https://arxiv.org/pdf/2007.09162.pdf
The paper proposes a novel learning method called selective self-supervised self-training to improve object detection by leveraging diverse Web images and rectifying the supervision signals in Web images using a selective net, achieving state-of-the-art results on detecting different object classes.
Key insights:
- Image-to-image search is an effective method for retrieving Web images that incur less domain shift from the curated data than other search methods.
- Leveraging Web images with self-supervised learning and self-training can improve object detection, but the domain gap between the Web images and curated datasets poses a challenge.
- A selective net can rectify the supervision signals in Web images and improve object detection by identifying positive bounding boxes and creating a safe zone for mining hard negative boxes.
- 본 논문은 unlabeld Web Image 를 이용하여 사람이 라벨링한 이미지를 보강하는 방법 제안 (특히, labeling 하기 애매한 class 에 대해서 (e.g. backpack, chair)
- self-supervised 와 self-training을 이용하여 Web 이미지를 object detection에 활용하기 좋은 방법을 제안
Contribution
1. Selective-Net으로 object detection을 위한 self-training 방법을 customizing. Selective Net은 양상 bounding box 를 식별하고 일부 negative box를 safety zone 에 할당하여 object detection 모델이 어려운 부정적인 샘플 마이닝을 방해하지 않도록 함.
2. consistency 기반의 semi-supervised object detection의 성능을 self-training framework 하에서 selective ent에 의해 성능을 향상시켰다.
3. unlabeled 이고 out-of-domain 의 웹 이미지들을 이용하여 정제된 object detection dataset에 보강한 최초의 작업이다.

Selective self-supervised self-training
모델의 이름은 \(S^4\) OD으로 Selective Self-Supervised Self-training for Object Detection 이다.
COCO dataset에서 객체의 한 클래스만 가지고 image -text (class) 쌍을 구성하였다. Web image 는 label 이 없기 때문에 text 없이 이미지로만 구성하였다. 그리고 coco dataset 보다 양이 많게 구성하였다.
Self-training for Ojbect Detection (SOD)
1. teachter object detector 에 COCO 이미지를 훈련.
2. unlabeled data에 pseudo box를 생성.
3. 생성한 pseudo box에 confidence 정보를 추가.
4. fine-tuning 하여 student detector를 학습시킨다. 이는 coco 로 이미 학습시킨 데이터로 unlabeled image에 대해 pseudo box를 찾을 수 있기 때문이다.
그리고 self-training 과정에서 pseudo box 를 걸러낼 때, confidence 가 0.7 이상인 애들만 선택.
Selective Self-training for Ojbect Detection (\(S^2\)OD
confidence 기반으로 thresholding 하였을 때, 문제점은 confidence와 IOU의 상관관계가 없다는 것이다. 그래서 SOD가 student detector가 학습하기 전에 bbox 를 지우는 상황이 발생한다.
따라서 이를 해결하기 위해, confidence를 보정하기 위한 select net을 제안한다. selective net의 main idea 는 positive, negative, ambiguity 로 grouping 하는 것이다. 그래서 positive box 로 예측된 것은 loss term 에서 활성화되고, selective net에 의해 맞지만 예측이 누락된 ambiguity 들은 safe zone 을 만들어서 loss 에 기여하지 않도록 한다. 이러한 safe zone 은 학습 알고리즘이 hard negative mining 기법을 가지고 있을 때 유용한데, 왜냐하면 이 ambiguity 그룹의 애들은 잠재적으로 hard negative 를 제외하기 때문이다.
Preparing training data for the seletive net
그러면 이러한 selective net 은 어떻게 훈련을 할까? 일단 2번 과정을 봐보자. teacher detector에서 pseudo box 를 생성한다. 여기서 pseudo box와 answer box 의 IOU를 구하고 이에 대한 thresholding 값을 정해서 분류한다. 즉,
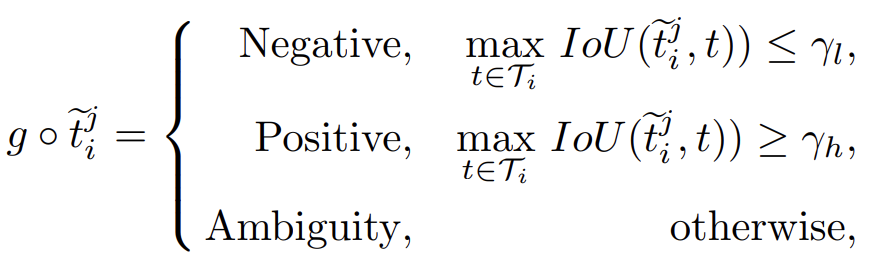
이런 식으로 IOU 값이 \( \gamma \) 보다 크면 positive, 작으면 negative 로 설정하는 것이다. 본 논문에선 \( \gamma_{l}\) 을 0.05, \( \gamma_h \)는 0.6 으로 설정하였다. 그 외 나머지는 ambiguity로 남긴다. 이렇게 계산하면 label IOU 보다 mAP가 높게 나오게 된다.
