## Probability Theory
패턴 인식 분야의 핵심 개념은 불확실성이다. 측정 노이즈뿐만 아니라 데이터 세트의 유한 크기를 통해 발생한다. 확률 이론은 불확실성의 정량화와 조작을 위한 일관된 프레임워크를 제공하며 패턴 인식을 위한 중심 기반 중 하나를 형성한다.
즉, 이를 다시 말하면 data는 내부에 불확실성을 가지고 있는데 이를 잘 모델링할 수 있는 것이 확률 모델이다. 이러한 확률 모델을 사용함으로써 데이터 내부에 있는 불확실성을 잘 파악할 수 있고 이를 통해 더 나은 학습 결과를 나타낼 수 있다.
여기서 말하는 data 내부의 불확실성은 다음의 예시로 들 수 있다.

위 파란색선을 데이터를 대표할 수 있는 함수라고 하고, 빨간색 점은 실제 데이터라고 하자.
여기서 파란색선과 빨간색 점이 일치하는 것도 있지만 빨간색 선과 파란색 선이 일치하는 경우가 많다. 이를 data의 불확실성이라고 한다.
그럼 이를 수식으로 표현하자면 실제 데이터를 y 라고 하고 \( \delta \)를 확률 모델이라고 하자.
$$ y(x) = \delta^{*}(x) + \epsilon $$
여기서 \( \epsilon \)은 noise로 이 noise가 불확실성이 된다.
## Decision Theory
결정이론은 data 내부에 불확실성이 있는데 이러한 불확실한 상황에서 어떻게 최적의 결정을 낼 수 있을까라는 이론이다.
## Information Theory
information theory 의 key는 entropy이다. entropy는 불확실성을 측정하는 측도로 생각하면 된다.
## Two Fundamental Rules
1. sum rule
$$ p(X) = \Sigma_{Y}p(X,Y) $$
여기서 이 식이 의미하는 것은 marginal distribution의 합을 의미한다. 즉 이 식을 다시 풀면 X와 Y의 joint probability가 있을 때 이를 Y에 대해 모두 합하면 다른 한 변수에 대한 확률이 나오는 것을 의미한다.

위 표로 예를 들면 X=0 일 확률 p(X=0) 일 확률을 구해보자. 그러면 p(X=0,Y=0) + p(X=0,Y=1) + p(X=0,Y=2) 를 하면 p(X=0)이 된다. sum rule은 이를 말하는 것이다.
2. product rule
$$ p(X,Y) = p(Y | X) p(X) $$
이 product rule은 conditional probability 를 계산할 때 용이한 rule이다.
간단하게 conditional probability를 말하자면 p(Y|X)는 X라는 상황이 이러났을 때 (조건), Y라는 상황이 일어날 확률을 말하고 이는 식으로 \( p(Y|X) = \frac{p(X,Y)}{p(X)} \)가 된다.
## Bayes Rule
Bayes rule은 sum rule과 product rule을 기반으로 한 식으로 다음과 같다.
$$ p(Y|X) = \frac{p(X,Y)}{p(X)} $$
$$ p(X) = \Sigma_{Y} p(X|Y) p(Y) $$
이 하나하나의 의미에 대해서 살펴보도록 하자.
Bayes' rule을 X와 Y로 정리하는 것이 아닌 H (Hypothesis) 와 e (event )로 재정의 해보자.
$$ P (H|e) = \frac{P(e | H ) P(H) }{P(e)} $$

정리하면 다음과 같다.
- \( P(e|H) \) = Likelihood : 가정이 사실일 때, 사건에 대한 확률
- \( P(H) \) = Prior : 가정에 대한 사전 확률
- \( P(e) = \Sigma_{i} P(e|H_{i}) P(H_{i}) \) = Marginal : 모든 사건에서 사건에 대한 확률
- \( P (H | e) \) = Posterior : 사건이 관측되었을 떄, 가정에 대한 확률
이를 예를 들어서 각각의 용어에 대해 설명해보겠다.
