https://arxiv.org/pdf/1907.10310.pdf
Arixv GPT
The paper "Towards Adversarially Robust Object Detection" proposes an adversarial training approach to improve the robustness of object detection models against adversarial attacks, and verifies its effectiveness through extensive experiments on PASCAL-VOC and MS-COCO datasets.
Key insights and lessons learned:
- Object detection models are vulnerable to adversarial attacks, and improving their robustness is crucial for practical applications.
- Multi-task learning can be used to improve object detection robustness by leveraging the asymmetric role of task losses.
- Adversarial training is an effective approach to improve object detection robustness against multiple sources of attacks.
Questions for the authors:
- What are the potential limitations of the proposed adversarial training approach?
- How does the proposed approach compare to other methods for improving the robustness of object detection models?
- Can the proposed approach be applied to other computer vision tasks besides object detection?
- How do different sources of attacks affect the robustness of object detection models?
- What are the implications of this work for practical applications of object detection models?
Suggestions for future research:
- Investigate the transferability of adversarial attacks and defenses across different object detection models and datasets.
- Explore the impact of different hyperparameters on the effectiveness of adversarial training for object detection.
- Study the generalization and interpretability of object detection models under adversarial attacks.
- Develop defenses against more sophisticated adversarial attacks, such as those based on physical perturbations.
- Investigate the role of model architectures and training data in the robustness of object detection models.
논문 "Adversarially Robust Object Detection을 향하여"은 적대적 공격에 대한 물체 감지 모델의 견고성을 향상시키기 위한 적대적 훈련 접근법을 제안하고, PASCAL-VOC 및 MS-COCO 데이터셋에서 광범위한 실험을 통해 그 효과를 검증합니다.
주요 인사이트 및 배운 교훈:
- 물체 감지 모델은 적대적 공격에 취약하며, 견고성을 향상시키는 것이 실제 응용 분야에 중요합니다.
- 다중 작업 학습은 작업 손실의 비대칭적 역할을 활용하여 물체 감지 견고성을 향상시키는 데 사용될 수 있습니다.
- 적대적 훈련은 다양한 공격 원천에 대한 물체 감지 모델의 견고성을 향상시키는 효과적인 접근법입니다.
저자들에게 묻는 질문:
- 제안된 적대적 훈련 접근법의 잠재적인 한계는 무엇인가요?
- 제안된 접근법은 물체 감지 모델의 견고성을 향상시키기 위한 다른 방법들과 비교했을 때 어떤 차이가 있나요?
- 제안된 접근법은 물체 감지 외의 다른 컴퓨터 비전 작업에도 적용할 수 있나요?
- 다른 공격 원천이 물체 감지 모델의 견고성에 어떤 영향을 미치나요?
- 이 작업이 물체 감지 모델의 실제 응용 분야에 미치는 영향은 무엇인가요?
미래 연구를 위한 제안:
- 다른 물체 감지 모델 및 데이터셋 간 적대적 공격 및 방어의 이식 가능성 조사
- 적대적 훈련의 효과를 물체 감지에 대한 다양한 하이퍼파라미터에 대한 탐구
- 적대적 공격에 대한 물체 감지 모델의 일반화 및 해석 가능성 연구
- 물리적 왜곡을 기반으로 한 더 정교한 적대적 공격에 대한 방어 개발
- 모델 아키텍처와 훈련 데이터가 물체 감지 모델의 견고

