&index=22
기반으로 작성하였다.
CNN 정리는 2021.08.15 - [딥러닝 기초] - Basic of Convolution Neural Network
Basic of Convolution Neural Network
본 글은 https://www.youtube.com/watch?v=PIft4URoQcw&list=PLSAJwo7mw8jn8iaXwT4MqLbZnS-LJwnBd&index=19 이 동영상을 바탕으로 작성되었습니다. ## Problems of MLP MLP는 파라미터가 너무 많다는 것이다. 왜냐..
bigdata-analyst.tistory.com
이를 참고하면 된다.
## ImageNet Competition
ImageNet은 227 x 227 x 3 사이즈의 이미지로 구성되어있고 총 1000개의 class를 분류하는 대회이다. 아직까지도 개최되고 있는 대회이고(SOTA 홈페이지 참고) 2015년도 까지의 성능은 다음과 같다.

위 랭킹을 보면 알렉스넷이 처음으로 CNN을 기반으로 해서 1등을 차지하였고, 그 이후 비약적인 발전으로 ResNet에선 3.57의 에러율만을 기록하였다.
## AlexNet
AlexNet은 최초로 CNN을 사용하여 ImageNet 대회에서 우승한 모델이다.
AlexNet은 다음과 같은 구조로 이뤄져있다.

이는 매우 간단한 CNN 구조로 Convolution, MaxPooling, Nomralization layer(현재는 성능 떨어진다고 안씀)을 반복한 구조이다. 그리고 AlexNet에서 처음으로 ReLU를 사용하였다. 그리고 Data Preprocessing을 하여 Data Augmentation을 사용하였다. 그리고 Learning_rate scheduler를 사용하였다. 마지막으로 앙상블을 사용하였다.
## VGGNet
VGGNet은 기존의 모델보다 Layer 수를 더 많이 사용하여 더 깊어진 신경망을 구성하였다. 총 19개의 Layer를 통해 SOTA를 달성하였다.
VGG의 특징은 작은 filter를 사용하고 Deep한 Network를 만들었다는 것이다.
VGG의 구조는 다음과 같다.

3x3 filter를 씌워서 컨볼루션 연산을 진행한다.
VGGNet에서 3x3의 작은 필터를 씌운 이유는 다음과 같다.

7x7 크기의 이미지에서 3x3 filter를 씌워서 컨볼루션 연산을 한 번 하면 5x5의 receptive field의 크기가 되고 그리고 한 번 더 컨볼루션 연산을 진행하면 3x3 의 크기를 갖게 된다. 따라서 한 번에 크게하나 작게 여러번 하나 receptive field의 크기 차이는 없다는 것이다.
이런 방식으로 계산하였을 때 장점은 파라미터 수가 줄어들게 된다는 것이다.
3x3 filter를 2개 씌우면 3x3 + 3x3 = 18 개가 되고 5x5 를 한번쓰면 25개의 파라미터를 갖게 된다.
그리고 또한, 컨볼루션 연산을 여러번 진행할 때 비선형성이 여러번 들어가게 되서 더 복잡한 특징들을 학습할 수 있다는 장점이다.
따라서 네트워크는 더 Deep해지고, Overfitting도 줄어들고, 파라미터 수를 줄일 수 있다.
VGG는 3x3 filter를 사용해서 stride = 1, padding = 1로 설정하고 그리고 2x2 MaxPooling을 stride=2만으로 좋은 성능을 내었다.
VGG의 파라미터 변화는 다음과 같다.