우선 사건 H = "나는 감기에 걸렸어" 이고, event e = "난 콧물을 흘려" 이다.
여기서 Posterior , \( P (H | e) \) 는 내가 콧물을 흘릴 때, 감기가 걸릴 확률을 말한다.
그리고 likelihood \( P(e|H) \) 는 내가 감기에 걸렸을 때, 콧물을 흘릴 확률을 말한다.
Prior \(P(H)\)는 감기가 걸릴 확률, marginal \( P(e) \)는 콧물을 흘릴 확률을 말한다.
그럼 이러한 확률은 ML에선 어떻게 변환이 될까?
ML에서는 H 는 model paramter \( w \)로 바뀌고, e는 data \( D \)로 바뀐다. 따라서 ML에 대한 notation으로 바꾼 식은
$$ P (w|D) = \frac{P(D | w ) P(w) }{P(D)} $$
과 같다.
이를 위와 동일하게 ML 관점에서 해석하자면
Prior P(w) : 모델의 파라미터의 분포
Likelihood P(D|w) : 주어진 w가 데이터를 얼마나 잘 data를 설명하는 가를 의미
Marginal P(D) : data의 분포
Posterior P(w|D) : data가 주어졌을 때, w에 대한 확률
따라서 이러한 베이지안 rule을 ML에 잘 적용하여 훈련을 하면 model의 paramter w를 잘 추정할 수 있게 된다.
근데 이 때 의문이 들 수 있다. 그러면 Likelihood를 중심으로 학습하여 w가 얼마나 잘 data를 설명하는 가가 중요한 것이냐 아니면 data가 주어졌을 때 추정된 w의 분포를 잘 맞추는 것이 중요하냐라는 두가지 관점이 생길 수 있다.
그래서 전자는 Frequentist 라고 부르고 후자를 Baysian으로 부른다.
이 둘의 차이를 잠깐 적어보면
Frequentist는 확률을 사건의 빈도로 보는 것이고, Baysian 은 확률을 사건 발생에 대한 믿음 또는 척도로 바라보는 것이다. 따라서 Frequentist는 확률을 하나의 상수로 보고, Baysian은 확률을 하나의 상수가 아닌 언제든 변할 수 있는 확률 변수의 관점으로 본다. 이는 확률을 해석하는 관점에 대한 차이라고 말할 수 있다. Frequentist는 여러 번의 실험을 통하여 알게된 사건의 확률을 검정하므로 사건이 독립적이고 반복적이고 정규분포를 따를 때 사용하는 것이 좋다. 하지만 이러한 확률은 사전에 관찰한 지식이 없을 경우 결과에 대한 신뢰가 떨어진다. Baysian은 고정된 데이터 관점에서 파라미터에 대한 신념의 변화를 분석하기 때문에 확률 모델이 명확히 설정되어 있다면 조건부 가설로 검증하여 가설의 타당성이 높아질 수 있다는 점이다. 하지만 이러한 Baysian은 확률변수로 보는 관점으로 인해 지속적인 update가 필요하고 사전 지식 모델링에 따라서 사후 확률 결과가 크게 달라질 수 있다.
위 설명은 확률변수를 보는 관점에 대한 차이를 설명한다.
그럼 이를 수식적으로 표현하자면 다음과 같다.
Frequentist 관점에서의 Probability는
$$ P(x) = \lim_{n_{t} \rightarrow \infty} \frac{n_{x}}{n_{t}} $$
가 된다. 여기서 \( n_{x} \)는 x event 가 발생한 횟수 이고, \( n_{t} \)는 총 시도 횟수이다.
이는 예를 들어 주사위를 무한하게 던졌을 때 1이 나올 확률을 구할 때 1/6을 도출되는 것과 같다.
따라서 Fequentist는 실험을 매우 많이 하는 것을 중요하게 생각한다.