Preparing features for the seletive net
잠재적으로 유용한 특징들을 축적하여 pseduo box 를 표현하는데 사용되며 이는 selective net이 box를 grouping 하게 충분한 정보를 준다. 다음은 i 번째 이미지 box t 에 대한 feature 들이다,
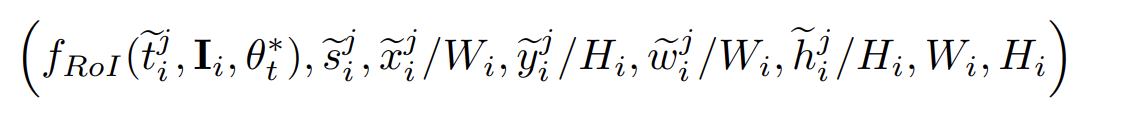
function ROI는 teacher detector에서 얻은 ROI-pooled feature 들이고, s 는 confidence score를 말한다. 여기서 tilde 되어있는 것들은 모두 web image를 말한다. W 와 H 는 이미지의 width, height 를 말한다.
Training the selective net
3-way cross entropy loss 를 갖고 straight-forward 모델을 훈련하였따. 이는 두가지 부분으로 구성이 되었는데, normalized ROI pooling feature 와 다른 부분은 remaining box feature 를 encoding 한 부분이다. 이걸 코드로 나타내자면
import torch.nn as nn
ROI_pooled = nn.Linear(512, 128)
encoding = nn.Linear(512, 128)
classifier = nn.Linear(256, 3)
x1 = ROI_pooled(input)
x2 = encoding(input)
x = torch.cat((x1, x2), dim=1)
y = classifier(x)여기서 문제는 overfitting 이 될 수 있다라는 우려가 있는데, 하지만 bounding box에 대해 일관성이 없기 때문에 detector 가 학습 데이터셋에 overfitting 이 거의 될 수가 없다. 따라서 이러한 방법을 통해 이는 average rater 가 된다.
Selective Self-Supervised self-training Object Detection (\(S^{4}\)OD)
S2OD에 기존에 제안된 두가지 loss function을 추가하여 unlabeled image에 대한 loss 항을 완성시킨다.
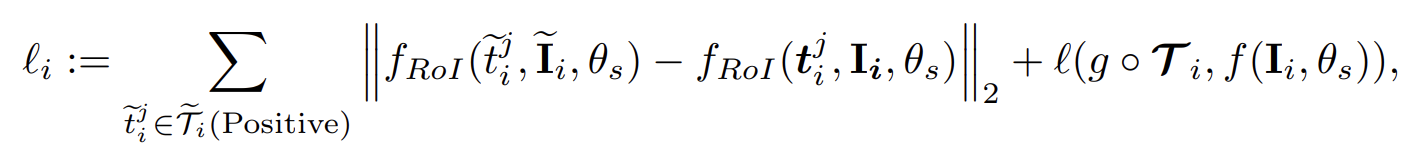
기존에 제안된 consistency term을 추가시킨 것이다. 이것들은 pusedo box에 대한 추가적인 단서로써, 이러한 추가적인 지도를 통해 student detector 가 teacher detector를 능가할 수 있도록 한다.
마지막으로 noisy Web Image 가 주어지면, selective net 은 positive box를 선택하고, 그리고 loss 가 일정 값을 넘지않게 제한을 둔다. 또한, Web image 를 랜덤하게 image processing (e.g. rotation, flip mcrop ) 을 해주어 pseudo box를 추가적으로 얻을 수 있게 만들었다
'논문 정리' 카테고리의 다른 글
| Zero-Shot Contrastive Loss for Text-Guided Diffusion Image Style Transfer (0) | 2023.04.26 |
|---|---|
| The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization (0) | 2023.03.21 |
| Towards Adversarially Robust Object Detection (0) | 2023.03.16 |
| Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming (0) | 2023.03.16 |
| Model Summary (NLP) (0) | 2023.03.15 |




댓글