본 논문에선 다양한 유형의 공격에 대한 object detection의 robustness 를 향상시키는 것이 가능하며 adversarial training으로 생성하여 이를 실용적으로 쓸 수 있는 방법 제안
Contribution
1. object detector에 대한 다양한 공격들을 분류하고 카테고리화 하여 공유된 기본 메커니즘을 밝힌다.
2. 다른 task 의 loss와 그것들의 견고성 사이의 interaction을 밝히고 분석한다.
3. 우리는 adersarial training framework를 분류 task에서 detection task로 일반화시켰고, object detection의 task loss 간의 interaction을 적절히 다룰 수 있는 adversarial training 을 발전시켰다.
Object Detection and Attack Revisited
Object Detection as Multi-Task Learning 파트에선 object detection 에 대한 전체적인 고찰을 진행. OD 같은 경우 loss는 classficiation 을 위한 loss 와 localization을 하기 위한 loss 가 따로 있음. 그러나 여기서 loss에 대한 성능은 독립적이라는 것을 밝힘. 이러한 디자인은 multi-task 의 한 종류라고 볼 수 있다.
Detection Attacks Guided by Task loss : 기존의 OD 모델 공격 방법은 결국 앞서 말했던 것 처럼 multi-task learning을 공격하는 기법들이다. 즉, OD를 공격하려면 각 task 에 대한 공격이나 두 task 모두 공격하면 된다 라는 것이다. 이러한 attack 기법이 효율적인 이유는 2가지로 분류가 되는데, 첫번째로 class task 와 localization task 는 model (=basenet) 을 공유하므로 모델의 약점은 모든 task 에 공유 된다는 것, 두번째로 두 task 는 분리되어있지만 결국 NMS 로 합쳐지기 때문에 이 또한 공격이 동시에 된다.
Towards Adversarially Robust Detection
The Roles of Task Losses in Robustness
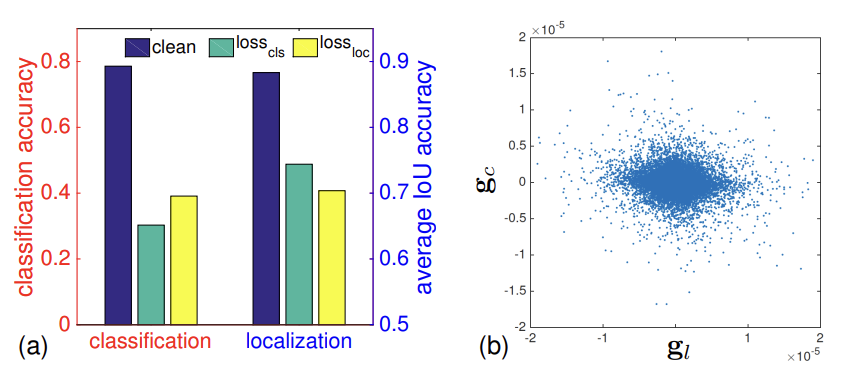
" 다른 task 상호작용을 갖고 있으며, 한 작업에 대한 adversarial attach 은 다른 task의 성능을 저하시킬 수 있다." 라는 첫번째 접근법을 소개한다. 이를 증명하기 위해 각 task 마다 하나씩 집중하여 실험을 하였다. 즉, classifcation factor 만 유지하고 local factor는 제외하고, local factor를 유지할 땐 classification factor 를 제외하는 실험이다. PGD attack 으로 정확도를 알아보았고, 이는 NMS 전의 성능으로 측정하였다. 이 결과 classification loss 와 localization loss를 각각 타겟으로 PGD Attack을 하였을 때 동시에 성능이 떨어지는 것을 볼 수 있었다, Figure 3-(a) 참고
Misaligned Task Gradients
본 논문의 두번째 observation은 " 두 task 의 gradient는 일부는 공통된 방향을 공유하지만 완전히 일치하지 않는다. 따라서 misaligned 된 task의 gradient가 발생하여 추후 adversarial learning을 혼란스럽게 할 수 있다." 라는 것이다. 이를 증명하기 위해 두 loss에서 파생된 이미지의 gradient 를 분석한다. 즉, \( \nabla_{x}loss_{cls} \) 와 \( \nabla_{x}loss_{loc}\) 의 값을 구하여 분석하는 것이다. 이에 대한 scatter plot 을 그려서 분석하여 각 task 의 gradient 크기가 같지 않고, 방향이 일관되지 않는다는 것을 보였다. Fig 3-(b) 참고
추가로 본 논문에선 task gradient domain 을 visualization 하여 분석하였고, 이는 두 도메인이 완전히 분리되어 있지는 않다라는 것을 밝혀내었다.
Adversarial Training for Robust Detection
이러한 분석 결과를 바탕으로, robust object detection training 을 위한 formulation 을 제안한다.
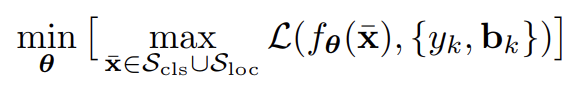
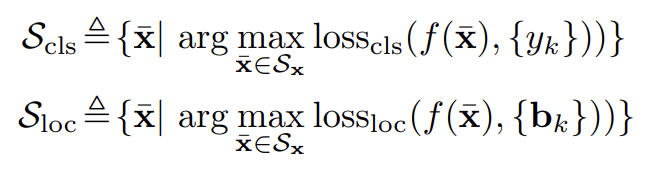
여기서 \( S_x = \{z | z \in B (x , \epsilon) \cap [0,255]^n \} \) 이고, \( B(x,\epsilon) = \{ z | \ || z - x ||_{\infty} \leq \epsilon \} \) 이다. 여기서 \( \epsilon \) 은 perturbation 이고, 체비셰프 거리 (infinity distance)는 clean 한 이미지에서의 반지름을 갖고 있는 공간이다 (adversarial attack 에서 반지름 정도로 방어가 되는 기법이 존재). 입력을 적절한 영역 \(S_x\) 로 projection 하는 \( P_{S_x} (\cdot) \) 을 정의하고, 이는 classificiation task 에서 적용되는 adversarial attack 과 다르다는 것을 본 논문에선 강조한다.
multi-task sources for adversary training : 하나의 class 에서만 target을 설정하는 기존 attack 방법과 달리 multiple object 에 관해서 그리고 heterogeneous ( classification and localization) 에 관해서 label 값을 주어 adversarial training 을 한다.
task-oriented domain constraints : task에 무관한 S_x 제약조건을 사용하는 일반적인 adversarial training setting 과 다르게 task-oriented domain contraint ( \( S_{cls} \cup S_{loc}\) )를 소개한다. 이는 classification 또는 localization loss 중 하나를 최대화 하는 이미지 집합으로 허용 가능한 domain 을 제한하는 것이다. 최종적인 final adversarial example은 이러한 집합에서 .전체적인 loss를 최대화 하는 것이다. 이로써 task-domain constraints을 갖춘 formulation 이 되고 이는 서로 task 에 대해 간섭하지 않는 이점을 얻을 수 있다.
그래서! original image 에 FGSM 에서 제안된 것 처럼 perturbation을 입히고, 그걸로 훈련을 하였다! 이게 핵심임.
결국!! FGSM 에서 사용하는 atack 방법을 각각 classification loss 와 localization loss 에 더해주어 attack 하였다!!!!!

논문 평가 : FGSM attack 을 한 것으로 훈련하였다인데, 이를 잘 증명해서 잘 풀어쓴 논문. 이 논문의 한계점은 single-stage 에서 밖에 안된다는 단점이 있는듯.
'논문 정리' 카테고리의 다른 글
| The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization (0) | 2023.03.21 |
|---|---|
| Improving Object Detection with Selective Self-Supervised Self-Training (0) | 2023.03.17 |
| Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming (0) | 2023.03.16 |
| Model Summary (NLP) (0) | 2023.03.15 |
| PFMs for Natural Language Processing (0) | 2023.03.14 |




댓글