다음으로 Bayesian의 관점에서는 확률이 아닌 Posterior를 보면
$$ P( \theta | D) = \frac{P ( D | \theta ) P ( \theta ) }{P (D) }$$
이다. Posterior의 확률은 data를 관측하고 나서 parameter에 대해서 얼마나 알고 있는지를 설명하는 것이다. 그리고 여기서 likelihood는 관찰된 데이터의 확률값(Frequentist)을 말하고 Prior는 data를 관측하기 전 paramter 값을 말한다.
Frequentist의 목적 : Regions of high quality of fit == 데이터에 분포에 최대한 맞추도록 하자
Baysian의 목적 : piror와 data가 주어졌을 때 pdf의 parmater를 구해보자
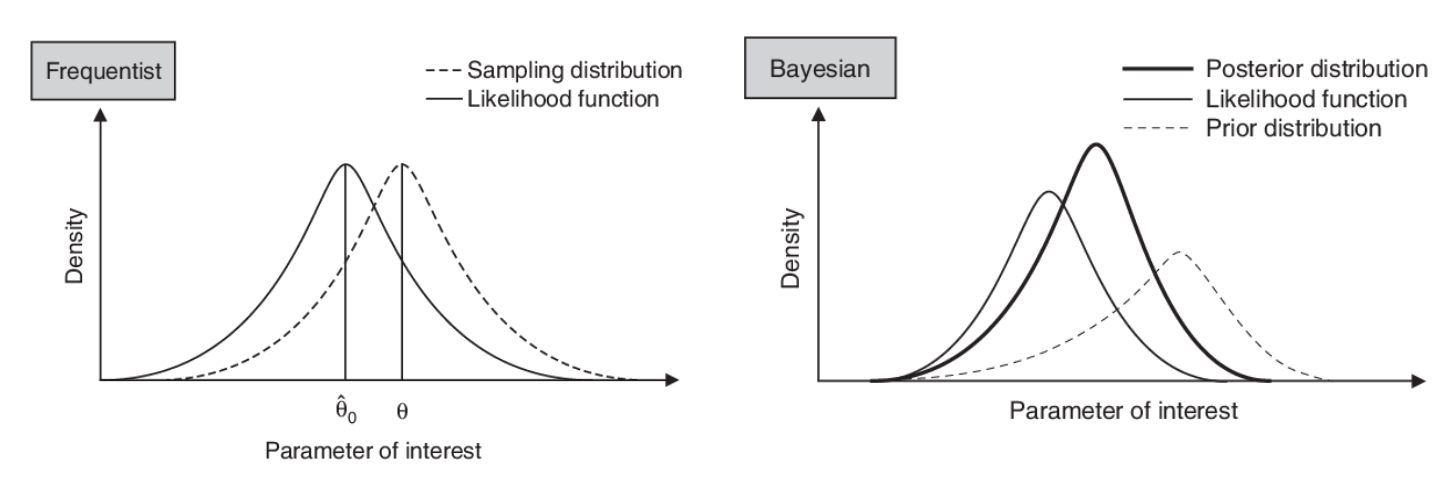
Frequentist는 점선으로 된 원래의 data에 likelihood distribution이 점선 방향으로 학습을 하는 것이다.
반면에 Bayesian은 Prior distribution이 주어져서 Posterior distribution을 Prior와 likelihood를 이용해서 구하는 것이다.
따라서 Frequentist를 수식적인 관점에서 보면 model paramter \( \theta \)를 Maximize likelihood estimator를 하는 것은
$$ \theta_{ML} = argmax_{\theta} P(x| \theta ) $$
처럼 나타내진다. 이는 즉, 파라미터의 조건 하에 data x를 최대화 하는 것과 같다.
다음으로 Bayesian은 Prior 로 부터 posterior를 update하는 것에 초점이 되어있고 이는
$$ \theta_{MAP} = argmax_{\theta} P( \theta | x ) $$
로 나타내진다.
그러면 이를 Estimator 관점에서 간단하게 설명하면
Fequentist Estimator는 Likelihood를 최대화 하여 구하는 것이고, Bayesian Esitmator는 Posterior를 최대화 하여 구하는 것이다.