위와 같은 방법을 통해 파라미터 수를 줄였지만 마지막 Fully Connected Layer에서 paramter 수가 매우 늘어나는 것을 볼 수 있다.
## GoogleNet
GoogleNet은 VGG19 보다 더 Deep한 Network를 사용하였고, 그리고 이를 좀 더 효율적으로 나타내었다. parameter 수는 오직 500만개 정도밖에 안되게 사용하였다. 그리고 GoogleNet의 핵심인 Inception module을 사용하였다.
Inception Module은 다음 그림과 같다.

inception module은 어떤 layer에 하나의 사이즈의 필터만 적용하는 것이 아니라 여러개의 filter를 적용해보자라는 아이디어로 나온 것이다. 위 그림처럼 1x1 filter, 3x3 filter, 5x5 filter, 3x3 max pooling도 한 번에 적용하는 것이다. 그리고 이 값을 concatenation(쌓는 것) 해서 다음 layer로 넘어간다.
예시를 통해 한 번 봐보자
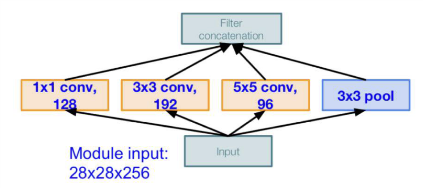
28x28x256 사이즈 input 값에 1x1 filter 128개, 3x3 filter 192개, 5x5 filter 96개, 3x3 maxpooling을 적용한다.
- 1x1 filter 128개 적용했을 때 : 28x28x128 -> parameter 연산 : 28x28x128x1x1x256
- 3x3 filter 192개 적용했을 때 : 28x28x192 -> parameter 연산 : 28x28x192x3x3x256
- 5x5 filter 96개 적용했을 때 : 28x28x96 -> parameter 연산 : 28x28x96x5x5x256
- Maxpooling 적용했을 때 : 28x28x256
이를 concat하면 28x28x(128+192+96+256)이 된다. 이 때 파라미터연산을 모두 더하면 854M 개로 매우 많게 정도 나온다.
GoogleNet은 이를 해결하기 위해 1x1 filter Convolution을 사용한다.
예를 들어 56x56x64 tensor에 1x1 filter를 32개를 씌우면 56x56x32가 된다. 이를 통해 Depth를 줄여주는 역할을 한다.
이러한 방법을 BootleNeck Layer라고 한다.
따라서 BottleNeck Layer를 적용한 결과는 다음과 같다.

이런 방식으로 적용하게 되면 parameter 수는 다음과 같다,

BottleNeck을 활용하지 않았을 때 보다 매우 적은 paramter를 얻을 수 있다.
이러한 Inception을 적용한 GoogleNet의 Architecture는 다음과 같다.

GoogleNet Architecture를 보면 중간중간에 빠져 있는 것을 볼 수 있다. 저 부분은 Gradient vanishing 문제를 해결하기 위해서 Layer 중간중간에 classification을 수행하고 loss가 계산되면 이를 통해서 output layer와 먼 쪽도 loss가 잘 전달 될 수 있도록 한다. 이를 통해 Gradient vanishing 문제를 해결할 수 있다.
## ResNet
ResNet은 Residual Connection을 사용하여 깊은 Network를 구성할 수 있다.
ResNet은 152층을 쌓아서 ImageNet 에러율을 3%대로 낮추었다.
ResNet의 핵심 개념인 Residual Block과 Architecture는 다음과 같다,.

ResNet에 대한 자세한 설명은 2021.03.13 - [논문 정리] - Deep Residual Learning for Image Recognition(ResNet)
Deep Residual Learning for Image Recognition(ResNet)
ResNet 원 논문 arxiv.org/pdf/1512.03385.pdf 참고 자료 leechamin.tistory.com/184 " style="clear: both; font-size: 2.2em; margin: 0px 0px 1em; color: rgb(34, 34, 34); font-family: "Roboto Condensed",..
bigdata-analyst.tistory.com
에 있다.
'딥러닝 기초' 카테고리의 다른 글
| Basic of Convolution Neural Network (0) | 2021.08.15 |
|---|---|
| Advanced Optimizer than SGD (0) | 2021.08.14 |
| Overfitting, Regularization (0) | 2021.08.01 |
| 코드에서 파라미터 최적화 (0) | 2021.07.28 |
| MultiLayer Perceptron (0) | 2021.07.26 |



댓글