이러한 학습 방법을 이용하여 Polynomial Curve Fitting 문제를 해결해보자.
## Polynomial Curve Fitting
첫번째로 익히 잘 알고 있는 Error를 최소화 하는 방법이다.
일단 Polynomial Curve를 다음의 그림과 다음의 식처럼 정의한다고 하자.
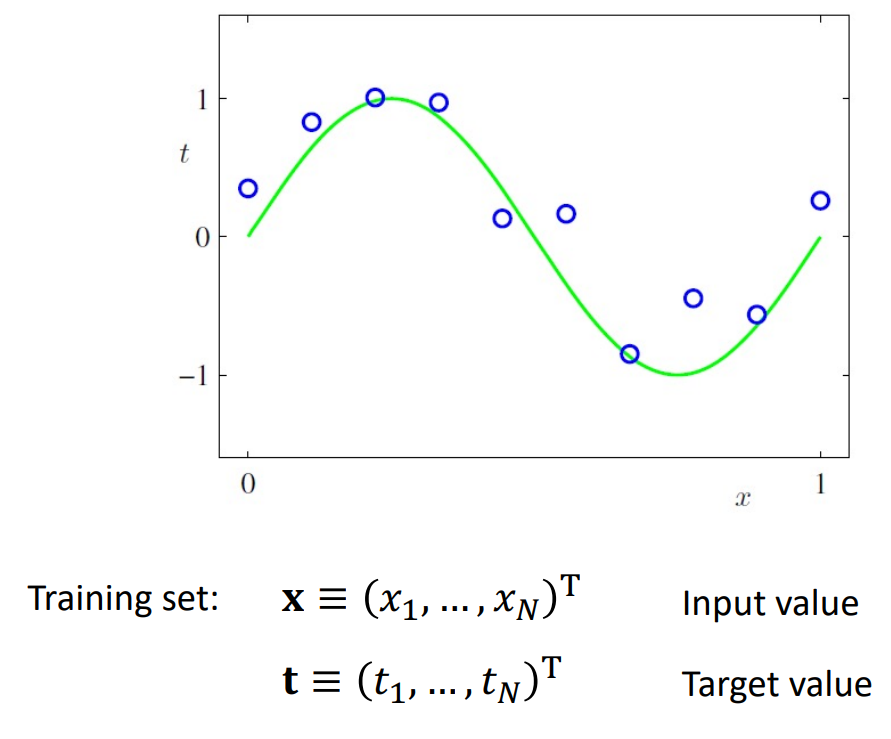
$$ y(x, w ) = w_0 + w_{1}x + w_{2}x^{2} + \cdots + w_{M}x^{M} = \Sigma_{j=0}^{M} w_{j}x^{j} $$
Error는 Ridge Loss를 사용해보자.
$$ E(w) = \frac{1}{2} \Sigma_{n=1}^{N} ( y(x_n , w) - t_n ) + \frac{ \lambda }{2} || w ||^{2} $$
그렇게 되면 다음과 같은 그림처럼 에러가 최소화 되는 방향으로 학습이 된다.
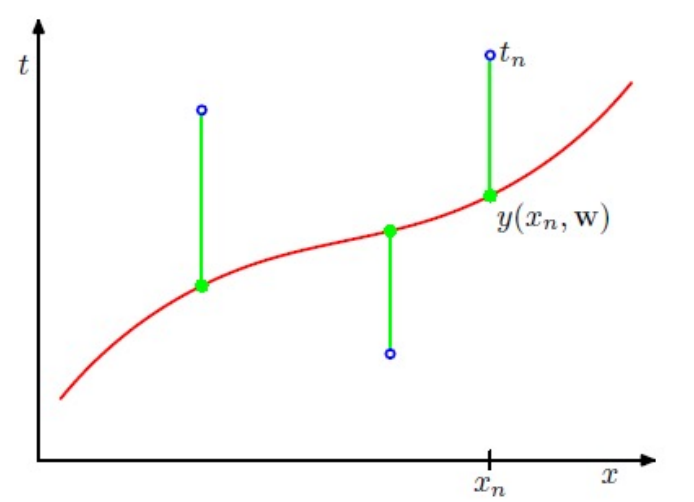
두번째로는 Fequentist estimator 관점으로 Likelihood를 최대화 하는 방향으로 학습하는 방법이다.
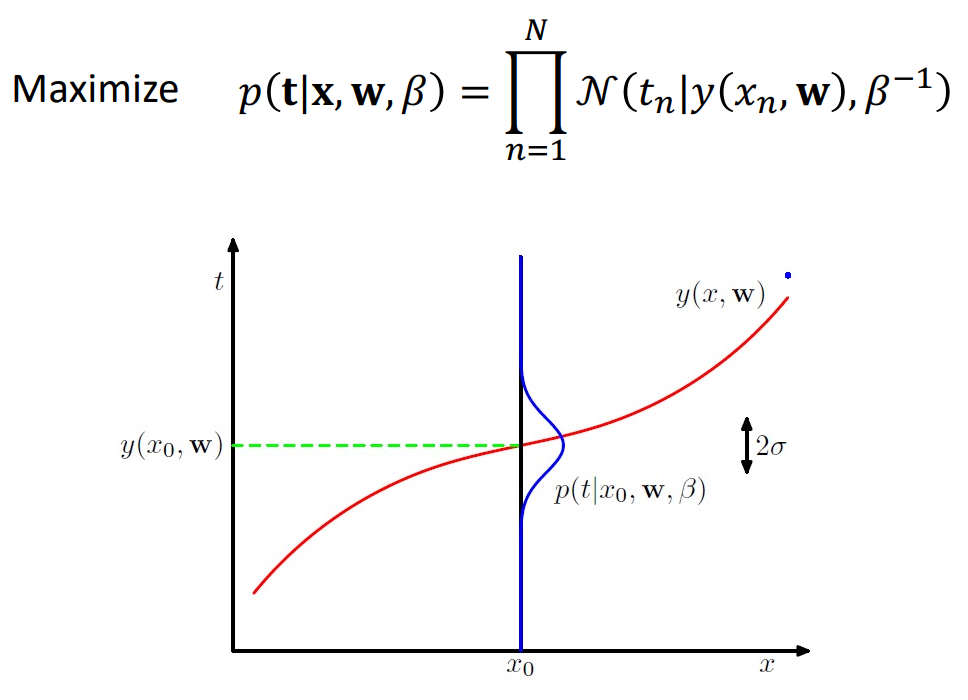
여기 식을 보면 모델 파라미터 w가 조건으로 들어가있다. 그리고 이에 따라서 결국 t 에 대한 확률 즉, data에 대한 확률을 구하는 것이 목적이다. 따라서 이 식은 likelihood 로 보면 된다. ( 모델 paramter가 조건, 데이터 t를 예측)
여기서 데이터에 대한 조건을 좀 더 보자면 input x 가 주어졌을 때, target t는 평균이 현재 모델의 결과값인 y(x,w)를 Gaussian distribution을 따른다는 전제가 들어가있다. 그리고 여기서 \( \beta \)는 이러한 gaussian distribution의 variance가 된다.
그래서 이를 바탕으로 위 그림을 해석하자면 \( x_0 \)라는 input이 들어올 때 target은 현재 모델의 값을 갖고 있는 gaussian distribution을 따르고 고정된 variance를 가지는 확률분포가 된다는 것이다. 따라서 gaussian distribution의 평균값을 잘 조절함으로써 이 모델이 input data를 잘 설명할 수 있도록 학습을 하는 것이다.
다음으로는 Bayes' Estimator 관점으로 Posterior를 최대화 하는 방향으로 학습을 하는 방법이다.
이를 알아보기 전에 Posterioir의 식을 다시 쓰면
$$ P (w|D) = \frac{P(D | w ) P(w) }{P(D)} $$
이와 같은데 likelihood는 두번째 방법처럼 구하면 되는데 P(w) 즉, Prioir distribution을 모른다.
그래서 Bayes' Rule을 이용해선 Gaussian distribution을 Prior distribution으로 사용한다. 이러한 Gaussian distrubution은 평균이 0이고, variance는 constant한 알고있는 값이라고 가정한다.
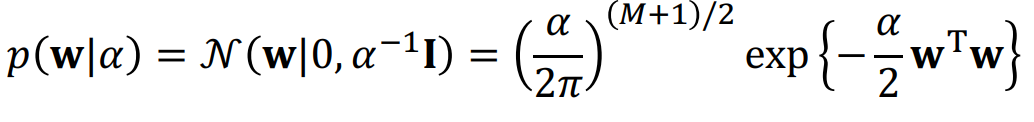
따라서 Posterior를 최대화 함으로써 w를 구하는 방식이다.
하지만 Posterior를 바로 구할 수 없기 때문에 다음과 같은 trick을 이용한다.
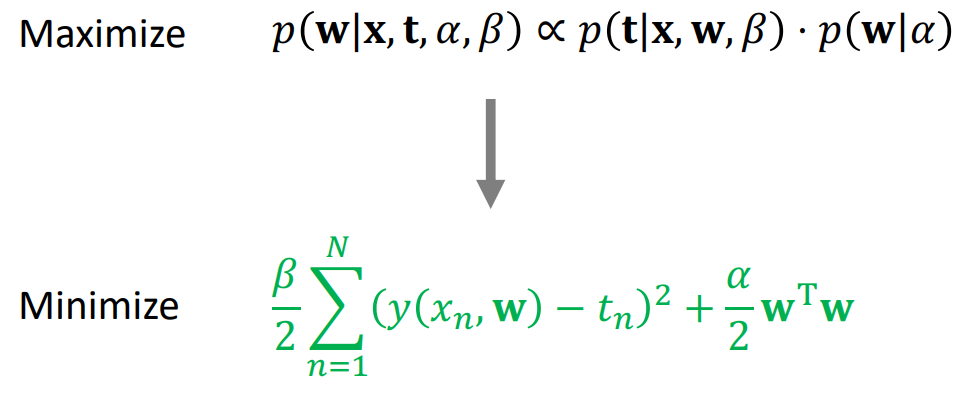
\( p(w|x,t, \alpha, \beta)는 Posterior를 말하고, p(t|x,w,\beta)는 Likelihood, p(w| \alpha )는 prior를 말한다. 따라서 Posterior는 Likelihood와 prior를 곱한 것에 비례한다. 이 때, likelihood 와 prior는 모두 gaussian distribtution을 따르고 이를 정리하면 다음과 같은 초록색 식이 도출된다.
이를 도출하는 상세한 과정은 생략한다.
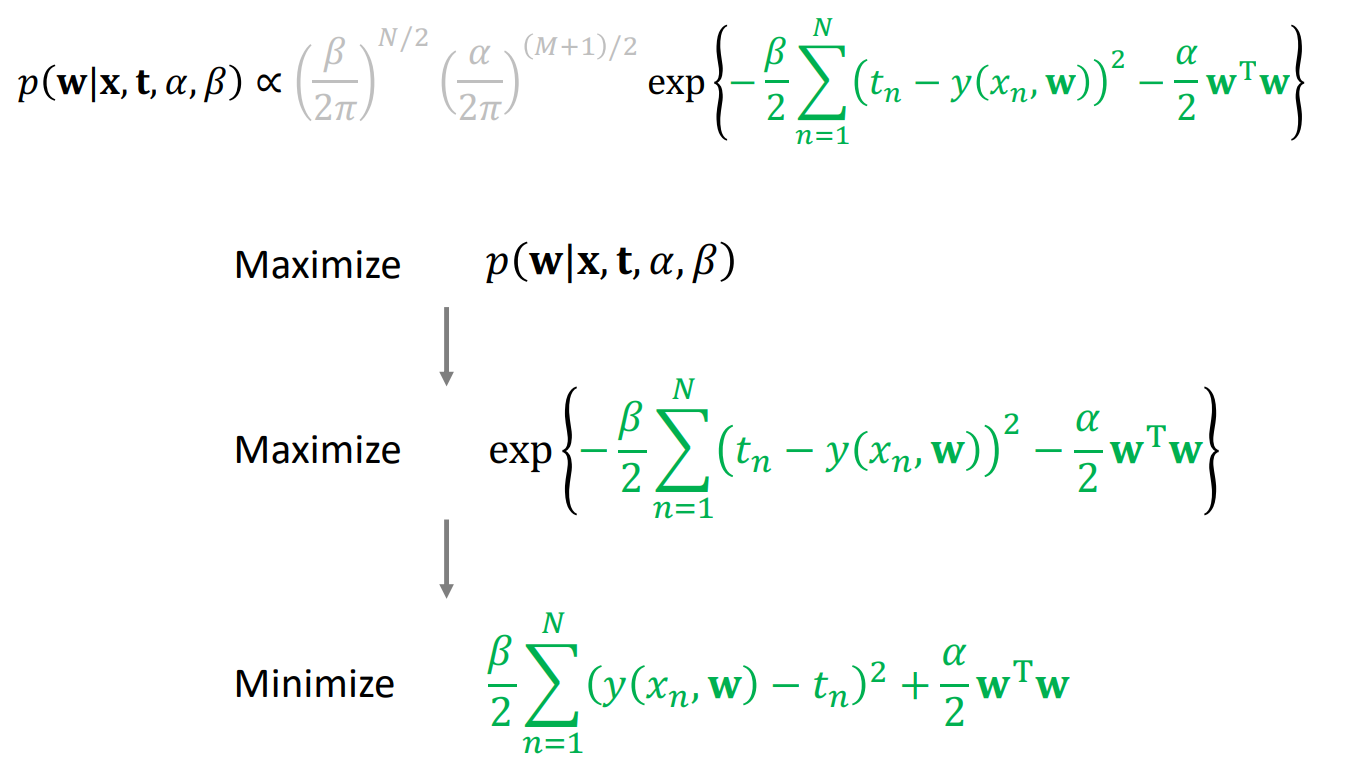
간단하게만 보면 이렇게 초록색식이 도출되는데, 회색으로 표시한 부분은 constant 이므로 무시하고 결국 초록색 식을 최적화 시켜야 된다.
이를 보면 Posterior를 최대화 하는 것은 -가 붙여진 초록색 식을 최대화 하는 것이고 이는 -를 제외한 초록색 식을 최소화 하는 것과 동일하다.
근데 이 초록색 식은 매우 어떤 것과 유사한데 바로 앞서 언급했던 Ridge loss와 유사한 것이다.
$$ E(w) = \frac{1}{2} \Sigma_{n=1}^{N} ( y(x_n , w) - t_n ) + \frac{ \lambda }{2} || w ||^{2} $$
물론 \( \alpha, \beta \)에 따라서 달라진다.
따라서 이러한 Baysian 방법은 Priror distribution을 Gaussian distribution 형태로 정함으로써 L2 regularization 을 가지는 Ridge loss와 유사한 형태를 띄게 되고 error minimize 방법과 유사하게 학습을 하는 것이다.
보통 사람들이 error를 최소화하여 모델을 학습한다라고 말하는 것은 Baysian 관점에 따라서 모델을 학습한다의 개념이 내포되어있는 것이다.
'Probability & Statistics' 카테고리의 다른 글
| Nonparametric method (0) | 2022.08.03 |
|---|---|
| Probability Distribution (0) | 2022.08.02 |
| Information Theory (0) | 2022.08.01 |
| Decision Theory (0) | 2022.08.01 |
| 확률분포 정리 (0) | 2022.07.17 |




댓글